 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Physics: Operator-Guided Generative Paths for SMS MRI Reconstruction
Feb 08, 2026Simultaneous multi-slice (SMS) imaging with in-plane undersampling enables highly accelerated MRI but yields a strongly coupled inverse problem with deterministic inter-slice interference and missing k-space data. Most diffusion-based reconstructions are formulated around Gaussian-noise corruption and rely on additional consistency steps to incorporate SMS physics, which can be mismatched to the operator-governed degradations in SMS acquisition. We propose an operator-guided framework that models the degradation trajectory using known acquisition operators and inverts this process via deterministic updates. Within this framework, we introduce an operator-conditional dual-stream interaction network (OCDI-Net) that explicitly disentangles target-slice content from inter-slice interference and predicts structured degradations for operator-aligned inversion, and we instantiate reconstruction as a two-stage chained inference procedure that performs SMS slice separation followed by in-plane completion. Experiments on fastMRI brain data and prospectively acquired in vivo diffusion MRI data demonstrate improved fidelity and reduced slice leakage over conventional and learning-based SMS reconstructions.
Sub-DM:Subspace Diffusion Model with Orthogonal Decomposition for MRI Reconstruction
Nov 06, 2024



Diffusion model-based approaches recently achieved re-markable success in MRI reconstruction, but integration into clinical routine remains challenging due to its time-consuming convergence. This phenomenon is partic-ularly notable when directly apply conventional diffusion process to k-space data without considering the inherent properties of k-space sampling, limiting k-space learning efficiency and image reconstruction quality. To tackle these challenges, we introduce subspace diffusion model with orthogonal decomposition, a method (referred to as Sub-DM) that restrict the diffusion process via projections onto subspace as the k-space data distribution evolves toward noise. Particularly, the subspace diffusion model circumvents the inference challenges posed by the com-plex and high-dimensional characteristics of k-space data, so the highly compact subspace ensures that diffusion process requires only a few simple iterations to produce accurate prior information. Furthermore, the orthogonal decomposition strategy based on wavelet transform hin-ders the information loss during the migration of the vanilla diffusion process to the subspace. Considering the strate-gy is approximately reversible, such that the entire pro-cess can be reversed. As a result, it allows the diffusion processes in different spaces to refine models through a mutual feedback mechanism, enabling the learning of ac-curate prior even when dealing with complex k-space data. Comprehensive experiments on different datasets clearly demonstrate that the superiority of Sub-DM against state of-the-art methods in terms of reconstruction speed and quality.
Enhance the Image: Super Resolution using Artificial Intelligence in MRI
Jun 19, 2024



This chapter provides an overview of deep learning techniques for improving the spatial resolution of MRI, ranging from convolutional neural networks, generative adversarial networks, to more advanced models including transformers, diffusion models, and implicit neural representations. Our exploration extends beyond the methodologies to scrutinize the impact of super-resolved images on clinical and neuroscientific assessments. We also cover various practical topics such as network architectures, image evaluation metrics, network loss functions, and training data specifics, including downsampling methods for simulating low-resolution images and dataset selection. Finally, we discuss existing challenges and potential future directions regarding the feasibility and reliability of deep learning-based MRI super-resolution, with the aim to facilitate its wider adoption to benefit various clinical and neuroscientific applications.
Quantifying the uncertainty of neural networks using Monte Carlo dropout for deep learning based quantitative MRI
Dec 02, 2021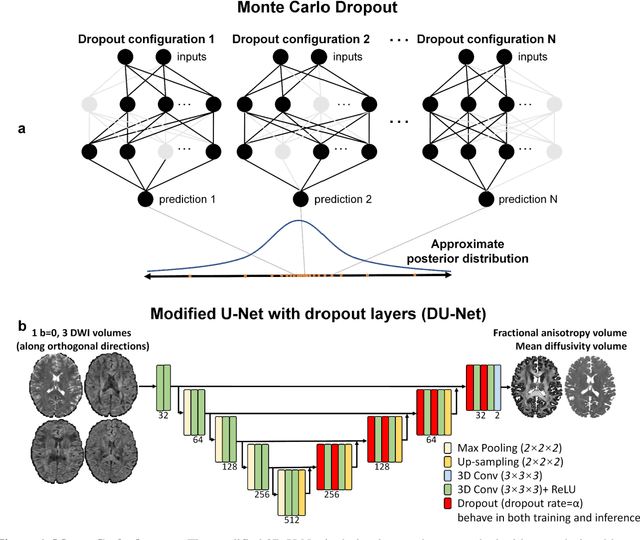
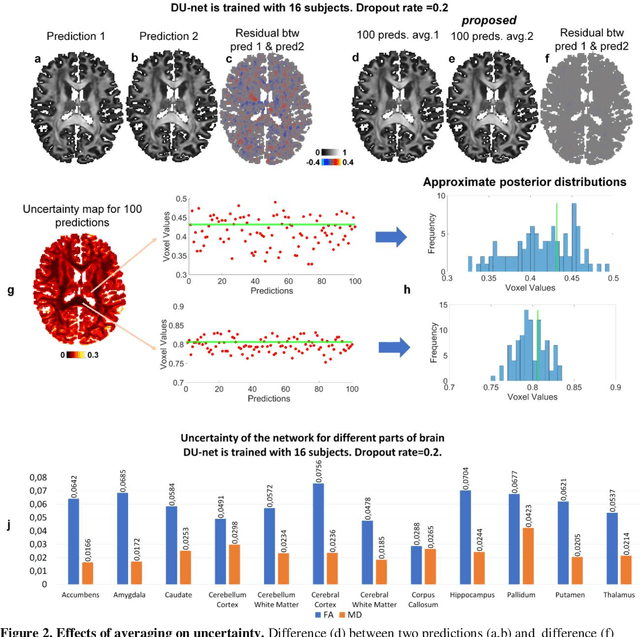
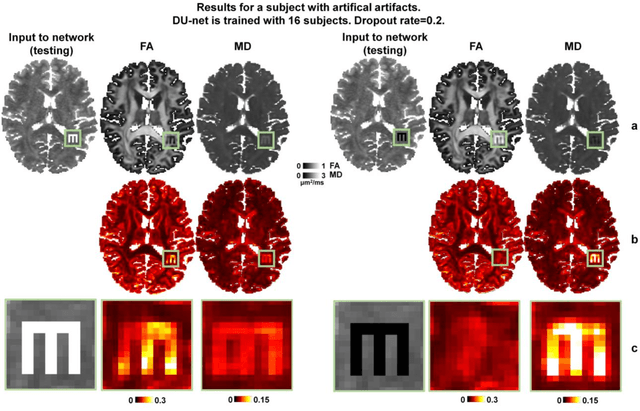
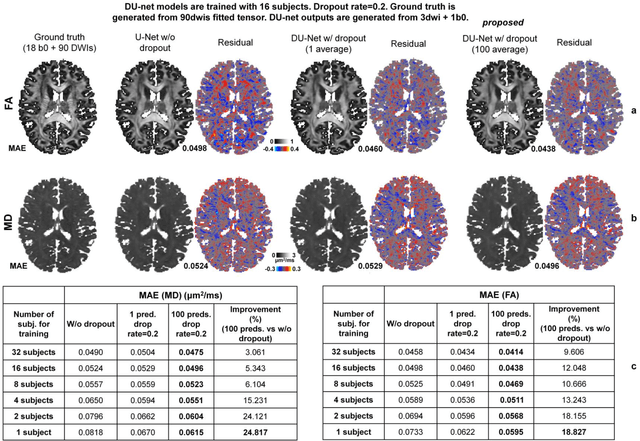
Dropout is conventionally used during the training phase as regularization method and for quantifying uncertainty in deep learning. We propose to use dropout during training as well as inference steps, and average multiple predictions to improve the accuracy, while reducing and quantifying the uncertainty. The results are evaluated for fractional anisotropy (FA) and mean diffusivity (MD) maps which are obtained from only 3 direction scans. With our method, accuracy can be improved significantly compared to network outputs without dropout, especially when the training dataset is small. Moreover, confidence maps are generated which may aid in diagnosis of unseen pathology or artifacts.
SDnDTI: Self-supervised deep learning-based denoising for diffusion tensor MRI
Nov 14, 2021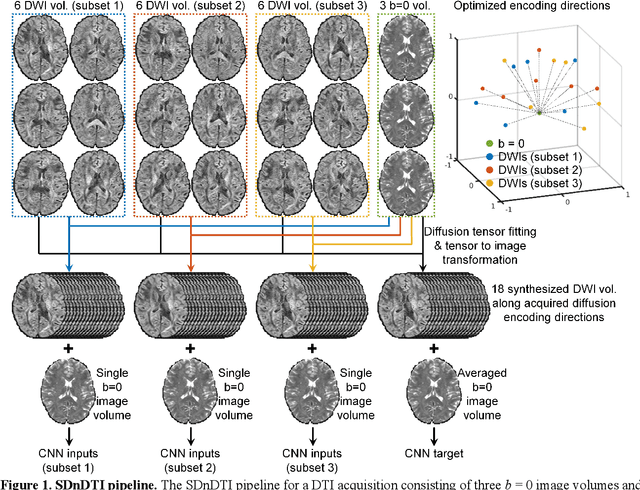
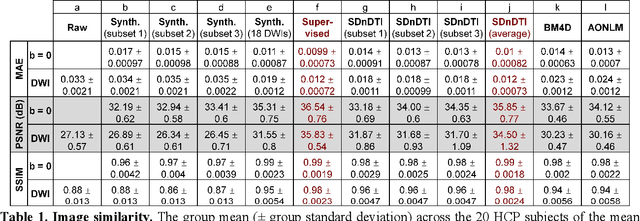
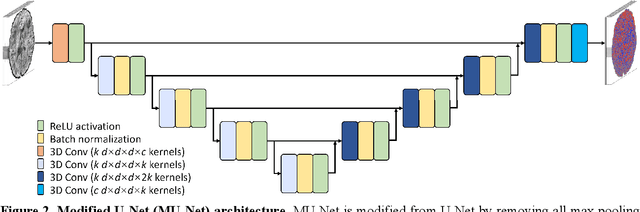
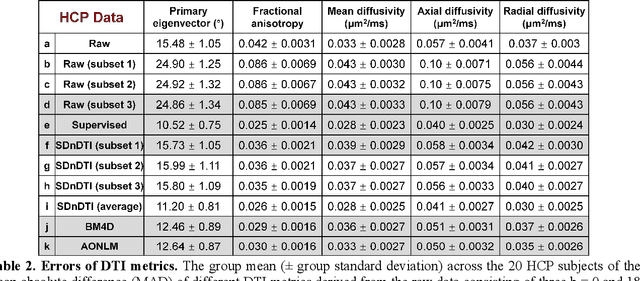
The noise in diffusion-weighted images (DWIs) decreases the accuracy and precision of diffusion tensor magnetic resonance imaging (DTI) derived microstructural parameters and leads to prolonged acquisition time for achieving improved signal-to-noise ratio (SNR). Deep learning-based image denoising using convolutional neural networks (CNNs) has superior performance but often requires additional high-SNR data for supervising the training of CNNs, which reduces the practical feasibility. We develop a self-supervised deep learning-based method entitled "SDnDTI" for denoising DTI data, which does not require additional high-SNR data for training. Specifically, SDnDTI divides multi-directional DTI data into many subsets, each consisting of six DWI volumes along optimally chosen diffusion-encoding directions that are robust to noise for the tensor fitting, and then synthesizes DWI volumes along all acquired directions from the diffusion tensors fitted using each subset of the data as the input data of CNNs. On the other hand, SDnDTI synthesizes DWI volumes along acquired diffusion-encoding directions with higher SNR from the diffusion tensors fitted using all acquired data as the training target. SDnDTI removes noise from each subset of synthesized DWI volumes using a deep 3-dimensional CNN to match the quality of the cleaner target DWI volumes and achieves even higher SNR by averaging all subsets of denoised data. The denoising efficacy of SDnDTI is demonstrated on two datasets provided by the Human Connectome Project (HCP) and the Lifespan HCP in Aging. The SDnDTI results preserve image sharpness and textural details and substantially improve upon those from the raw data. The results of SDnDTI are comparable to those from supervised learning-based denoising and outperform those from state-of-the-art conventional denoising algorithms including BM4D, AONLM and MPPCA.
SRDTI: Deep learning-based super-resolution for diffusion tensor MRI
Feb 17, 2021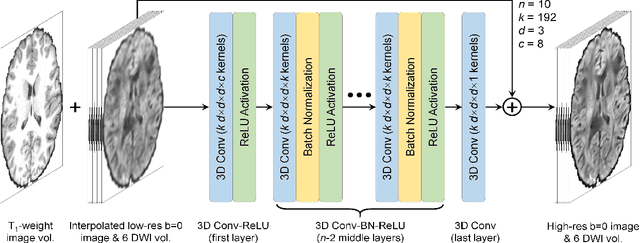
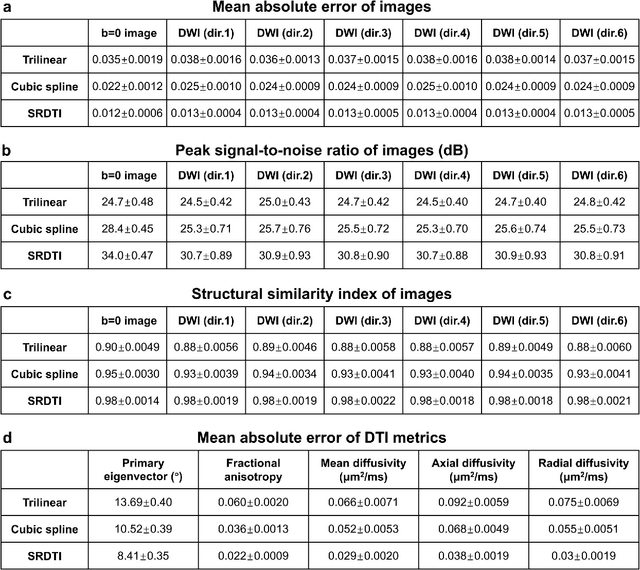
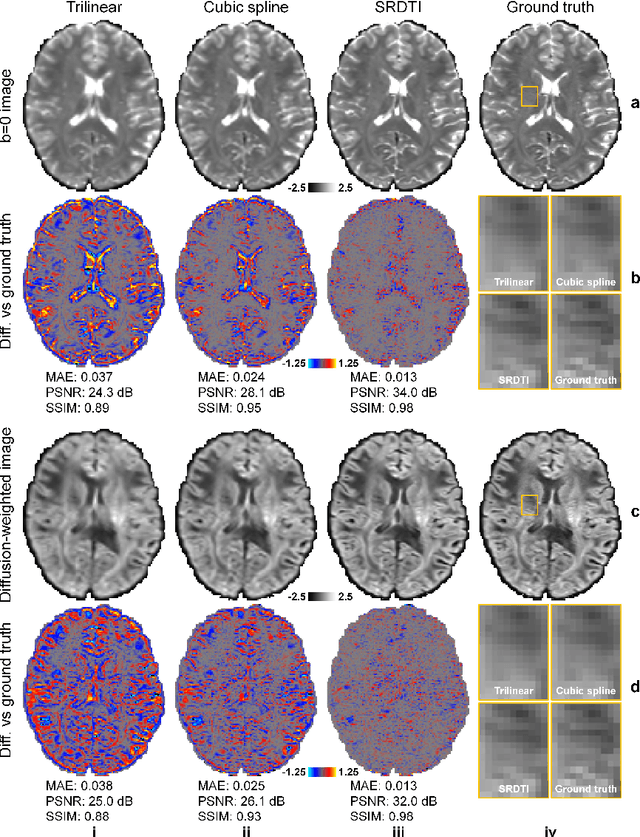
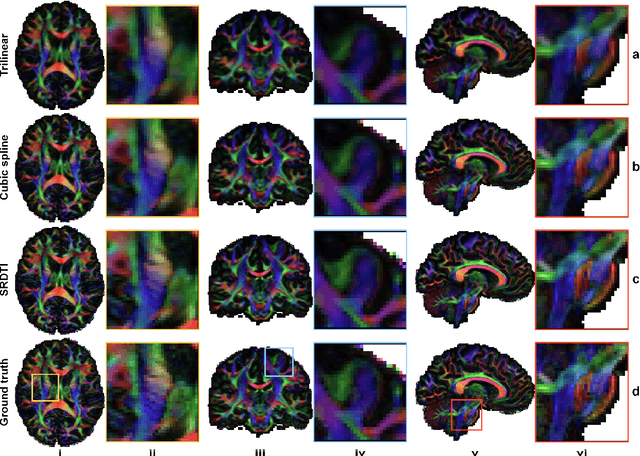
High-resolution diffusion tensor imaging (DTI) is beneficial for probing tissue microstructure in fine neuroanatomical structures, but long scan times and limited signal-to-noise ratio pose significant barriers to acquiring DTI at sub-millimeter resolution. To address this challenge, we propose a deep learning-based super-resolution method entitled "SRDTI" to synthesize high-resolution diffusion-weighted images (DWIs) from low-resolution DWIs. SRDTI employs a deep convolutional neural network (CNN), residual learning and multi-contrast imaging, and generates high-quality results with rich textural details and microstructural information, which are more similar to high-resolution ground truth than those from trilinear and cubic spline interpolation.