 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Multi-Stack Slice-to-Volume Reconstruction via Multi-Scale Unrolled Optimization
Jan 12, 2026Fully convolutional networks have become the backbone of modern medical imaging due to their ability to learn multi-scale representations and perform end-to-end inference. Yet their potential for slice-to-volume reconstruction (SVR), the task of jointly estimating 3D anatomy and slice poses from misaligned 2D acquisitions, remains underexplored. We introduce a fast convolutional framework that fuses multiple orthogonal 2D slice stacks to recover coherent 3D structure and refines slice alignment through lightweight model-based optimization. Applied to fetal brain MRI, our approach reconstructs high-quality 3D volumes in under 10s, with 1s slice registration and accuracy on par with state-of-the-art iterative SVR pipelines, offering more than speedup. The framework uses non-rigid displacement fields to represent transformations, generalizing to other SVR problems like fetal body and placental MRI. Additionally, the fast inference time paves the way for real-time, scanner-side volumetric feedback during MRI acquisition.
FetalDiffusion: Pose-Controllable 3D Fetal MRI Synthesis with Conditional Diffusion Model
Mar 29, 2024The quality of fetal MRI is significantly affected by unpredictable and substantial fetal motion, leading to the introduction of artifacts even when fast acquisition sequences are employed. The development of 3D real-time fetal pose estimation approaches on volumetric EPI fetal MRI opens up a promising avenue for fetal motion monitoring and prediction. Challenges arise in fetal pose estimation due to limited number of real scanned fetal MR training images, hindering model generalization when the acquired fetal MRI lacks adequate pose. In this study, we introduce FetalDiffusion, a novel approach utilizing a conditional diffusion model to generate 3D synthetic fetal MRI with controllable pose. Additionally, an auxiliary pose-level loss is adopted to enhance model performance. Our work demonstrates the success of this proposed model by producing high-quality synthetic fetal MRI images with accurate and recognizable fetal poses, comparing favorably with in-vivo real fetal MRI. Furthermore, we show that the integration of synthetic fetal MR images enhances the fetal pose estimation model's performance, particularly when the number of available real scanned data is limited resulting in 15.4% increase in PCK and 50.2% reduced in mean error. All experiments are done on a single 32GB V100 GPU. Our method holds promise for improving real-time tracking models, thereby addressing fetal motion issues more effectively.
Zero-Shot Self-Supervised Joint Temporal Image and Sensitivity Map Reconstruction via Linear Latent Space
Mar 03, 2023



Fast spin-echo (FSE) pulse sequences for Magnetic Resonance Imaging (MRI) offer important imaging contrast in clinically feasible scan times. T2-shuffling is widely used to resolve temporal signal dynamics in FSE acquisitions by exploiting temporal correlations via linear latent space and a predefined regularizer. However, predefined regularizers fail to exploit the incoherence especially for 2D acquisitions.Recent self-supervised learning methods achieve high-fidelity reconstructions by learning a regularizer from undersampled data without a standard supervised training data set. In this work, we propose a novel approach that utilizes a self supervised learning framework to learn a regularizer constrained on a linear latent space which improves time-resolved FSE images reconstruction quality. Additionally, in regimes without groundtruth sensitivity maps, we propose joint estimation of coil-sensitivity maps using an iterative reconstruction technique. Our technique functions is in a zero-shot fashion, as it only utilizes data from a single scan of highly undersampled time series images. We perform experiments on simulated and retrospective in-vivo data to evaluate the performance of the proposed zero-shot learning method for temporal FSE reconstruction. The results demonstrate the success of our proposed method where NMSE and SSIM are significantly increased and the artifacts are reduced.
Data Consistent Deep Rigid MRI Motion Correction
Jan 25, 2023



Motion artifacts are a pervasive problem in MRI, leading to misdiagnosis or mischaracterization in population-level imaging studies. Current retrospective rigid intra-slice motion correction techniques jointly optimize estimates of the image and the motion parameters. In this paper, we use a deep network to reduce the joint image-motion parameter search to a search over rigid motion parameters alone. Our network produces a reconstruction as a function of two inputs: corrupted k-space data and motion parameters. We train the network using simulated, motion-corrupted k-space data generated from known motion parameters. At test-time, we estimate unknown motion parameters by minimizing a data consistency loss between the motion parameters, the network-based image reconstruction given those parameters, and the acquired measurements. Intra-slice motion correction experiments on simulated and realistic 2D fast spin echo brain MRI achieve high reconstruction fidelity while retaining the benefits of explicit data consistency-based optimization. Our code is publicly available at https://www.github.com/nalinimsingh/neuroMoCo.
Latent Signal Models: Learning Compact Representations of Signal Evolution for Improved Time-Resolved, Multi-contrast MRI
Aug 27, 2022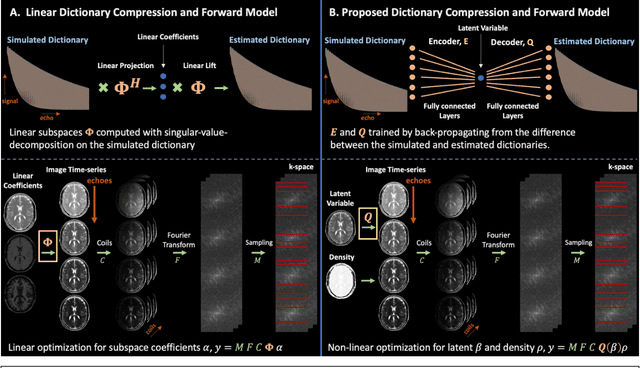
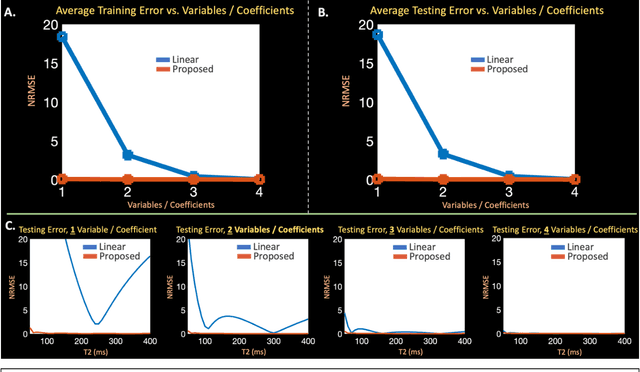
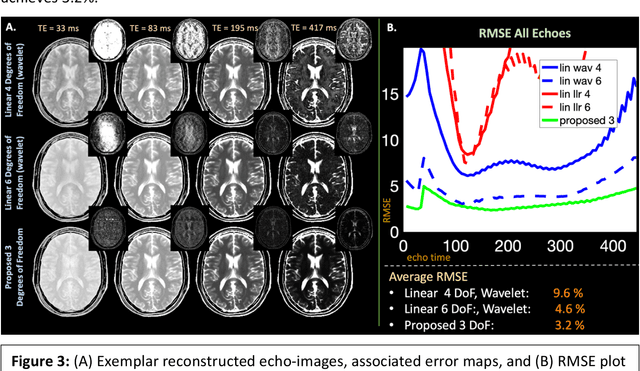
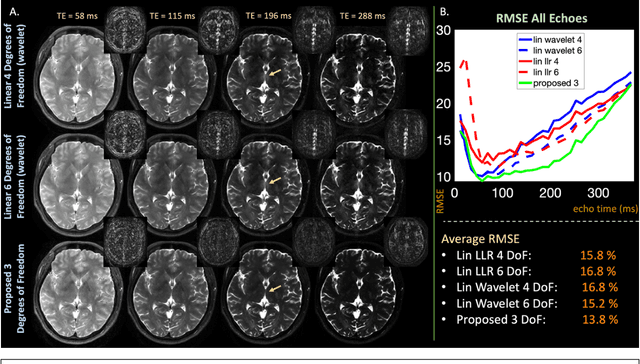
Purpose: Training auto-encoders on simulated signal evolution and inserting the decoder into the forward model improves reconstructions through more compact, Bloch-equation-based representations of signal in comparison to linear subspaces. Methods: Building on model-based nonlinear and linear subspace techniques that enable reconstruction of signal dynamics, we train auto-encoders on dictionaries of simulated signal evolution to learn more compact, non-linear, latent representations. The proposed Latent Signal Model framework inserts the decoder portion of the auto-encoder into the forward model and directly reconstructs the latent representation. Latent Signal Models essentially serve as a proxy for fast and feasible differentiation through the Bloch-equations used to simulate signal. This work performs experiments in the context of T2-shuffling, gradient echo EPTI, and MPRAGE-shuffling. We compare how efficiently auto-encoders represent signal evolution in comparison to linear subspaces. Simulation and in-vivo experiments then evaluate if reducing degrees of freedom by inserting the decoder into the forward model improves reconstructions in comparison to subspace constraints. Results: An auto-encoder with one real latent variable represents FSE, EPTI, and MPRAGE signal evolution as well as linear subspaces characterized by four basis vectors. In simulated/in-vivo T2-shuffling and in-vivo EPTI experiments, the proposed framework achieves consistent quantitative NRMSE and qualitative improvement over linear approaches. From qualitative evaluation, the proposed approach yields images with reduced blurring and noise amplification in MPRAGE shuffling experiments. Conclusion: Directly solving for non-linear latent representations of signal evolution improves time-resolved MRI reconstructions through reduced degrees of freedom.
SVoRT: Iterative Transformer for Slice-to-Volume Registration in Fetal Brain MRI
Jun 22, 2022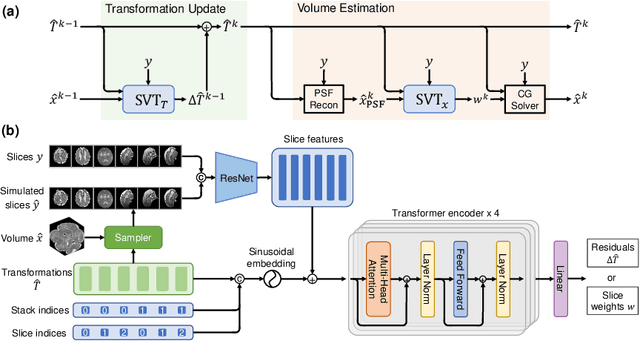
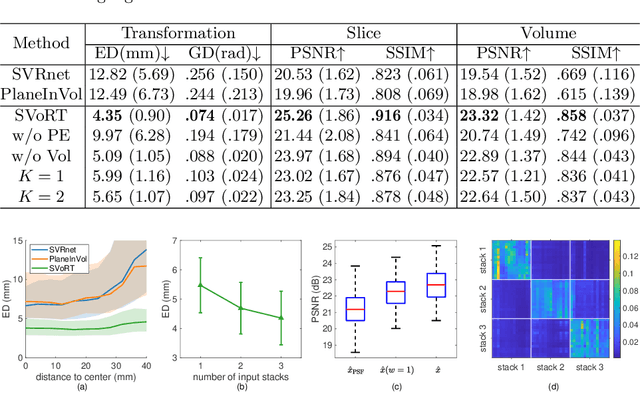


Volumetric reconstruction of fetal brains from multiple stacks of MR slices, acquired in the presence of almost unpredictable and often severe subject motion, is a challenging task that is highly sensitive to the initialization of slice-to-volume transformations. We propose a novel slice-to-volume registration method using Transformers trained on synthetically transformed data, which model multiple stacks of MR slices as a sequence. With the attention mechanism, our model automatically detects the relevance between slices and predicts the transformation of one slice using information from other slices. We also estimate the underlying 3D volume to assist slice-to-volume registration and update the volume and transformations alternately to improve accuracy. Results on synthetic data show that our method achieves lower registration error and better reconstruction quality compared with existing state-of-the-art methods. Experiments with real-world MRI data are also performed to demonstrate the ability of the proposed model to improve the quality of 3D reconstruction under severe fetal motion.
Autofocusing+: Noise-Resilient Motion Correction in Magnetic Resonance Imaging
Mar 10, 2022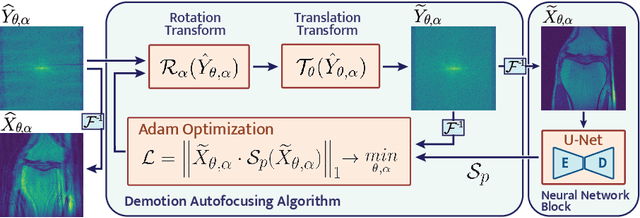
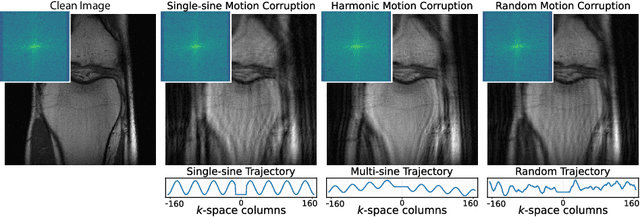
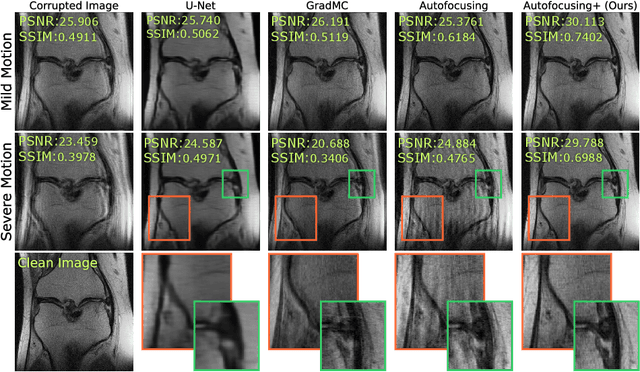
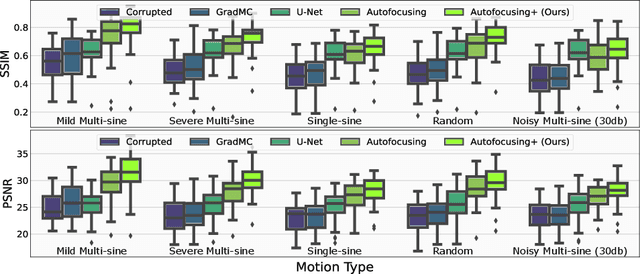
Image corruption by motion artifacts is an ingrained problem in Magnetic Resonance Imaging (MRI). In this work, we propose a neural network-based regularization term to enhance Autofocusing, a classic optimization-based method to remove motion artifacts. The method takes the best of both worlds: the optimization-based routine iteratively executes the blind demotion and deep learning-based prior penalizes for unrealistic restorations and speeds up the convergence. We validate the method on three models of motion trajectories, using synthetic and real noisy data. The method proves resilient to noise and anatomic structure variation, outperforming the state-of-the-art demotion methods.
Rapid head-pose detection for automated slice prescription of fetal-brain MRI
Oct 08, 2021In fetal-brain MRI, head-pose changes between prescription and acquisition present a challenge to obtaining the standard sagittal, coronal and axial views essential to clinical assessment. As motion limits acquisitions to thick slices that preclude retrospective resampling, technologists repeat ~55-second stack-of-slices scans (HASTE) with incrementally reoriented field of view numerous times, deducing the head pose from previous stacks. To address this inefficient workflow, we propose a robust head-pose detection algorithm using full-uterus scout scans (EPI) which take ~5 seconds to acquire. Our ~2-second procedure automatically locates the fetal brain and eyes, which we derive from maximally stable extremal regions (MSERs). The success rate of the method exceeds 94% in the third trimester, outperforming a trained technologist by up to 20%. The pipeline may be used to automatically orient the anatomical sequence, removing the need to estimate the head pose from 2D views and reducing delays during which motion can occur.
* 19 pages, 10 figures, 2 tables, fetal MRI, head-pose detection, MSER, scan automation, scan prescription, slice positioning, final published version
STRESS: Super-Resolution for Dynamic Fetal MRI using Self-Supervised Learning
Jun 30, 2021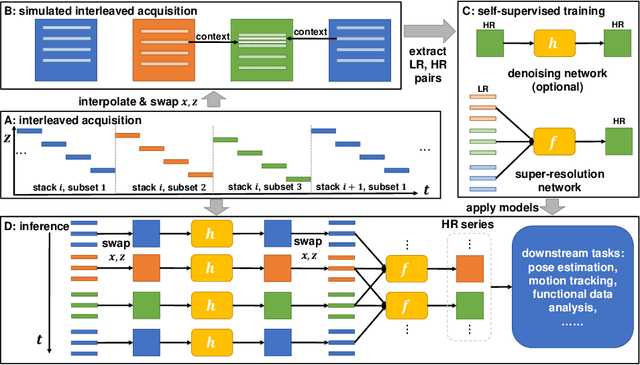
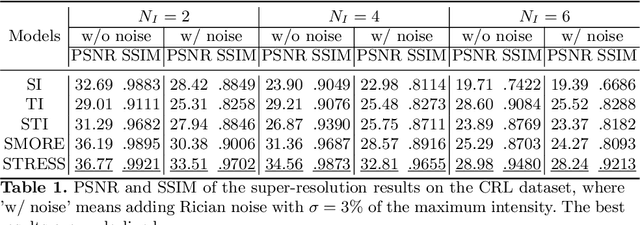


Fetal motion is unpredictable and rapid on the scale of conventional MR scan times. Therefore, dynamic fetal MRI, which aims at capturing fetal motion and dynamics of fetal function, is limited to fast imaging techniques with compromises in image quality and resolution. Super-resolution for dynamic fetal MRI is still a challenge, especially when multi-oriented stacks of image slices for oversampling are not available and high temporal resolution for recording the dynamics of the fetus or placenta is desired. Further, fetal motion makes it difficult to acquire high-resolution images for supervised learning methods. To address this problem, in this work, we propose STRESS (Spatio-Temporal Resolution Enhancement with Simulated Scans), a self-supervised super-resolution framework for dynamic fetal MRI with interleaved slice acquisitions. Our proposed method simulates an interleaved slice acquisition along the high-resolution axis on the originally acquired data to generate pairs of low- and high-resolution images. Then, it trains a super-resolution network by exploiting both spatial and temporal correlations in the MR time series, which is used to enhance the resolution of the original data. Evaluations on both simulated and in utero data show that our proposed method outperforms other self-supervised super-resolution methods and improves image quality, which is beneficial to other downstream tasks and evaluations.
Deformed2Self: Self-Supervised Denoising for Dynamic Medical Imaging
Jun 23, 2021

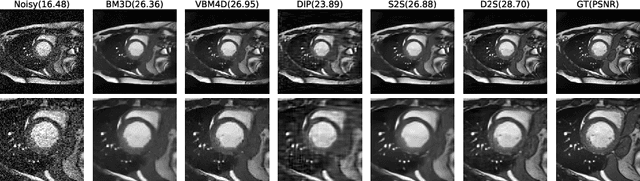

Image denoising is of great importance for medical imaging system, since it can improve image quality for disease diagnosis and downstream image analyses. In a variety of applications, dynamic imaging techniques are utilized to capture the time-varying features of the subject, where multiple images are acquired for the same subject at different time points. Although signal-to-noise ratio of each time frame is usually limited by the short acquisition time, the correlation among different time frames can be exploited to improve denoising results with shared information across time frames. With the success of neural networks in computer vision, supervised deep learning methods show prominent performance in single-image denoising, which rely on large datasets with clean-vs-noisy image pairs. Recently, several self-supervised deep denoising models have been proposed, achieving promising results without needing the pairwise ground truth of clean images. In the field of multi-image denoising, however, very few works have been done on extracting correlated information from multiple slices for denoising using self-supervised deep learning methods. In this work, we propose Deformed2Self, an end-to-end self-supervised deep learning framework for dynamic imaging denoising. It combines single-image and multi-image denoising to improve image quality and use a spatial transformer network to model motion between different slices. Further, it only requires a single noisy image with a few auxiliary observations at different time frames for training and inference. Evaluations on phantom and in vivo data with different noise statistics show that our method has comparable performance to other state-of-the-art unsupervised or self-supervised denoising methods and outperforms under high noise levels.