 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRNR: Training neural networks for Super-Resolution MRI using Noisy high-resolution Reference data
Nov 10, 2022Neural network (NN) based approaches for super-resolution MRI typically require high-SNR high-resolution reference data acquired in many subjects, which is time consuming and a barrier to feasible and accessible implementation. We propose to train NNs for Super-Resolution using Noisy Reference data (SRNR), leveraging the mechanism of the classic NN-based denoising method Noise2Noise. We systematically demonstrate that results from NNs trained using noisy and high-SNR references are similar for both simulated and empirical data. SRNR suggests a smaller number of repetitions of high-resolution reference data can be used to simplify the training data preparation for super-resolution MRI.
SDnDTI: Self-supervised deep learning-based denoising for diffusion tensor MRI
Nov 14, 2021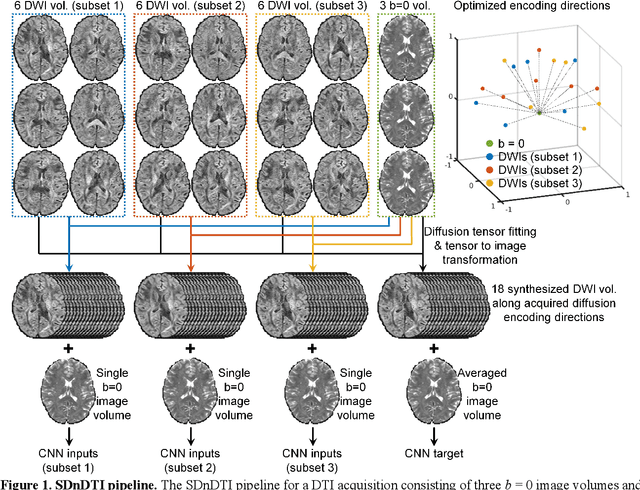
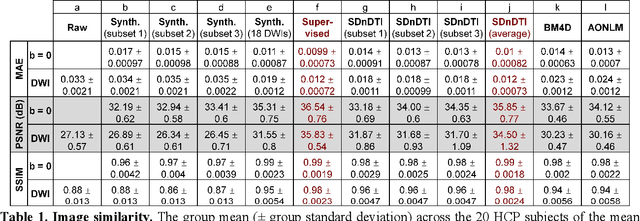
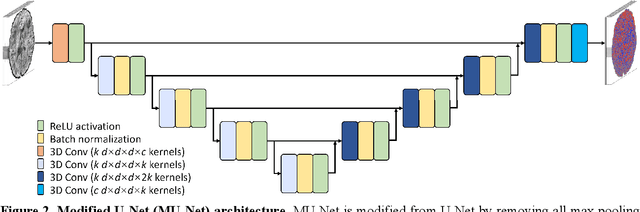
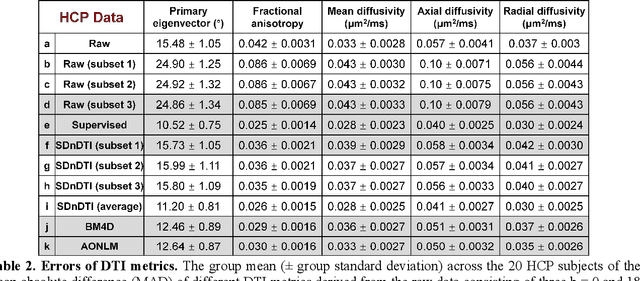
The noise in diffusion-weighted images (DWIs) decreases the accuracy and precision of diffusion tensor magnetic resonance imaging (DTI) derived microstructural parameters and leads to prolonged acquisition time for achieving improved signal-to-noise ratio (SNR). Deep learning-based image denoising using convolutional neural networks (CNNs) has superior performance but often requires additional high-SNR data for supervising the training of CNNs, which reduces the practical feasibility. We develop a self-supervised deep learning-based method entitled "SDnDTI" for denoising DTI data, which does not require additional high-SNR data for training. Specifically, SDnDTI divides multi-directional DTI data into many subsets, each consisting of six DWI volumes along optimally chosen diffusion-encoding directions that are robust to noise for the tensor fitting, and then synthesizes DWI volumes along all acquired directions from the diffusion tensors fitted using each subset of the data as the input data of CNNs. On the other hand, SDnDTI synthesizes DWI volumes along acquired diffusion-encoding directions with higher SNR from the diffusion tensors fitted using all acquired data as the training target. SDnDTI removes noise from each subset of synthesized DWI volumes using a deep 3-dimensional CNN to match the quality of the cleaner target DWI volumes and achieves even higher SNR by averaging all subsets of denoised data. The denoising efficacy of SDnDTI is demonstrated on two datasets provided by the Human Connectome Project (HCP) and the Lifespan HCP in Aging. The SDnDTI results preserve image sharpness and textural details and substantially improve upon those from the raw data. The results of SDnDTI are comparable to those from supervised learning-based denoising and outperform those from state-of-the-art conventional denoising algorithms including BM4D, AONLM and MPPCA.
SRDTI: Deep learning-based super-resolution for diffusion tensor MRI
Feb 17, 2021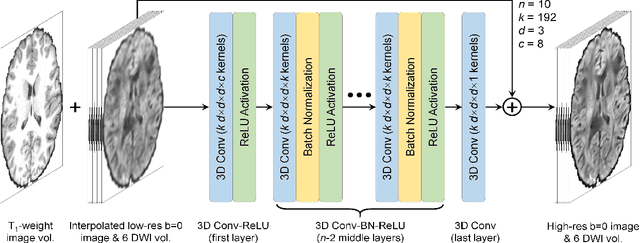
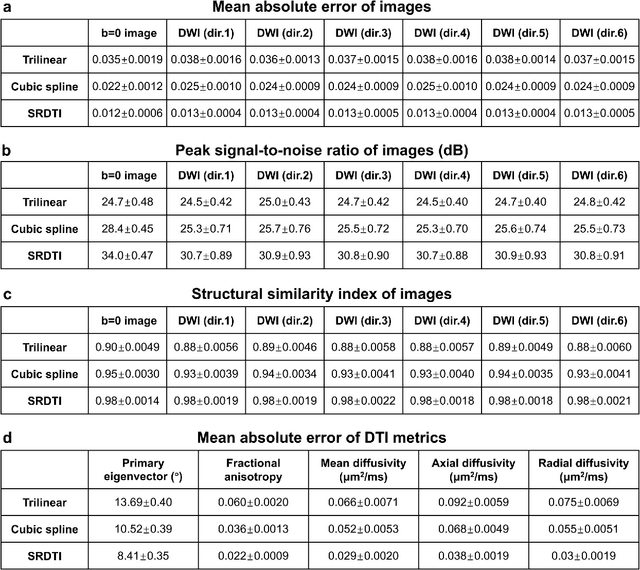
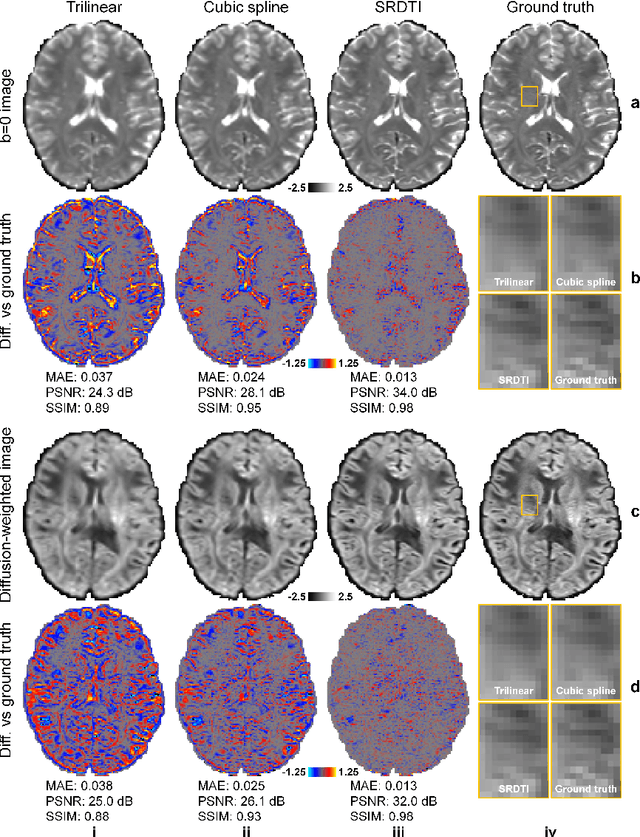
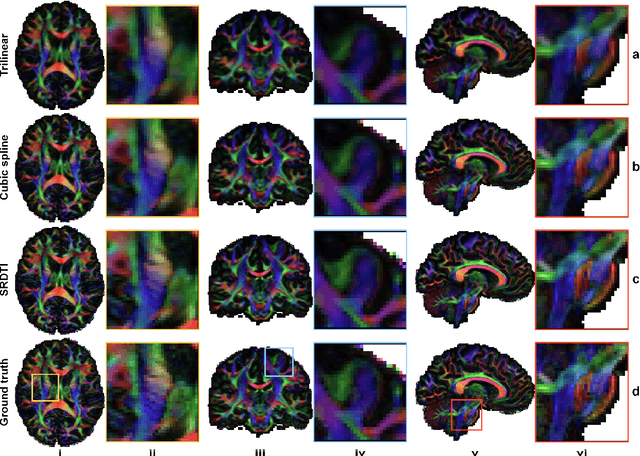
High-resolution diffusion tensor imaging (DTI) is beneficial for probing tissue microstructure in fine neuroanatomical structures, but long scan times and limited signal-to-noise ratio pose significant barriers to acquiring DTI at sub-millimeter resolution. To address this challenge, we propose a deep learning-based super-resolution method entitled "SRDTI" to synthesize high-resolution diffusion-weighted images (DWIs) from low-resolution DWIs. SRDTI employs a deep convolutional neural network (CNN), residual learning and multi-contrast imaging, and generates high-quality results with rich textural details and microstructural information, which are more similar to high-resolution ground truth than those from trilinear and cubic spline interpolation.
Highly Accelerated Multishot EPI through Synergistic Combination of Machine Learning and Joint Reconstruction
Aug 08, 2018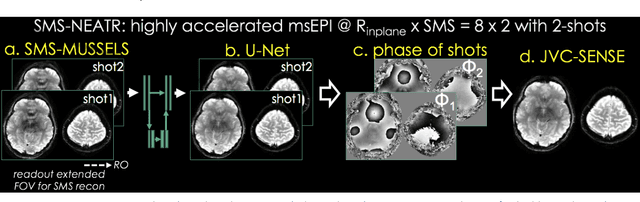
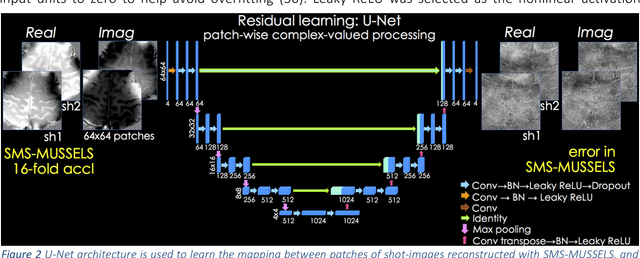
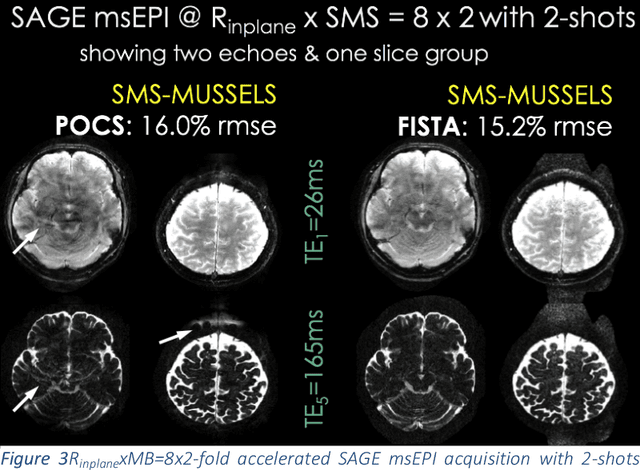
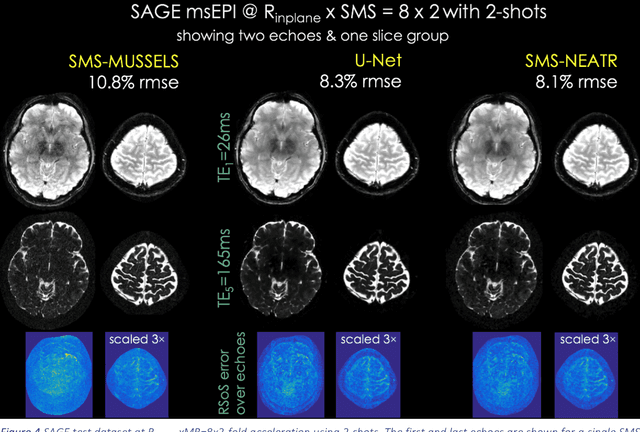
Purpose: To introduce a combined machine learning (ML) and physics-based image reconstruction framework that enables navigator-free, highly accelerated multishot echo planar imaging (msEPI), and demonstrate its application in high-resolution structural imaging. Methods: Singleshot EPI is an efficient encoding technique, but does not lend itself well to high-resolution imaging due to severe distortion artifacts and blurring. While msEPI can mitigate these artifacts, high-quality msEPI has been elusive because of phase mismatch arising from shot-to-shot physiological variations which disrupt the combination of the multiple-shot data into a single image. We employ Deep Learning to obtain an interim magnitude-valued image with minimal artifacts, which permits estimation of image phase variations due to shot-to-shot physiological changes. These variations are then included in a Joint Virtual Coil Sensitivity Encoding (JVC-SENSE) reconstruction to utilize data from all shots and improve upon the ML solution. Results: Our combined ML + physics approach enabled R=8-fold acceleration from 2 EPI-shots while providing 1.8-fold error reduction compared to the MUSSELS, a state-of-the-art reconstruction technique, which is also used as an input to our ML network. Using 3 shots allowed us to push the acceleration to R=10-fold, where we obtained a 1.7-fold error reduction over MUSSELS. Conclusion: Combination of ML and JVC-SENSE enabled navigator-free msEPI at higher accelerations than previously possible while using fewer shots, with reduced vulnerability to poor generalizability and poor acceptance of end-to-end ML approaches.