 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Towards Zero-Shot Multimodal Machine Translation
Jul 18, 2024Current multimodal machine translation (MMT) systems rely on fully supervised data (i.e models are trained on sentences with their translations and accompanying images). However, this type of data is costly to collect, limiting the extension of MMT to other language pairs for which such data does not exist. In this work, we propose a method to bypass the need for fully supervised data to train MMT systems, using multimodal English data only. Our method, called ZeroMMT, consists in adapting a strong text-only machine translation (MT) model by training it on a mixture of two objectives: visually conditioned masked language modelling and the Kullback-Leibler divergence between the original and new MMT outputs. We evaluate on standard MMT benchmarks and the recently released CoMMuTE, a contrastive benchmark aiming to evaluate how well models use images to disambiguate English sentences. We obtain disambiguation performance close to state-of-the-art MMT models trained additionally on fully supervised examples. To prove that our method generalizes to languages with no fully supervised training data available, we extend the CoMMuTE evaluation dataset to three new languages: Arabic, Russian and Chinese. We further show that we can control the trade-off between disambiguation capabilities and translation fidelity at inference time using classifier-free guidance and without any additional data. Our code, data and trained models are publicly accessible.
mOSCAR: A Large-scale Multilingual and Multimodal Document-level Corpus
Jun 13, 2024



Multimodal Large Language Models (mLLMs) are trained on a large amount of text-image data. While most mLLMs are trained on caption-like data only, Alayrac et al. [2022] showed that additionally training them on interleaved sequences of text and images can lead to the emergence of in-context learning capabilities. However, the dataset they used, M3W, is not public and is only in English. There have been attempts to reproduce their results but the released datasets are English-only. In contrast, current multilingual and multimodal datasets are either composed of caption-like only or medium-scale or fully private data. This limits mLLM research for the 7,000 other languages spoken in the world. We therefore introduce mOSCAR, to the best of our knowledge the first large-scale multilingual and multimodal document corpus crawled from the web. It covers 163 languages, 315M documents, 214B tokens and 1.2B images. We carefully conduct a set of filtering and evaluation steps to make sure mOSCAR is sufficiently safe, diverse and of good quality. We additionally train two types of multilingual model to prove the benefits of mOSCAR: (1) a model trained on a subset of mOSCAR and captioning data and (2) a model train on captioning data only. The model additionally trained on mOSCAR shows a strong boost in few-shot learning performance across various multilingual image-text tasks and benchmarks, confirming previous findings for English-only mLLMs.
MAD Speech: Measures of Acoustic Diversity of Speech
Apr 16, 2024



Generative spoken language models produce speech in a wide range of voices, prosody, and recording conditions, seemingly approaching the diversity of natural speech. However, the extent to which generated speech is acoustically diverse remains unclear due to a lack of appropriate metrics. We address this gap by developing lightweight metrics of acoustic diversity, which we collectively refer to as MAD Speech. We focus on measuring five facets of acoustic diversity: voice, gender, emotion, accent, and background noise. We construct the metrics as a composition of specialized, per-facet embedding models and an aggregation function that measures diversity within the embedding space. Next, we build a series of datasets with a priori known diversity preferences for each facet. Using these datasets, we demonstrate that our proposed metrics achieve a stronger agreement with the ground-truth diversity than baselines. Finally, we showcase the applicability of our proposed metrics across several real-life evaluation scenarios. MAD Speech will be made publicly accessible.
Tackling Ambiguity with Images: Improved Multimodal Machine Translation and Contrastive Evaluation
Dec 20, 2022


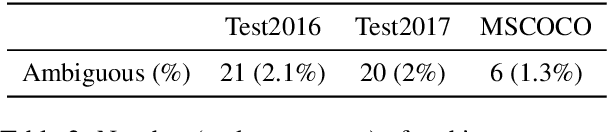
One of the major challenges of machine translation (MT) is ambiguity, which can in some cases be resolved by accompanying context such as an image. However, recent work in multimodal MT (MMT) has shown that obtaining improvements from images is challenging, limited not only by the difficulty of building effective cross-modal representations but also by the lack of specific evaluation and training data. We present a new MMT approach based on a strong text-only MT model, which uses neural adapters and a novel guided self-attention mechanism and which is jointly trained on both visual masking and MMT. We also release CoMMuTE, a Contrastive Multilingual Multimodal Translation Evaluation dataset, composed of ambiguous sentences and their possible translations, accompanied by disambiguating images corresponding to each translation. Our approach obtains competitive results over strong text-only models on standard English-to-French benchmarks and outperforms these baselines and state-of-the-art MMT systems with a large margin on our contrastive test set.