 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling Ambiguity with Images: Improved Multimodal Machine Translation and Contrastive Evaluation
Paper and Code



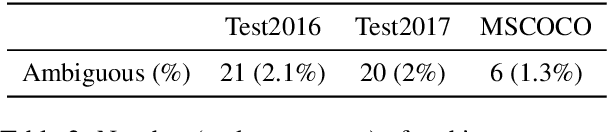
One of the major challenges of machine translation (MT) is ambiguity, which can in some cases be resolved by accompanying context such as an image. However, recent work in multimodal MT (MMT) has shown that obtaining improvements from images is challenging, limited not only by the difficulty of building effective cross-modal representations but also by the lack of specific evaluation and training data. We present a new MMT approach based on a strong text-only MT model, which uses neural adapters and a novel guided self-attention mechanism and which is jointly trained on both visual masking and MMT. We also release CoMMuTE, a Contrastive Multilingual Multimodal Translation Evaluation dataset, composed of ambiguous sentences and their possible translations, accompanied by disambiguating images corresponding to each translation. Our approach obtains competitive results over strong text-only models on standard English-to-French benchmarks and outperforms these baselines and state-of-the-art MMT systems with a large margin on our contrastive test set.