 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated MR Fingerprinting with Low-Rank and Generative Subspace Modeling
May 25, 2023



Magnetic Resonance (MR) Fingerprinting is an emerging multi-parametric quantitative MR imaging technique, for which image reconstruction methods utilizing low-rank and subspace constraints have achieved state-of-the-art performance. However, this class of methods often suffers from an ill-conditioned model-fitting issue, which degrades the performance as the data acquisition lengths become short and/or the signal-to-noise ratio becomes low. To address this problem, we present a new image reconstruction method for MR Fingerprinting, integrating low-rank and subspace modeling with a deep generative prior. Specifically, the proposed method captures the strong spatiotemporal correlation of contrast-weighted time-series images in MR Fingerprinting via a low-rank factorization. Further, it utilizes an untrained convolutional generative neural network to represent the spatial subspace of the low-rank model, while estimating the temporal subspace of the model from simulated magnetization evolutions generated based on spin physics. Here the architecture of the generative neural network serves as an effective regularizer for the ill-conditioned inverse problem without additional spatial training data that are often expensive to acquire. The proposed formulation results in a non-convex optimization problem, for which we develop an algorithm based on variable splitting and alternating direction method of multipliers.We evaluate the performance of the proposed method with numerical simulations and in vivo experiments and demonstrate that the proposed method outperforms the state-of-the-art low-rank and subspace reconstruction.
Rapid head-pose detection for automated slice prescription of fetal-brain MRI
Oct 08, 2021In fetal-brain MRI, head-pose changes between prescription and acquisition present a challenge to obtaining the standard sagittal, coronal and axial views essential to clinical assessment. As motion limits acquisitions to thick slices that preclude retrospective resampling, technologists repeat ~55-second stack-of-slices scans (HASTE) with incrementally reoriented field of view numerous times, deducing the head pose from previous stacks. To address this inefficient workflow, we propose a robust head-pose detection algorithm using full-uterus scout scans (EPI) which take ~5 seconds to acquire. Our ~2-second procedure automatically locates the fetal brain and eyes, which we derive from maximally stable extremal regions (MSERs). The success rate of the method exceeds 94% in the third trimester, outperforming a trained technologist by up to 20%. The pipeline may be used to automatically orient the anatomical sequence, removing the need to estimate the head pose from 2D views and reducing delays during which motion can occur.
* 19 pages, 10 figures, 2 tables, fetal MRI, head-pose detection, MSER, scan automation, scan prescription, slice positioning, final published version
Highly Accelerated Multishot EPI through Synergistic Combination of Machine Learning and Joint Reconstruction
Aug 08, 2018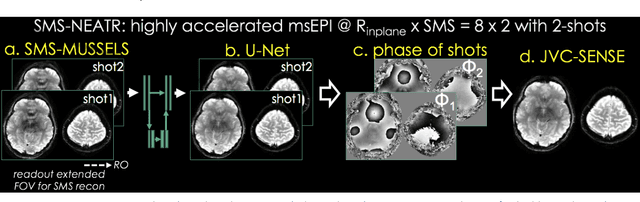
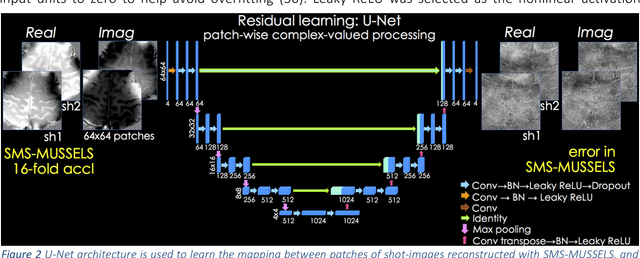
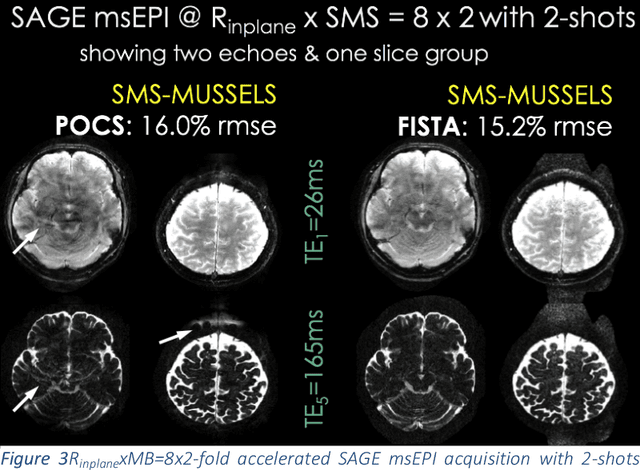
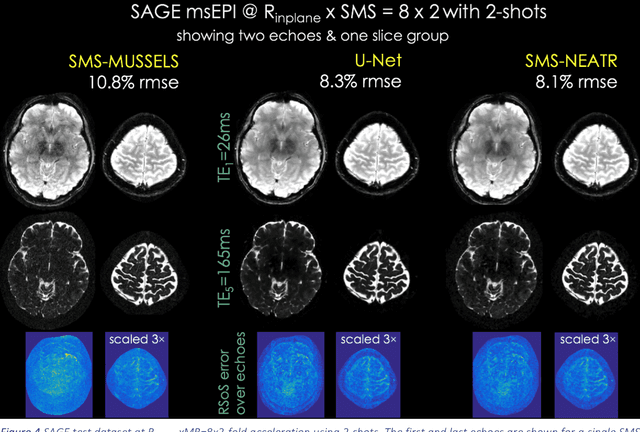
Purpose: To introduce a combined machine learning (ML) and physics-based image reconstruction framework that enables navigator-free, highly accelerated multishot echo planar imaging (msEPI), and demonstrate its application in high-resolution structural imaging. Methods: Singleshot EPI is an efficient encoding technique, but does not lend itself well to high-resolution imaging due to severe distortion artifacts and blurring. While msEPI can mitigate these artifacts, high-quality msEPI has been elusive because of phase mismatch arising from shot-to-shot physiological variations which disrupt the combination of the multiple-shot data into a single image. We employ Deep Learning to obtain an interim magnitude-valued image with minimal artifacts, which permits estimation of image phase variations due to shot-to-shot physiological changes. These variations are then included in a Joint Virtual Coil Sensitivity Encoding (JVC-SENSE) reconstruction to utilize data from all shots and improve upon the ML solution. Results: Our combined ML + physics approach enabled R=8-fold acceleration from 2 EPI-shots while providing 1.8-fold error reduction compared to the MUSSELS, a state-of-the-art reconstruction technique, which is also used as an input to our ML network. Using 3 shots allowed us to push the acceleration to R=10-fold, where we obtained a 1.7-fold error reduction over MUSSELS. Conclusion: Combination of ML and JVC-SENSE enabled navigator-free msEPI at higher accelerations than previously possible while using fewer shots, with reduced vulnerability to poor generalizability and poor acceptance of end-to-end ML approaches.