 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Bounds on Parallel Imaging Implicit Data Crimes in an MRI Reproducing Kernel Hilbert Space
Nov 19, 2025Magnetic Resonance Imaging (MRI) diagnoses and manages a wide range of diseases, yet long scan times drive high costs and limit accessibility. AI methods have demonstrated substantial potential for reducing scan times, but despite rapid progress, clinical translation of AI often fails. One particular class of failure modes, referred to as implicit data crimes, are a result of hidden biases introduced when MRI datasets incompletely model the MRI physics of the acquisition. Previous work identified data crimes resulting from algorithmic completion of k-space with parallel imaging and drew on simulation to demonstrate the resulting downstream biases. This work proposes a mathematical framework to re-characterize the problem as one of error reduction during interpolation between sets of evaluation coordinates. We establish a generalized matrix-based definition of the reconstruction error upper bound as a function of the input sampling pattern. Experiments on relevant sampling pattern structures demonstrate the relevance of the framework and suggest future directions for analysis of data crimes.
Diffusion Probabilistic Generative Models for Accelerated, in-NICU Permanent Magnet Neonatal MRI
May 21, 2025Purpose: Magnetic Resonance Imaging (MRI) enables non-invasive assessment of brain abnormalities during early life development. Permanent magnet scanners operating in the neonatal intensive care unit (NICU) facilitate MRI of sick infants, but have long scan times due to lower signal-to-noise ratios (SNR) and limited receive coils. This work accelerates in-NICU MRI with diffusion probabilistic generative models by developing a training pipeline accounting for these challenges. Methods: We establish a novel training dataset of clinical, 1 Tesla neonatal MR images in collaboration with Aspect Imaging and Sha'are Zedek Medical Center. We propose a pipeline to handle the low quantity and SNR of our real-world dataset (1) modifying existing network architectures to support varying resolutions; (2) training a single model on all data with learned class embedding vectors; (3) applying self-supervised denoising before training; and (4) reconstructing by averaging posterior samples. Retrospective under-sampling experiments, accounting for signal decay, evaluated each item of our proposed methodology. A clinical reader study with practicing pediatric neuroradiologists evaluated our proposed images reconstructed from 1.5x under-sampled data. Results: Combining all data, denoising pre-training, and averaging posterior samples yields quantitative improvements in reconstruction. The generative model decouples the learned prior from the measurement model and functions at two acceleration rates without re-training. The reader study suggests that proposed images reconstructed from approximately 1.5x under-sampled data are adequate for clinical use. Conclusion: Diffusion probabilistic generative models applied with the proposed pipeline to handle challenging real-world datasets could reduce scan time of in-NICU neonatal MRI.
Accelerated, Robust Lower-Field Neonatal MRI with Generative Models
Oct 28, 2024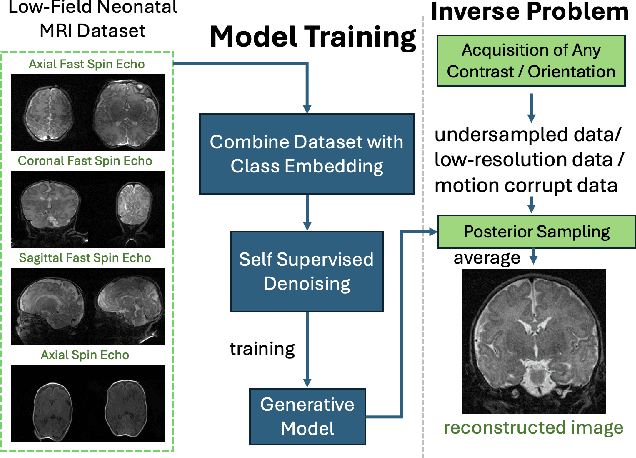
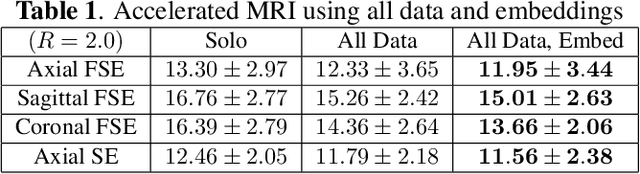
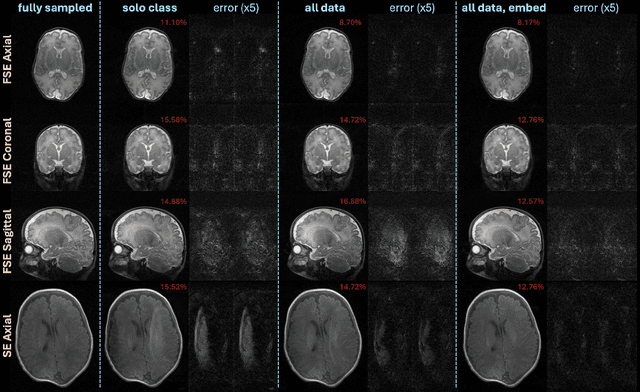
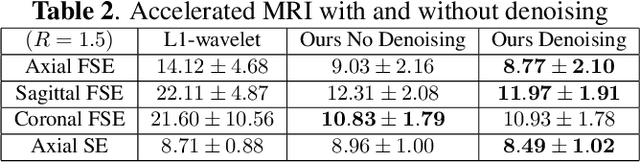
Neonatal Magnetic Resonance Imaging (MRI) enables non-invasive assessment of potential brain abnormalities during the critical phase of early life development. Recently, interest has developed in lower field (i.e., below 1.5 Tesla) MRI systems that trade-off magnetic field strength for portability and access in the neonatal intensive care unit (NICU). Unfortunately, lower-field neonatal MRI still suffers from long scan times and motion artifacts that can limit its clinical utility for neonates. This work improves motion robustness and accelerates lower field neonatal MRI through diffusion-based generative modeling and signal processing based motion modeling. We first gather a training dataset of clinical neonatal MRI images. Then we train a diffusion-based generative model to learn the statistical distribution of fully-sampled images by applying several signal processing methods to handle the lower signal-to-noise ratio and lower quality of our MRI images. Finally, we present experiments demonstrating the utility of our generative model to improve reconstruction performance across two tasks: accelerated MRI and motion correction.
INFusion: Diffusion Regularized Implicit Neural Representations for 2D and 3D accelerated MRI reconstruction
Jun 19, 2024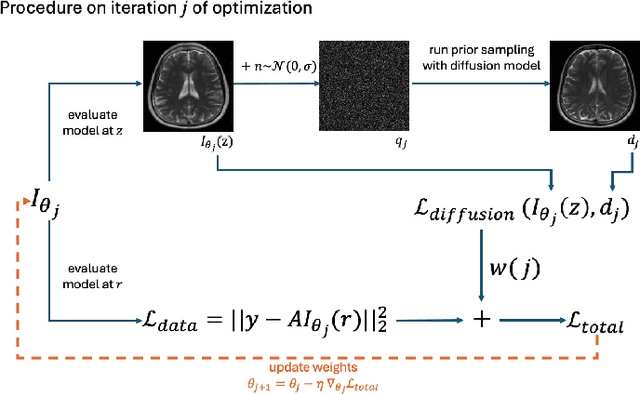
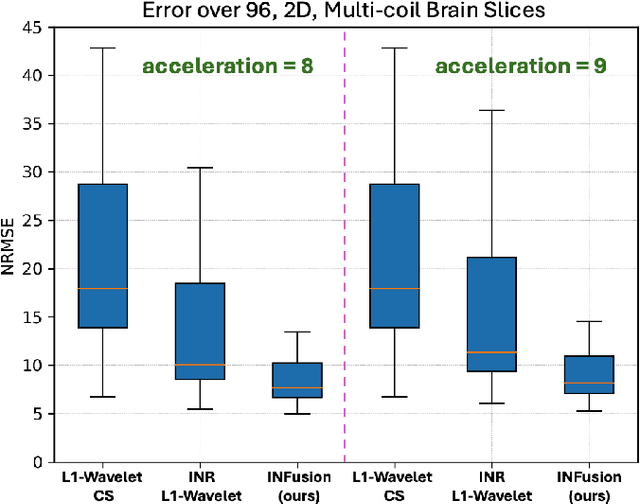
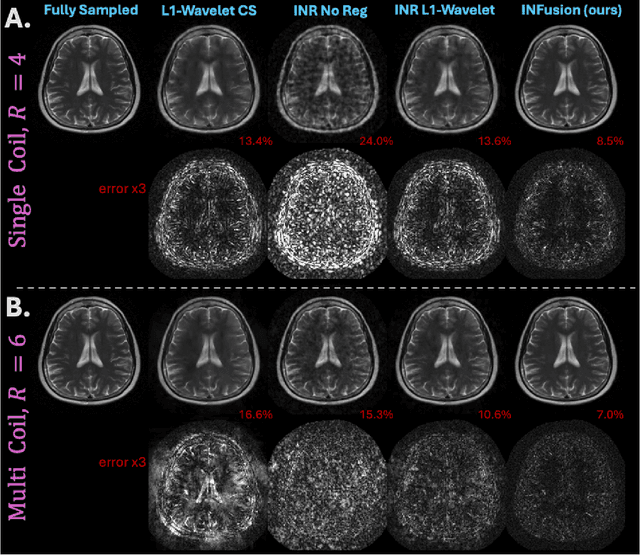
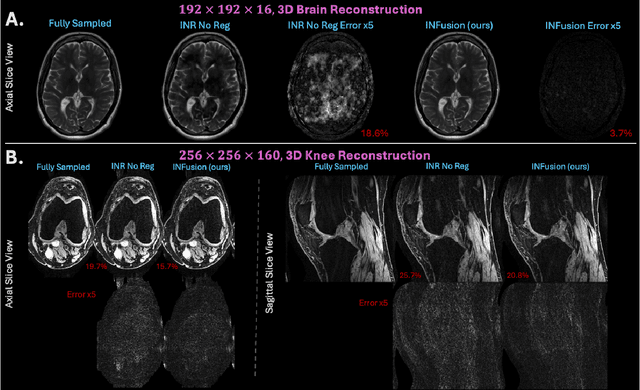
Implicit Neural Representations (INRs) are a learning-based approach to accelerate Magnetic Resonance Imaging (MRI) acquisitions, particularly in scan-specific settings when only data from the under-sampled scan itself are available. Previous work demonstrates that INRs improve rapid MRI through inherent regularization imposed by neural network architectures. Typically parameterized by fully-connected neural networks, INRs support continuous image representations by taking a physical coordinate location as input and outputting the intensity at that coordinate. Previous work has applied unlearned regularization priors during INR training and have been limited to 2D or low-resolution 3D acquisitions. Meanwhile, diffusion based generative models have received recent attention as they learn powerful image priors decoupled from the measurement model. This work proposes INFusion, a technique that regularizes the optimization of INRs from under-sampled MR measurements with pre-trained diffusion models for improved image reconstruction. In addition, we propose a hybrid 3D approach with our diffusion regularization that enables INR application on large-scale 3D MR datasets. 2D experiments demonstrate improved INR training with our proposed diffusion regularization, and 3D experiments demonstrate feasibility of INR training with diffusion regularization on 3D matrix sizes of 256 by 256 by 80.
SubZero: Subspace Zero-Shot MRI Reconstruction
Nov 28, 2023Recently introduced zero-shot self-supervised learning (ZS-SSL) has shown potential in accelerated MRI in a scan-specific scenario, which enabled high-quality reconstructions without access to a large training dataset. ZS-SSL has been further combined with the subspace model to accelerate 2D T2-shuffling acquisitions. In this work, we propose a parallel network framework and introduce an attention mechanism to improve subspace-based zero-shot self-supervised learning and enable higher acceleration factors. We name our method SubZero and demonstrate that it can achieve improved performance compared with current methods in T1 and T2 mapping acquisitions.
Zero-DeepSub: Zero-Shot Deep Subspace Reconstruction for Rapid Multiparametric Quantitative MRI Using 3D-QALAS
Jul 04, 2023Purpose: To develop and evaluate methods for 1) reconstructing 3D-quantification using an interleaved Look-Locker acquisition sequence with T2 preparation pulse (3D-QALAS) time-series images using a low-rank subspace method, which enables accurate and rapid T1 and T2 mapping, and 2) improving the fidelity of subspace QALAS by combining scan-specific deep-learning-based reconstruction and subspace modeling. Methods: A low-rank subspace method for 3D-QALAS (i.e., subspace QALAS) and zero-shot deep-learning subspace method (i.e., Zero-DeepSub) were proposed for rapid and high fidelity T1 and T2 mapping and time-resolved imaging using 3D-QALAS. Using an ISMRM/NIST system phantom, the accuracy of the T1 and T2 maps estimated using the proposed methods was evaluated by comparing them with reference techniques. The reconstruction performance of the proposed subspace QALAS using Zero-DeepSub was evaluated in vivo and compared with conventional QALAS at high reduction factors of up to 9-fold. Results: Phantom experiments showed that subspace QALAS had good linearity with respect to the reference methods while reducing biases compared to conventional QALAS, especially for T2 maps. Moreover, in vivo results demonstrated that subspace QALAS had better g-factor maps and could reduce voxel blurring, noise, and artifacts compared to conventional QALAS and showed robust performance at up to 9-fold acceleration with Zero-DeepSub, which enabled whole-brain T1, T2, and PD mapping at 1 mm isotropic resolution within 2 min of scan time. Conclusion: The proposed subspace QALAS along with Zero-DeepSub enabled high fidelity and rapid whole-brain multiparametric quantification and time-resolved imaging.
Zero-Shot Self-Supervised Joint Temporal Image and Sensitivity Map Reconstruction via Linear Latent Space
Mar 03, 2023



Fast spin-echo (FSE) pulse sequences for Magnetic Resonance Imaging (MRI) offer important imaging contrast in clinically feasible scan times. T2-shuffling is widely used to resolve temporal signal dynamics in FSE acquisitions by exploiting temporal correlations via linear latent space and a predefined regularizer. However, predefined regularizers fail to exploit the incoherence especially for 2D acquisitions.Recent self-supervised learning methods achieve high-fidelity reconstructions by learning a regularizer from undersampled data without a standard supervised training data set. In this work, we propose a novel approach that utilizes a self supervised learning framework to learn a regularizer constrained on a linear latent space which improves time-resolved FSE images reconstruction quality. Additionally, in regimes without groundtruth sensitivity maps, we propose joint estimation of coil-sensitivity maps using an iterative reconstruction technique. Our technique functions is in a zero-shot fashion, as it only utilizes data from a single scan of highly undersampled time series images. We perform experiments on simulated and retrospective in-vivo data to evaluate the performance of the proposed zero-shot learning method for temporal FSE reconstruction. The results demonstrate the success of our proposed method where NMSE and SSIM are significantly increased and the artifacts are reduced.
Latent Signal Models: Learning Compact Representations of Signal Evolution for Improved Time-Resolved, Multi-contrast MRI
Aug 27, 2022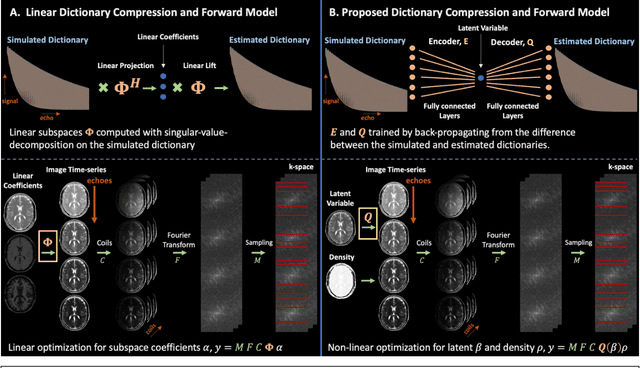
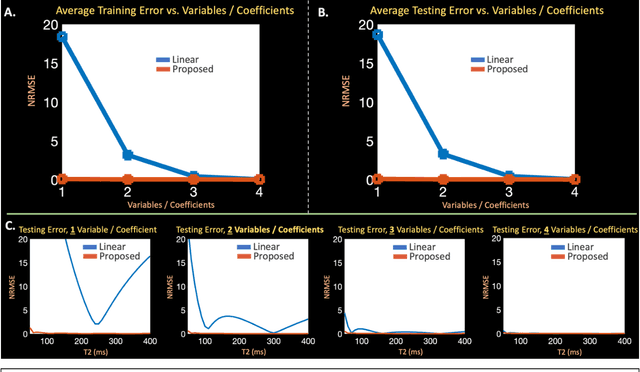
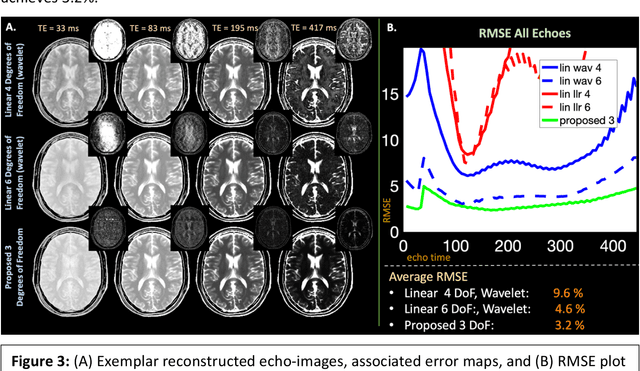
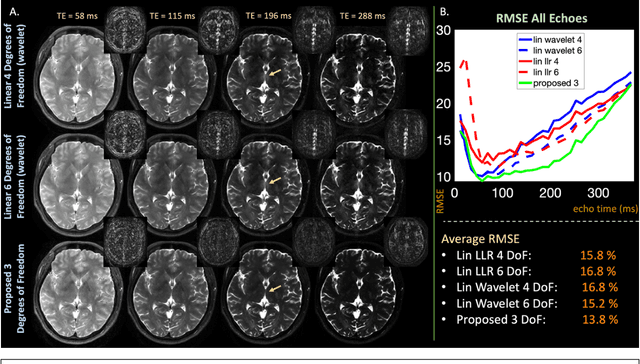
Purpose: Training auto-encoders on simulated signal evolution and inserting the decoder into the forward model improves reconstructions through more compact, Bloch-equation-based representations of signal in comparison to linear subspaces. Methods: Building on model-based nonlinear and linear subspace techniques that enable reconstruction of signal dynamics, we train auto-encoders on dictionaries of simulated signal evolution to learn more compact, non-linear, latent representations. The proposed Latent Signal Model framework inserts the decoder portion of the auto-encoder into the forward model and directly reconstructs the latent representation. Latent Signal Models essentially serve as a proxy for fast and feasible differentiation through the Bloch-equations used to simulate signal. This work performs experiments in the context of T2-shuffling, gradient echo EPTI, and MPRAGE-shuffling. We compare how efficiently auto-encoders represent signal evolution in comparison to linear subspaces. Simulation and in-vivo experiments then evaluate if reducing degrees of freedom by inserting the decoder into the forward model improves reconstructions in comparison to subspace constraints. Results: An auto-encoder with one real latent variable represents FSE, EPTI, and MPRAGE signal evolution as well as linear subspaces characterized by four basis vectors. In simulated/in-vivo T2-shuffling and in-vivo EPTI experiments, the proposed framework achieves consistent quantitative NRMSE and qualitative improvement over linear approaches. From qualitative evaluation, the proposed approach yields images with reduced blurring and noise amplification in MPRAGE shuffling experiments. Conclusion: Directly solving for non-linear latent representations of signal evolution improves time-resolved MRI reconstructions through reduced degrees of freedom.
Predicting Critical Biogeochemistry of the Southern Ocean for Climate Monitoring
Oct 30, 2021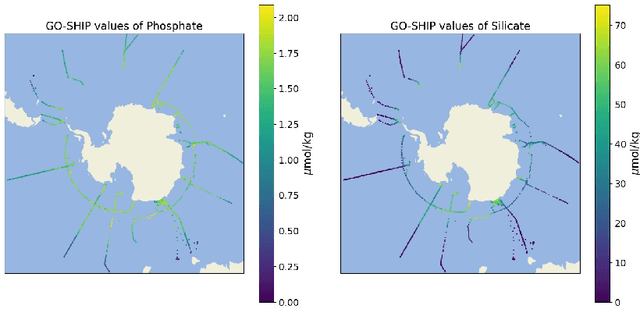
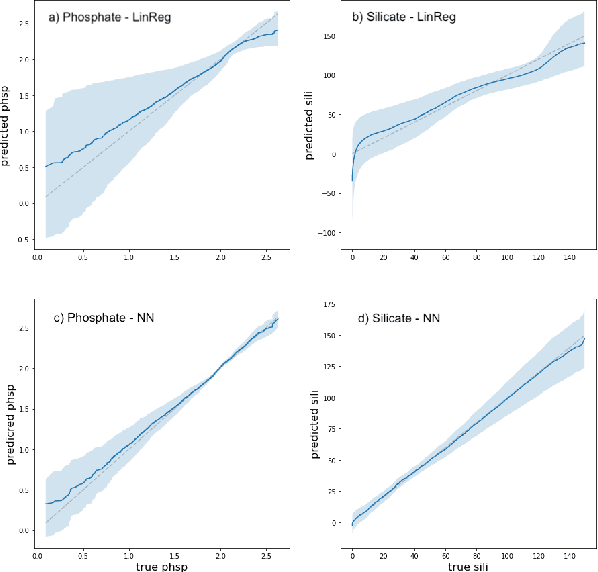
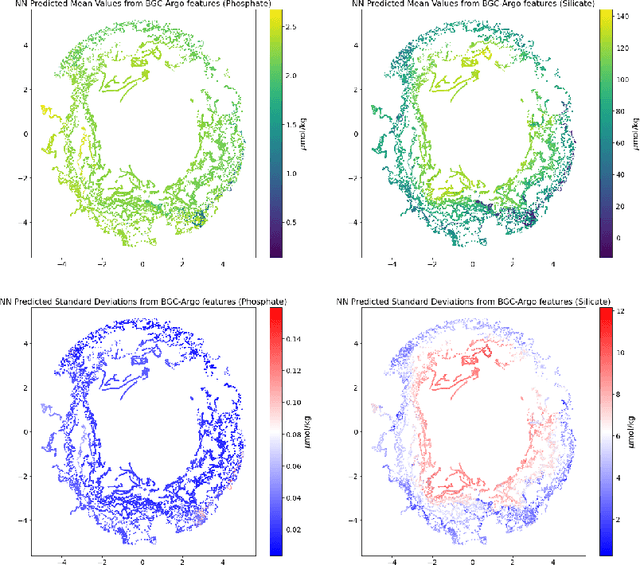
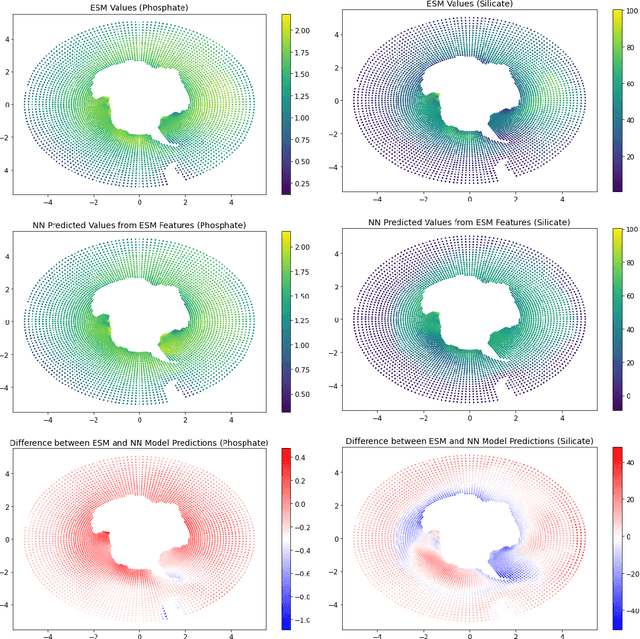
The Biogeochemical-Argo (BGC-Argo) program is building a network of globally distributed, sensor-equipped robotic profiling floats, improving our understanding of the climate system and how it is changing. These floats, however, are limited in the number of variables measured. In this study, we train neural networks to predict silicate and phosphate values in the Southern Ocean from temperature, pressure, salinity, oxygen, nitrate, and location and apply these models to earth system model (ESM) and BGC-Argo data to expand the utility of this ocean observation network. We trained our neural networks on observations from the Global Ocean Ship-Based Hydrographic Investigations Program (GO-SHIP) and use dropout regularization to provide uncertainty bounds around our predicted values. Our neural network significantly improves upon linear regression but shows variable levels of uncertainty across the ranges of predicted variables. We explore the generalization of our estimators to test data outside our training distribution from both ESM and BGC-Argo data. Our use of out-of-distribution test data to examine shifts in biogeochemical parameters and calculate uncertainty bounds around estimates advance the state-of-the-art in oceanographic data and climate monitoring. We make our data and code publicly available.
* 6 pages, 4 figures
Image2Lego: Customized LEGO Set Generation from Images
Aug 19, 2021

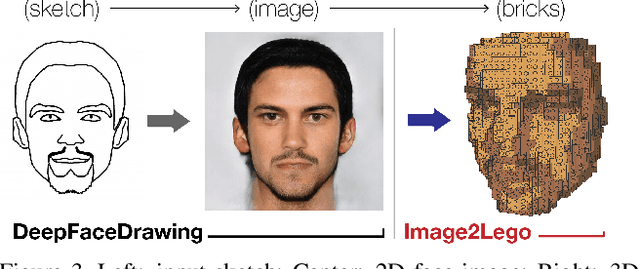
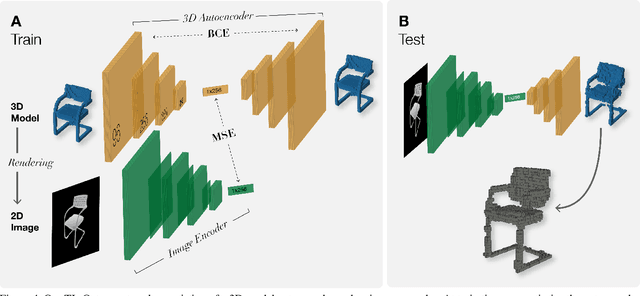
Although LEGO sets have entertained generations of children and adults, the challenge of designing customized builds matching the complexity of real-world or imagined scenes remains too great for the average enthusiast. In order to make this feat possible, we implement a system that generates a LEGO brick model from 2D images. We design a novel solution to this problem that uses an octree-structured autoencoder trained on 3D voxelized models to obtain a feasible latent representation for model reconstruction, and a separate network trained to predict this latent representation from 2D images. LEGO models are obtained by algorithmic conversion of the 3D voxelized model to bricks. We demonstrate first-of-its-kind conversion of photographs to 3D LEGO models. An octree architecture enables the flexibility to produce multiple resolutions to best fit a user's creative vision or design needs. In order to demonstrate the broad applicability of our system, we generate step-by-step building instructions and animations for LEGO models of objects and human faces. Finally, we test these automatically generated LEGO sets by constructing physical builds using real LEGO bricks.