 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Harmonic Structure of Information Contours
Jun 04, 2025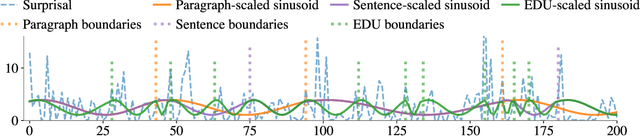
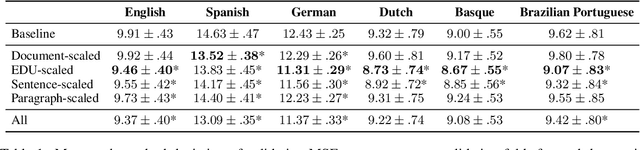
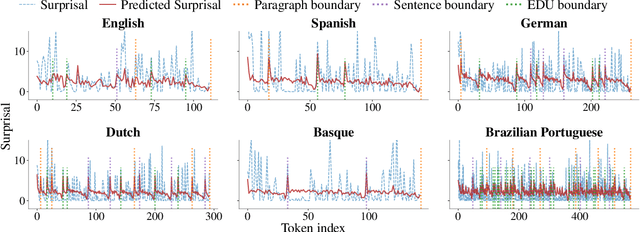
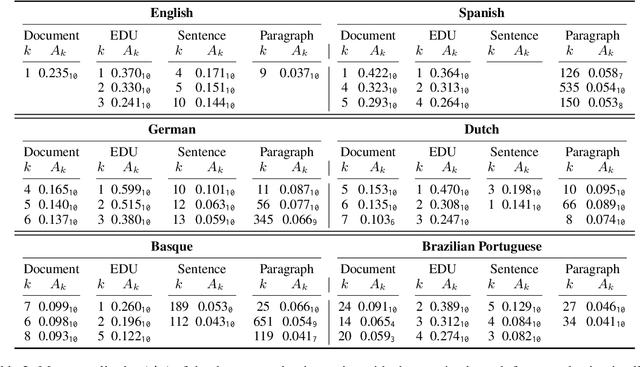
The uniform information density (UID) hypothesis proposes that speakers aim to distribute information evenly throughout a text, balancing production effort and listener comprehension difficulty. However, language typically does not maintain a strictly uniform information rate; instead, it fluctuates around a global average. These fluctuations are often explained by factors such as syntactic constraints, stylistic choices, or audience design. In this work, we explore an alternative perspective: that these fluctuations may be influenced by an implicit linguistic pressure towards periodicity, where the information rate oscillates at regular intervals, potentially across multiple frequencies simultaneously. We apply harmonic regression and introduce a novel extension called time scaling to detect and test for such periodicity in information contours. Analyzing texts in English, Spanish, German, Dutch, Basque, and Brazilian Portuguese, we find consistent evidence of periodic patterns in information rate. Many dominant frequencies align with discourse structure, suggesting these oscillations reflect meaningful linguistic organization. Beyond highlighting the connection between information rate and discourse structure, our approach offers a general framework for uncovering structural pressures at various levels of linguistic granularity.
Surprise! Uniform Information Density Isn't the Whole Story: Predicting Surprisal Contours in Long-form Discourse
Oct 21, 2024



The Uniform Information Density (UID) hypothesis posits that speakers tend to distribute information evenly across linguistic units to achieve efficient communication. Of course, information rate in texts and discourses is not perfectly uniform. While these fluctuations can be viewed as theoretically uninteresting noise on top of a uniform target, another explanation is that UID is not the only functional pressure regulating information content in a language. Speakers may also seek to maintain interest, adhere to writing conventions, and build compelling arguments. In this paper, we propose one such functional pressure; namely that speakers modulate information rate based on location within a hierarchically-structured model of discourse. We term this the Structured Context Hypothesis and test it by predicting the surprisal contours of naturally occurring discourses extracted from large language models using predictors derived from discourse structure. We find that hierarchical predictors are significant predictors of a discourse's information contour and that deeply nested hierarchical predictors are more predictive than shallow ones. This work takes an initial step beyond UID to propose testable hypotheses for why the information rate fluctuates in predictable ways
An Exploration of Left-Corner Transformations
Nov 27, 2023



The left-corner transformation (Rosenkrantz and Lewis, 1970) is used to remove left recursion from context-free grammars, which is an important step towards making the grammar parsable top-down with simple techniques. This paper generalizes prior left-corner transformations to support semiring-weighted production rules and to provide finer-grained control over which left corners may be moved. Our generalized left-corner transformation (GLCT) arose from unifying the left-corner transformation and speculation transformation (Eisner and Blatz, 2007), originally for logic programming. Our new transformation and speculation define equivalent weighted languages. Yet, their derivation trees are structurally different in an important way: GLCT replaces left recursion with right recursion, and speculation does not. We also provide several technical results regarding the formal relationships between the outputs of GLCT, speculation, and the original grammar. Lastly, we empirically investigate the efficiency of GLCT for left-recursion elimination from grammars of nine languages.
Generating Animations from Screenplays
Apr 10, 2019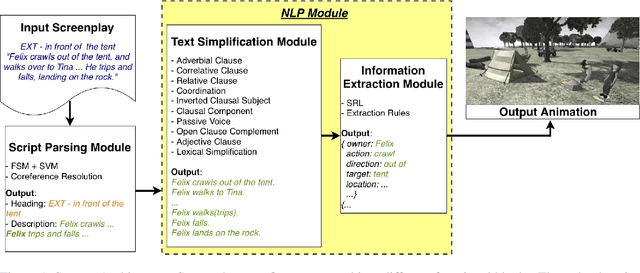

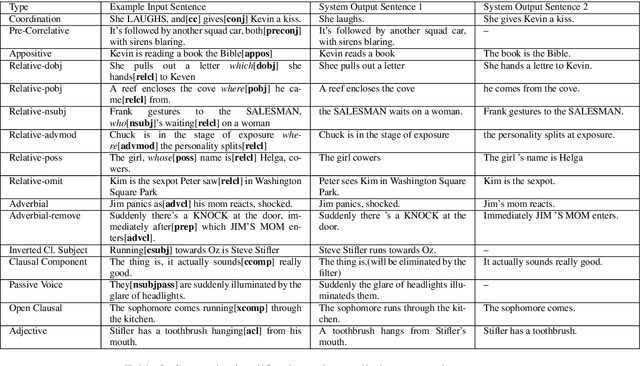
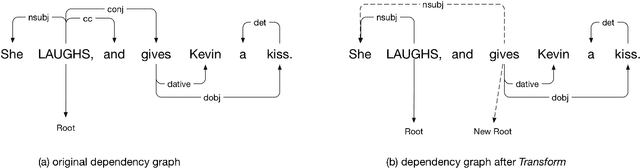
Automatically generating animation from natural language text finds application in a number of areas e.g. movie script writing, instructional videos, and public safety. However, translating natural language text into animation is a challenging task. Existing text-to-animation systems can handle only very simple sentences, which limits their applications. In this paper, we develop a text-to-animation system which is capable of handling complex sentences. We achieve this by introducing a text simplification step into the process. Building on an existing animation generation system for screenwriting, we create a robust NLP pipeline to extract information from screenplays and map them to the system's knowledge base. We develop a set of linguistic transformation rules that simplify complex sentences. Information extracted from the simplified sentences is used to generate a rough storyboard and video depicting the text. Our sentence simplification module outperforms existing systems in terms of BLEU and SARI metrics.We further evaluated our system via a user study: 68 % participants believe that our system generates reasonable animation from input screenplays.