 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stage Active Distribution Network Voltage Control via LLM-RL Collaboration: A Hybrid Knowledge-Data-Driven Approach
Feb 25, 2026The growing integration of distributed photovoltaics (PVs) into active distribution networks (ADNs) has exacerbated operational challenges, making it imperative to coordinate diverse equipment to mitigate voltage violations and enhance power quality. Although existing data-driven approaches have demonstrated effectiveness in the voltage control problem, they often require extensive trial-and-error exploration and struggle to incorporate heterogeneous information, such as day-ahead forecasts and semantic-based grid codes. Considering the operational scenarios and requirements in real-world ADNs, in this paper, we propose a hybrid knowledge-data-driven approach that leverages dynamic collaboration between a large language model (LLM) agent and a reinforcement learning (RL) agent to achieve two-stage voltage control. In the day-ahead stage, the LLM agent receives coarse region-level forecasts and generates scheduling strategies for on-load tap changer (OLTC) and shunt capacitors (SCs) to regulate the overall voltage profile. Then in the intra-day stage, based on accurate node-level measurements, the RL agent refines terminal voltages by deriving reactive power generation strategies for PV inverters. On top of the LLM-RL collaboration framework, we further propose a self-evolution mechanism for the LLM agent and a pretrain-finetune pipeline for the RL agent, effectively enhancing and coordinating the policies for both agents. The proposed approach not only aligns more closely with practical operational characteristics but also effectively utilizes the inherent knowledge and reasoning capabilities of the LLM agent, significantly improving training efficiency and voltage control performance. Comprehensive comparisons and ablation studies demonstrate the effectiveness of the proposed method.
High-fidelity 3D multi-slab diffusion MRI using Slab-shifting for Harmonized 3D Acquisition and Reconstruction with Profile Encoding Networks (SHARPEN)
Feb 06, 2026Three-dimensional (3D) multi-slab imaging is a promising approach for high-resolution in vivo diffusion MRI (dMRI) due to its compatibility with short TR (1-2 s), providing optimal signal-to-noise ratio (SNR) efficiency. A major challenge, however, is slab boundary artifacts arising from non-ideal slab-selective RF excitation. Non-rectangular slab profiles reduce signal intensity at slab boundaries, while profile overlap across adjacent slabs introduces inter-slab crosstalk, where repeated excitation shortens the local TR and limits T1 recovery. To mitigate slab boundary artifacts without increasing scan time, we build on slab profile encoding and propose Slab-shifting for Harmonized 3D Acquisition and Reconstruction with Profile Encoding Networks (SHARPEN). For different diffusion directions, SHARPEN applies inter-volume field-of-view shifts along the slice direction to provide complementary slab profile encoding without prolonging acquisition. Slab profiles are estimated using a lightweight self-supervised neural network that exploits consistency across shifted acquisitions and known physical properties of slab profiles and diffusion images, and corrected images are reconstructed accordingly. SHARPEN was validated using simulated and prospectively acquired high-resolution in vivo data and demonstrates accurate slab profile estimation and robust boundary artifact correction, even in the presence of inter-volume motion. SHARPEN does not require high-quality reference training data and supports subject-specific training. Its efficient GPU-based implementation delivers faster and more accurate correction than NPEN, yielding slice-wise quantitative profiles that closely match those from reference 2D acquisitions. SHARPEN enables high-quality dMRI at 0.7 mm isotropic resolution on a 3T clinical scanner, highlighting its potential to advance submillimeter dMRI for neuroscience research.
One Request, Multiple Experts: LLM Orchestrates Domain Specific Models via Adaptive Task Routing
Nov 16, 2025With the integration of massive distributed energy resources and the widespread participation of novel market entities, the operation of active distribution networks (ADNs) is progressively evolving into a complex multi-scenario, multi-objective problem. Although expert engineers have developed numerous domain specific models (DSMs) to address distinct technical problems, mastering, integrating, and orchestrating these heterogeneous DSMs still entail considerable overhead for ADN operators. Therefore, an intelligent approach is urgently required to unify these DSMs and enable efficient coordination. To address this challenge, this paper proposes the ADN-Agent architecture, which leverages a general large language model (LLM) to coordinate multiple DSMs, enabling adaptive intent recognition, task decomposition, and DSM invocation. Within the ADN-Agent, we design a novel communication mechanism that provides a unified and flexible interface for diverse heterogeneous DSMs. Finally, for some language-intensive subtasks, we propose an automated training pipeline for fine-tuning small language models, thereby effectively enhancing the overall problem-solving capability of the system. Comprehensive comparisons and ablation experiments validate the efficacy of the proposed method and demonstrate that the ADN-Agent architecture outperforms existing LLM application paradigms.
RL2: Reinforce Large Language Model to Assist Safe Reinforcement Learning for Energy Management of Active Distribution Networks
Dec 02, 2024



As large-scale distributed energy resources are integrated into the active distribution networks (ADNs), effective energy management in ADNs becomes increasingly prominent compared to traditional distribution networks. Although advanced reinforcement learning (RL) methods, which alleviate the burden of complicated modelling and optimization, have greatly improved the efficiency of energy management in ADNs, safety becomes a critical concern for RL applications in real-world problems. Since the design and adjustment of penalty functions, which correspond to operational safety constraints, requires extensive domain knowledge in RL and power system operation, the emerging ADN operators call for a more flexible and customized approach to address the penalty functions so that the operational safety and efficiency can be further enhanced. Empowered with strong comprehension, reasoning, and in-context learning capabilities, large language models (LLMs) provide a promising way to assist safe RL for energy management in ADNs. In this paper, we introduce the LLM to comprehend operational safety requirements in ADNs and generate corresponding penalty functions. In addition, we propose an RL2 mechanism to refine the generated functions iteratively and adaptively through multi-round dialogues, in which the LLM agent adjusts the functions' pattern and parameters based on training and test performance of the downstream RL agent. The proposed method significantly reduces the intervention of the ADN operators. Comprehensive test results demonstrate the effectiveness of the proposed method.
Enhance the Image: Super Resolution using Artificial Intelligence in MRI
Jun 19, 2024



This chapter provides an overview of deep learning techniques for improving the spatial resolution of MRI, ranging from convolutional neural networks, generative adversarial networks, to more advanced models including transformers, diffusion models, and implicit neural representations. Our exploration extends beyond the methodologies to scrutinize the impact of super-resolved images on clinical and neuroscientific assessments. We also cover various practical topics such as network architectures, image evaluation metrics, network loss functions, and training data specifics, including downsampling methods for simulating low-resolution images and dataset selection. Finally, we discuss existing challenges and potential future directions regarding the feasibility and reliability of deep learning-based MRI super-resolution, with the aim to facilitate its wider adoption to benefit various clinical and neuroscientific applications.
Self-navigated 3D diffusion MRI using an optimized CAIPI sampling and structured low-rank reconstruction
Jan 11, 2024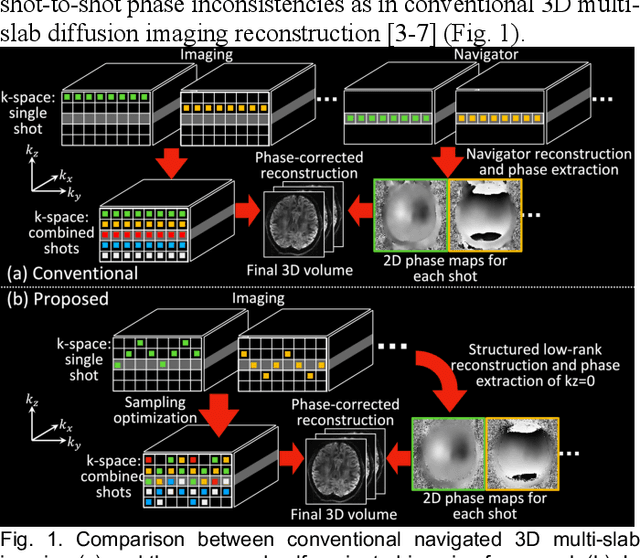
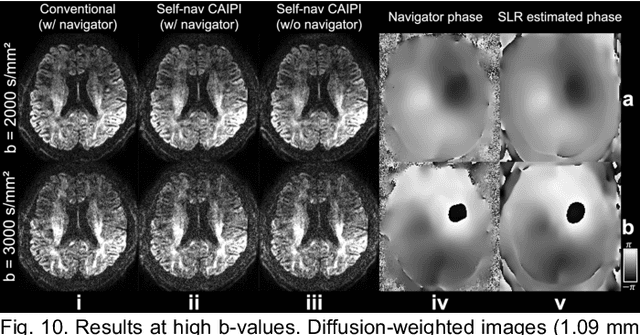
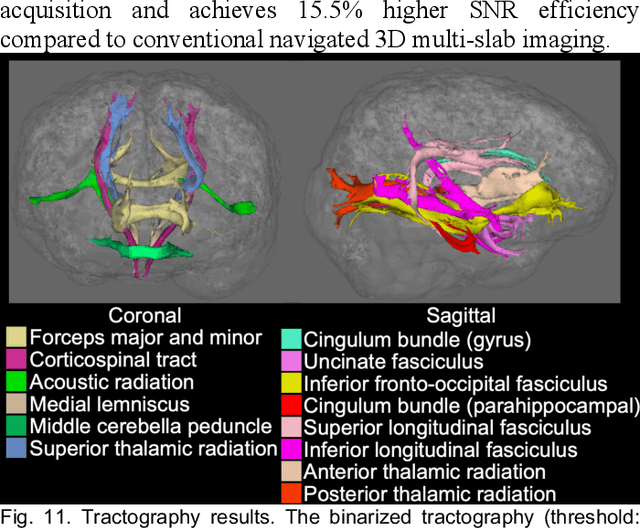
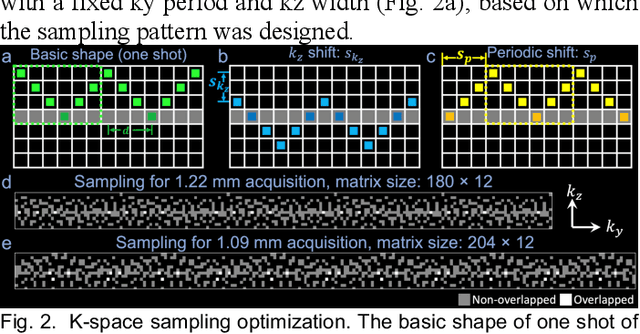
3D multi-slab acquisitions are an appealing approach for diffusion MRI because they are compatible with the imaging regime delivering optimal SNR efficiency. In conventional 3D multi-slab imaging, shot-to-shot phase variations caused by motion pose challenges due to the use of multi-shot k-space acquisition. Navigator acquisition after each imaging echo is typically employed to correct phase variations, which prolongs scan time and increases the specific absorption rate (SAR). The aim of this study is to develop a highly efficient, self-navigated method to correct for phase variations in 3D multi-slab diffusion MRI without explicitly acquiring navigators. The sampling of each shot is carefully designed to intersect with the central kz plane of each slab, and the multi-shot sampling is optimized for self-navigation performance while retaining decent reconstruction quality. The central kz intersections from all shots are jointly used to reconstruct a 2D phase map for each shot using a structured low-rank constrained reconstruction that leverages the redundancy in shot and coil dimensions. The phase maps are used to eliminate the shot-to-shot phase inconsistency in the final 3D multi-shot reconstruction. We demonstrate the method's efficacy using retrospective simulations and prospectively acquired in-vivo experiments at 1.22 mm and 1.09 mm isotropic resolutions. Compared to conventional navigated 3D multi-slab imaging, the proposed self-navigated method achieves comparable image quality while shortening the scan time by 31.7% and improving the SNR efficiency by 15.5%. The proposed method produces comparable quality of DTI and white matter tractography to conventional navigated 3D multi-slab acquisition with a much shorter scan time.
Bi-level Off-policy Reinforcement Learning for Volt/VAR Control Involving Continuous and Discrete Devices
Apr 13, 2021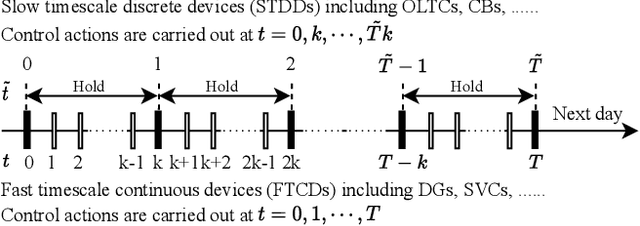
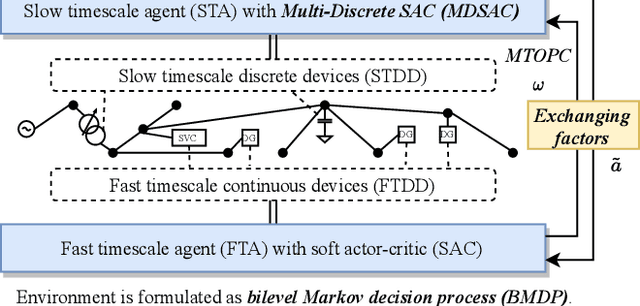
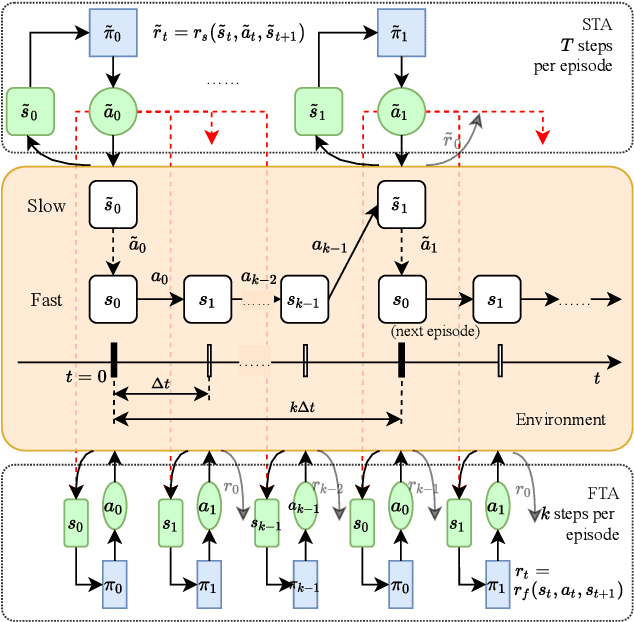
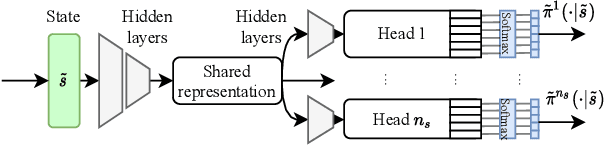
In Volt/Var control (VVC) of active distribution networks(ADNs), both slow timescale discrete devices (STDDs) and fast timescale continuous devices (FTCDs) are involved. The STDDs such as on-load tap changers (OLTC) and FTCDs such as distributed generators should be coordinated in time sequence. Such VCC is formulated as a two-timescale optimization problem to jointly optimize FTCDs and STDDs in ADNs. Traditional optimization methods are heavily based on accurate models of the system, but sometimes impractical because of their unaffordable effort on modelling. In this paper, a novel bi-level off-policy reinforcement learning (RL) algorithm is proposed to solve this problem in a model-free manner. A Bi-level Markov decision process (BMDP) is defined to describe the two-timescale VVC problem and separate agents are set up for the slow and fast timescale sub-problems. For the fast timescale sub-problem, we adopt an off-policy RL method soft actor-critic with high sample efficiency. For the slow one, we develop an off-policy multi-discrete soft actor-critic (MDSAC) algorithm to address the curse of dimensionality with various STDDs. To mitigate the non-stationary issue existing the two agents' learning processes, we propose a multi-timescale off-policy correction (MTOPC) method by adopting importance sampling technique. Comprehensive numerical studies not only demonstrate that the proposed method can achieve stable and satisfactory optimization of both STDDs and FTCDs without any model information, but also support that the proposed method outperforms existing two-timescale VVC methods.
Online Multi-agent Reinforcement Learning for Decentralized Inverter-based Volt-VAR Control
Jun 23, 2020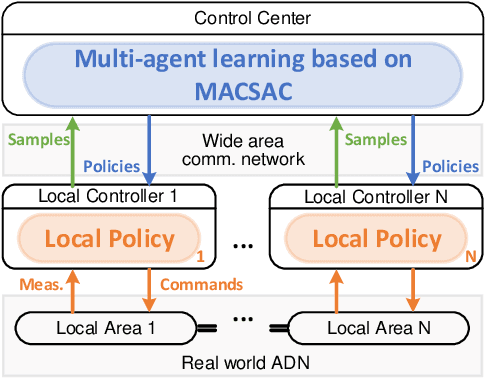
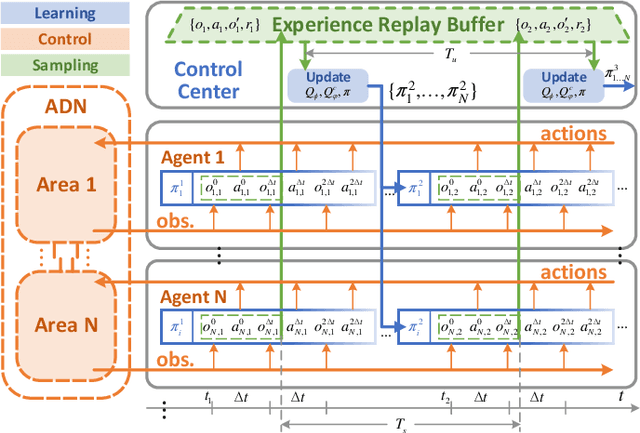
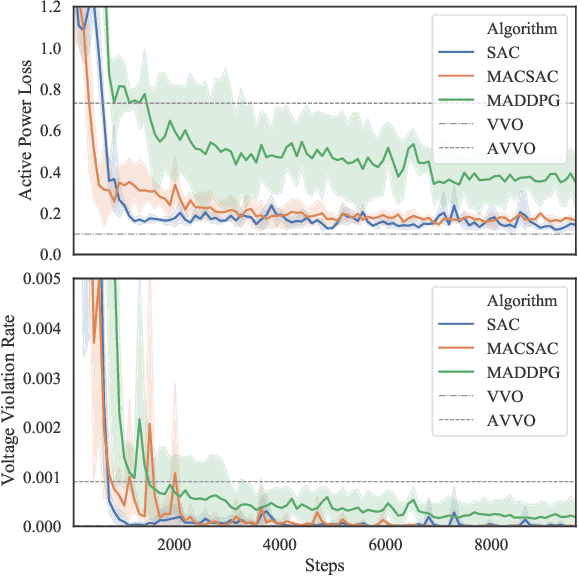
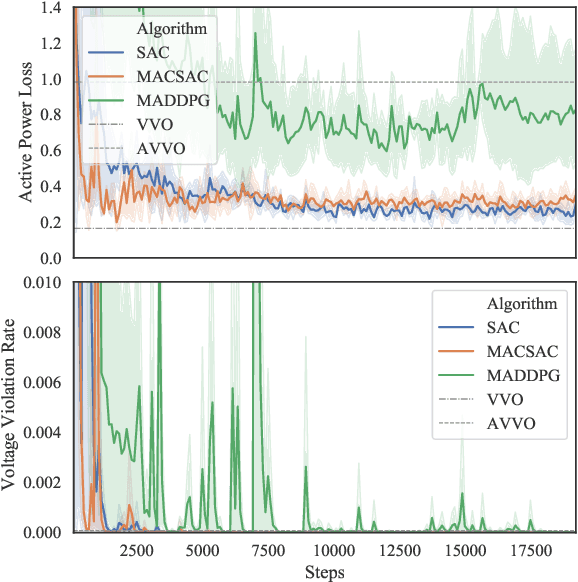
The distributed Volt/Var control (VVC) methods have been widely studied for active distribution networks(ADNs), which is based on perfect model and real-time P2P communication. However, the model is always incomplete with significant parameter errors and such P2P communication system is hard to maintain. In this paper, we propose an online multi-agent reinforcement learning and decentralized control framework (OLDC) for VVC. In this framework, the VVC problem is formulated as a constrained Markov game and we propose a novel multi-agent constrained soft actor-critic (MACSAC) reinforcement learning algorithm. MACSAC is used to train the control agents online, so the accurate ADN model is no longer needed. Then, the trained agents can realize decentralized optimal control using local measurements without real-time P2P communication. The OLDC with MACSAC has shown extraordinary flexibility, efficiency and robustness to various computing and communication conditions. Numerical simulations on IEEE test cases not only demonstrate that the proposed MACSAC outperforms the state-of-art learning algorithms, but also support the superiority of our OLDC framework in the online application.
Two-stage Deep Reinforcement Learning for Inverter-based Volt-VAR Control in Active Distribution Networks
May 20, 2020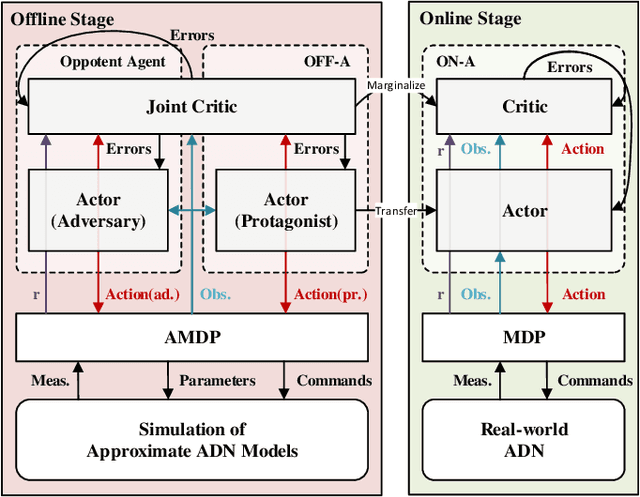
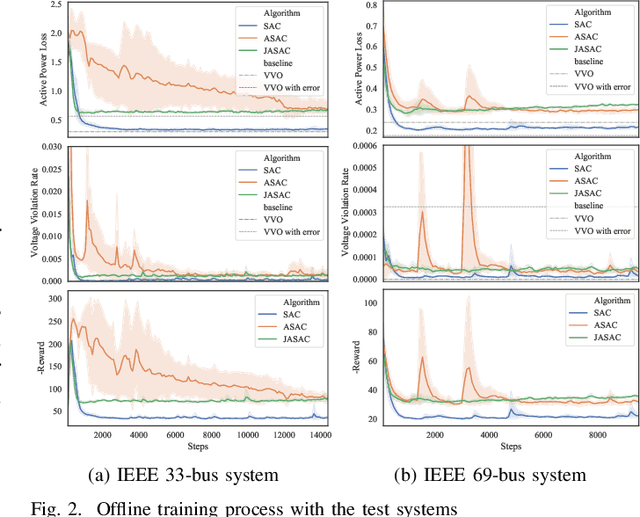
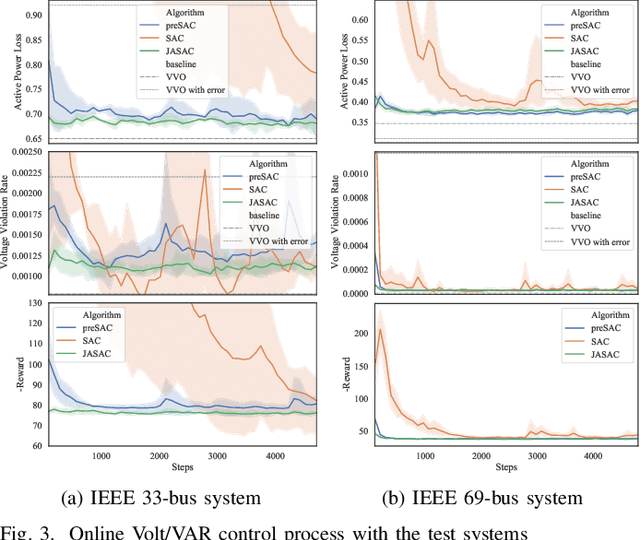
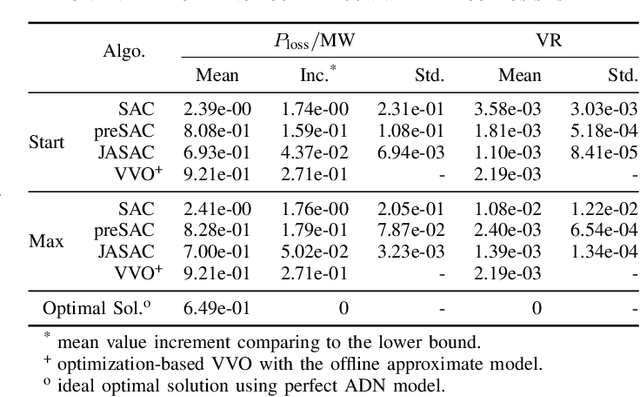
Model-based Vol/VAR optimization method is widely used to eliminate voltage violations and reduce network losses. However, the parameters of active distribution networks(ADNs) are not onsite identified, so significant errors may be involved in the model and make the model-based method infeasible. To cope with this critical issue, we propose a novel two-stage deep reinforcement learning (DRL) method to improve the voltage profile by regulating inverter-based energy resources, which consists of offline stage and online stage. In the offline stage, a highly efficient adversarial reinforcement learning algorithm is developed to train an offline agent robust to the model mismatch. In the sequential online stage, we transfer the offline agent safely as the online agent to perform continuous learning and controlling online with significantly improved safety and efficiency. Numerical simulations on IEEE test cases not only demonstrate that the proposed adversarial reinforcement learning algorithm outperforms the state-of-art algorithm, but also show that our proposed two-stage method achieves much better performance than the existing DRL based methods in the online application.
Human-like machine thinking: Language guided imagination
Jun 01, 2019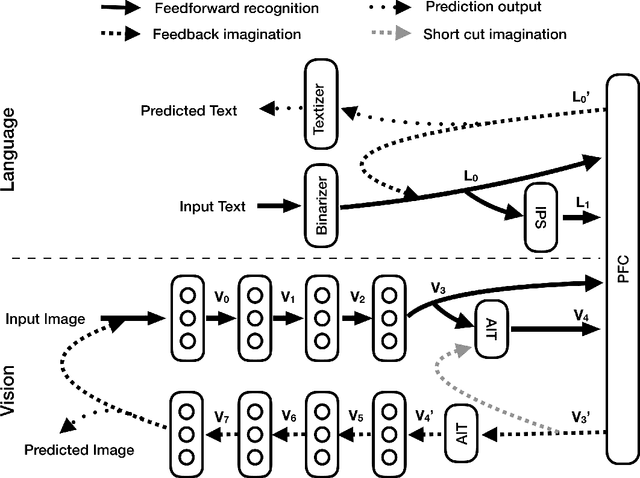
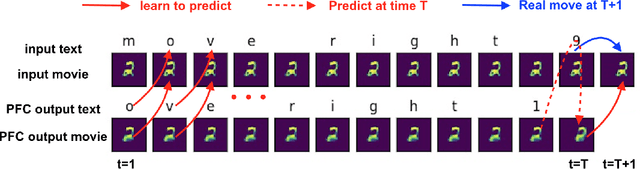

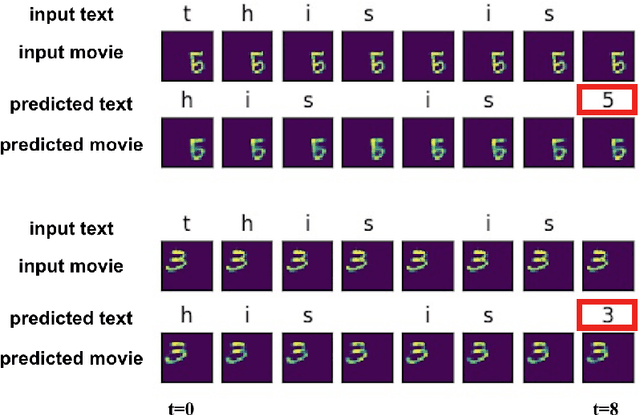
Human thinking requires the brain to understand the meaning of language expression and to properly organize the thoughts flow using the language. However, current natural language processing models are primarily limited in the word probability estimation. Here, we proposed a Language guided imagination (LGI) network to incrementally learn the meaning and usage of numerous words and syntaxes, aiming to form a human-like machine thinking process. LGI contains three subsystems: (1) vision system that contains an encoder to disentangle the input or imagined scenarios into abstract population representations, and an imagination decoder to reconstruct imagined scenario from higher level representations; (2) Language system, that contains a binarizer to transfer symbol texts into binary vectors, an IPS (mimicking the human IntraParietal Sulcus, implemented by an LSTM) to extract the quantity information from the input texts, and a textizer to convert binary vectors into text symbols; (3) a PFC (mimicking the human PreFrontal Cortex, implemented by an LSTM) to combine inputs of both language and vision representations, and predict text symbols and manipulated images accordingly. LGI has incrementally learned eight different syntaxes (or tasks), with which a machine thinking loop has been formed and validated by the proper interaction between language and vision system. The paper provides a new architecture to let the machine learn, understand and use language in a human-like way that could ultimately enable a machine to construct fictitious 'mental' scenario and possess intelligence.