 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard Constraints Meet Soft Generation: Guaranteed Feasibility for LLM-based Combinatorial Optimization
Feb 01, 2026Large language models (LLMs) have emerged as promising general-purpose solvers for combinatorial optimization (CO), yet they fundamentally lack mechanisms to guarantee solution feasibility which is critical for real-world deployment. In this work, we introduce FALCON, a framework that ensures 100\% feasibility through three key innovations: (i) \emph{grammar-constrained decoding} enforces syntactic validity, (ii) a \emph{feasibility repair layer} corrects semantic constraint violations, and (iii) \emph{adaptive Best-of-$N$ sampling} allocates inference compute efficiently. To train the underlying LLM, we introduce the Best-anchored Objective-guided Preference Optimization (BOPO) in LLM training, which weights preference pairs by their objective gap, providing dense supervision without human labels. Theoretically, we prove convergence for BOPO and provide bounds on repair-induced quality loss. Empirically, across seven NP-hard CO problems, FALCON achieves perfect feasibility while matching or exceeding the solution quality of state-of-the-art neural and LLM-based solvers.
Learning to Retrieve for Job Matching
Feb 21, 2024



Web-scale search systems typically tackle the scalability challenge with a two-step paradigm: retrieval and ranking. The retrieval step, also known as candidate selection, often involves extracting standardized entities, creating an inverted index, and performing term matching for retrieval. Such traditional methods require manual and time-consuming development of query models. In this paper, we discuss applying learning-to-retrieve technology to enhance LinkedIns job search and recommendation systems. In the realm of promoted jobs, the key objective is to improve the quality of applicants, thereby delivering value to recruiter customers. To achieve this, we leverage confirmed hire data to construct a graph that evaluates a seeker's qualification for a job, and utilize learned links for retrieval. Our learned model is easy to explain, debug, and adjust. On the other hand, the focus for organic jobs is to optimize seeker engagement. We accomplished this by training embeddings for personalized retrieval, fortified by a set of rules derived from the categorization of member feedback. In addition to a solution based on a conventional inverted index, we developed an on-GPU solution capable of supporting both KNN and term matching efficiently.
Self Supervised Learning for Improved Calibrationless Radial MRI with NLINV-Net
Feb 09, 2024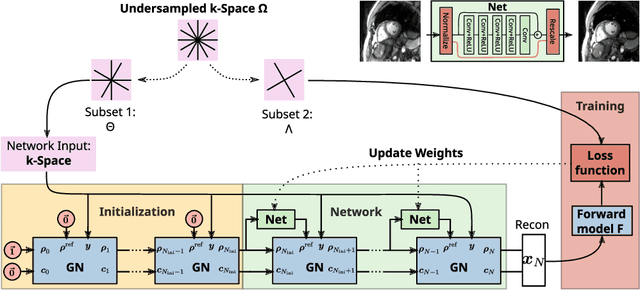
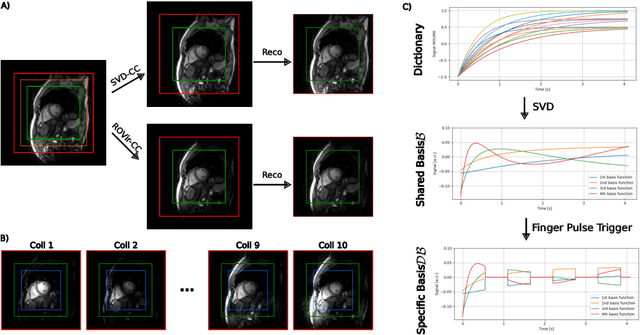
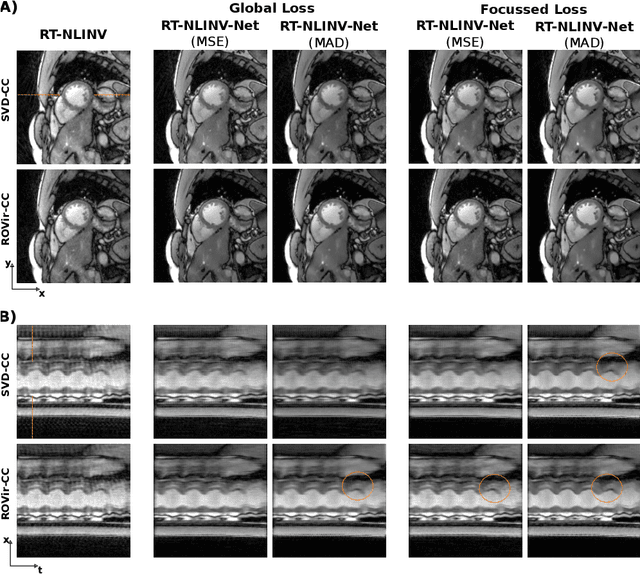
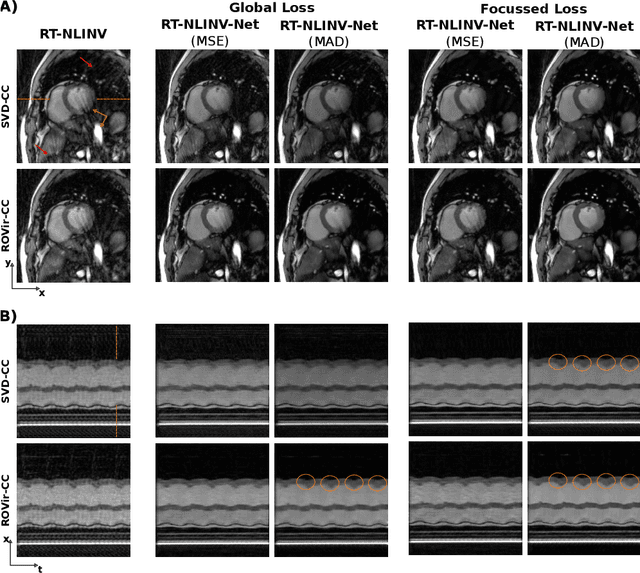
Purpose: To develop a neural network architecture for improved calibrationless reconstruction of radial data when no ground truth is available for training. Methods: NLINV-Net is a model-based neural network architecture that directly estimates images and coil sensitivities from (radial) k-space data via non-linear inversion (NLINV). Combined with a training strategy using self-supervision via data undersampling (SSDU), it can be used for imaging problems where no ground truth reconstructions are available. We validated the method for (1) real-time cardiac imaging and (2) single-shot subspace-based quantitative T1 mapping. Furthermore, region-optimized virtual (ROVir) coils were used to suppress artifacts stemming from outside the FoV and to focus the k-space based SSDU loss on the region of interest. NLINV-Net based reconstructions were compared with conventional NLINV and PI-CS (parallel imaging + compressed sensing) reconstruction and the effect of the region-optimized virtual coils and the type of training loss was evaluated qualitatively. Results: NLINV-Net based reconstructions contain significantly less noise than the NLINV-based counterpart. ROVir coils effectively suppress streakings which are not suppressed by the neural networks while the ROVir-based focussed loss leads to visually sharper time series for the movement of the myocardial wall in cardiac real-time imaging. For quantitative imaging, T1-maps reconstructed using NLINV-Net show similar quality as PI-CS reconstructions, but NLINV-Net does not require slice-specific tuning of the regularization parameter. Conclusion: NLINV-Net is a versatile tool for calibrationless imaging which can be used in challenging imaging scenarios where a ground truth is not available.
Improved Multi-Shot Diffusion-Weighted MRI with Zero-Shot Self-Supervised Learning Reconstruction
Aug 09, 2023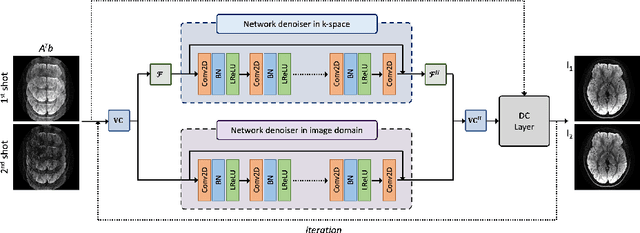
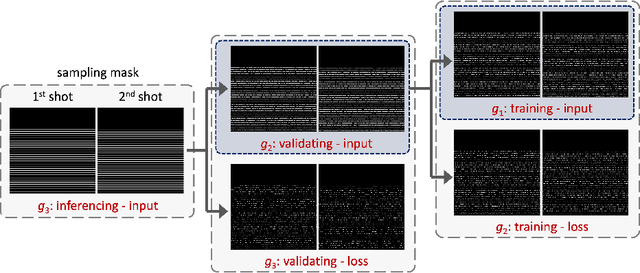
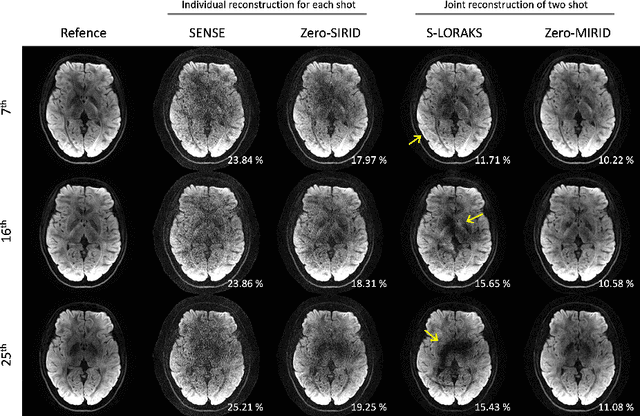

Diffusion MRI is commonly performed using echo-planar imaging (EPI) due to its rapid acquisition time. However, the resolution of diffusion-weighted images is often limited by magnetic field inhomogeneity-related artifacts and blurring induced by T2- and T2*-relaxation effects. To address these limitations, multi-shot EPI (msEPI) combined with parallel imaging techniques is frequently employed. Nevertheless, reconstructing msEPI can be challenging due to phase variation between multiple shots. In this study, we introduce a novel msEPI reconstruction approach called zero-MIRID (zero-shot self-supervised learning of Multi-shot Image Reconstruction for Improved Diffusion MRI). This method jointly reconstructs msEPI data by incorporating deep learning-based image regularization techniques. The network incorporates CNN denoisers in both k- and image-spaces, while leveraging virtual coils to enhance image reconstruction conditioning. By employing a self-supervised learning technique and dividing sampled data into three groups, the proposed approach achieves superior results compared to the state-of-the-art parallel imaging method, as demonstrated in an in-vivo experiment.
Generative Image Priors for MRI Reconstruction Trained from Magnitude-Only Images
Aug 04, 2023



Purpose: In this work, we present a workflow to construct generic and robust generative image priors from magnitude-only images. The priors can then be used for regularization in reconstruction to improve image quality. Methods: The workflow begins with the preparation of training datasets from magnitude-only MR images. This dataset is then augmented with phase information and used to train generative priors of complex images. Finally, trained priors are evaluated using both linear and nonlinear reconstruction for compressed sensing parallel imaging with various undersampling schemes. Results: The results of our experiments demonstrate that priors trained on complex images outperform priors trained only on magnitude images. Additionally, a prior trained on a larger dataset exhibits higher robustness. Finally, we show that the generative priors are superior to L1 -wavelet regularization for compressed sensing parallel imaging with high undersampling. Conclusion: These findings stress the importance of incorporating phase information and leveraging large datasets to raise the performance and reliability of the generative priors for MRI reconstruction. Phase augmentation makes it possible to use existing image databases for training.
Zero-DeepSub: Zero-Shot Deep Subspace Reconstruction for Rapid Multiparametric Quantitative MRI Using 3D-QALAS
Jul 04, 2023Purpose: To develop and evaluate methods for 1) reconstructing 3D-quantification using an interleaved Look-Locker acquisition sequence with T2 preparation pulse (3D-QALAS) time-series images using a low-rank subspace method, which enables accurate and rapid T1 and T2 mapping, and 2) improving the fidelity of subspace QALAS by combining scan-specific deep-learning-based reconstruction and subspace modeling. Methods: A low-rank subspace method for 3D-QALAS (i.e., subspace QALAS) and zero-shot deep-learning subspace method (i.e., Zero-DeepSub) were proposed for rapid and high fidelity T1 and T2 mapping and time-resolved imaging using 3D-QALAS. Using an ISMRM/NIST system phantom, the accuracy of the T1 and T2 maps estimated using the proposed methods was evaluated by comparing them with reference techniques. The reconstruction performance of the proposed subspace QALAS using Zero-DeepSub was evaluated in vivo and compared with conventional QALAS at high reduction factors of up to 9-fold. Results: Phantom experiments showed that subspace QALAS had good linearity with respect to the reference methods while reducing biases compared to conventional QALAS, especially for T2 maps. Moreover, in vivo results demonstrated that subspace QALAS had better g-factor maps and could reduce voxel blurring, noise, and artifacts compared to conventional QALAS and showed robust performance at up to 9-fold acceleration with Zero-DeepSub, which enabled whole-brain T1, T2, and PD mapping at 1 mm isotropic resolution within 2 min of scan time. Conclusion: The proposed subspace QALAS along with Zero-DeepSub enabled high fidelity and rapid whole-brain multiparametric quantification and time-resolved imaging.
SSL-QALAS: Self-Supervised Learning for Rapid Multiparameter Estimation in Quantitative MRI Using 3D-QALAS
Feb 28, 2023Purpose: To develop and evaluate a method for rapid estimation of multiparametric T1, T2, proton density (PD), and inversion efficiency (IE) maps from 3D-quantification using an interleaved Look-Locker acquisition sequence with T2 preparation pulse (3D-QALAS) measurements using self-supervised learning (SSL) without the need for an external dictionary. Methods: A SSL-based QALAS mapping method (SSL-QALAS) was developed for rapid and dictionary-free estimation of multiparametric maps from 3D-QALAS measurements. The accuracy of the reconstructed quantitative maps using dictionary matching and SSL-QALAS was evaluated by comparing the estimated T1 and T2 values with those obtained from the reference methods on an ISMRM/NIST phantom. The SSL-QALAS and the dictionary matching methods were also compared in vivo, and generalizability was evaluated by comparing the scan-specific, pre-trained, and transfer learning models. Results: Phantom experiments showed that both the dictionary matching and SSL-QALAS methods produced T1 and T2 estimates that had a strong linear agreement with the reference values in the ISMRM/NIST phantom. Further, SSL-QALAS showed similar performance with dictionary matching in reconstructing the T1, T2, PD, and IE maps on in vivo data. Rapid reconstruction of multiparametric maps was enabled by inferring the data using a pre-trained SSL-QALAS model within 10 s. Fast scan-specific tuning was also demonstrated by fine-tuning the pre-trained model with the target subject's data within 15 min. Conclusion: The proposed SSL-QALAS method enabled rapid reconstruction of multiparametric maps from 3D-QALAS measurements without an external dictionary or labeled ground-truth training data.
WKGM: Weight-K-space Generative Model for Parallel Imaging Reconstruction
May 08, 2022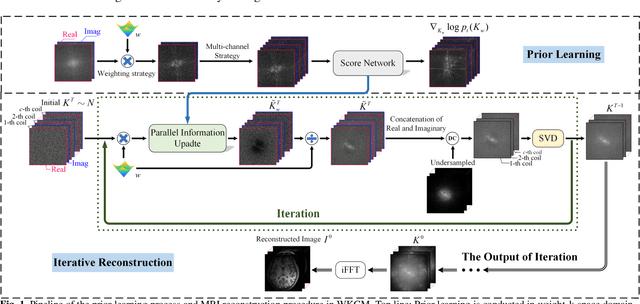

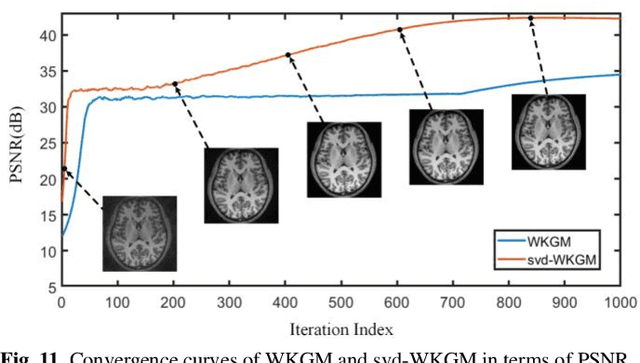
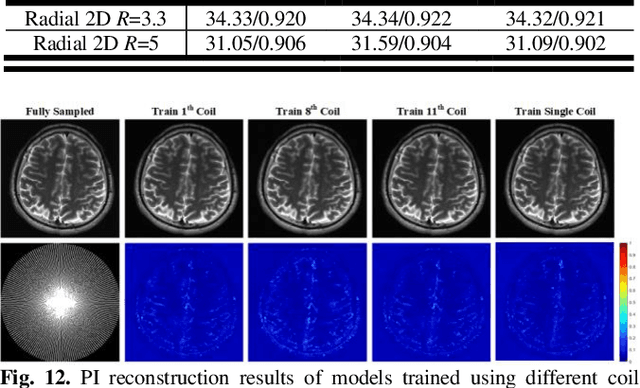
Parallel Imaging (PI) is one of the most im-portant and successful developments in accelerating magnetic resonance imaging (MRI). Recently deep learning PI has emerged as an effective technique to accelerate MRI. Nevertheless, most approaches have so far been based image domain. In this work, we propose to explore the k-space domain via robust generative modeling for flexible PI reconstruction, coined weight-k-space generative model (WKGM). Specifically, WKGM is a generalized k-space domain model, where the k-space weighting technology and high-dimensional space strategy are efficiently incorporated for score-based generative model training, resulting in good and robust reconstruction. In addition, WKGM is flexible and thus can synergistically combine various traditional k-space PI models, generating learning-based priors to produce high-fidelity reconstructions. Experimental results on datasets with varying sampling patterns and acceleration factors demonstrate that WKGM can attain state-of-the-art reconstruction results under the well-learned k-space generative prior.
Free-Breathing Water, Fat, $R_2^{\star}$ and $B_0$ Field Mapping of the Liver Using Multi-Echo Radial FLASH and Regularized Model-based Reconstruction
Jan 07, 2021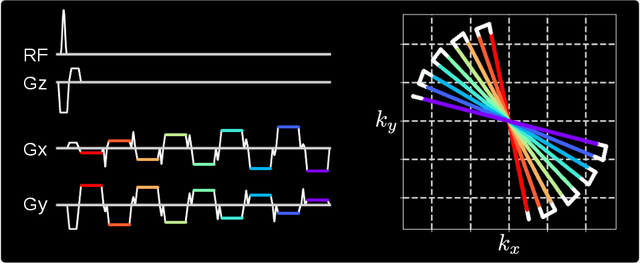
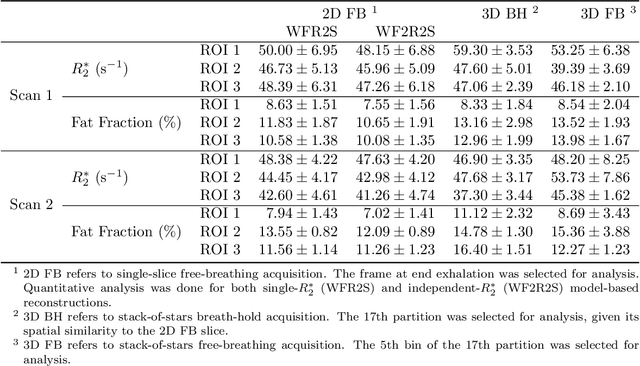
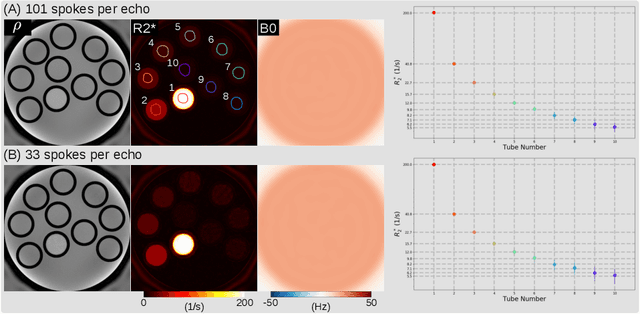
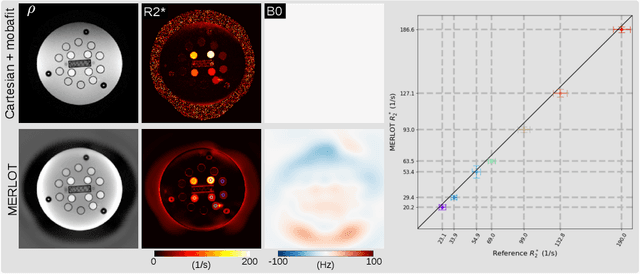
Purpose: To achieve free-breathing quantitative fat and $R_2^{\star}$ mapping of the liver using a generalized model-based iterative reconstruction, dubbed as MERLOT. Methods: For acquisition, we use a multi-echo radial FLASH sequence that acquires multiple echoes with different complementary radial spoke encodings. We investigate real-time single-slice and volumetric multi-echo radial FLASH acquisition. For the latter, the sampling scheme is extended to a volumetric stack-of-stars acquisition. Model-based reconstruction based on generalized nonlinear inversion is used to jointly estimate water, fat, $R_2^{\star}$, $B_0$ field inhomogeneity, and coil sensitivity maps from the multi-coil multi-echo radial spokes. Spatial smoothness regularization is applied onto the B 0 field and coil sensitivity maps, whereas joint sparsity regularization is employed for the other parameter maps. The method integrates calibration-less parallel imaging and compressed sensing and was implemented in BART. For the volumetric acquisition, the respiratory motion is resolved with self-gating using SSA-FARY. The quantitative accuracy of the proposed method was validated via numerical simulation, the NIST phantom, a water/fat phantom, and in in-vivo liver studies. Results: For real-time acquisition, the proposed model-based reconstruction allowed acquisition of dynamic liver fat fraction and $R_2^{\star}$ maps at a temporal resolution of 0.3 s per frame. For the volumetric acquisition, whole liver coverage could be achieved in under 2 minutes using the self-gated motion-resolved reconstruction. Conclusion: The proposed multi-echo radial sampling sequence achieves fast k -space coverage and is robust to motion. The proposed model-based reconstruction yields spatially and temporally resolved liver fat fraction, $R_2^{\star}$ and $B_0$ field maps at high undersampling factor and with volume coverage.
Dynamic Pricing on E-commerce Platform with Deep Reinforcement Learning
Dec 05, 2019
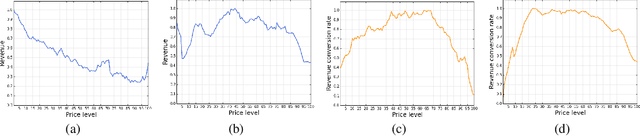
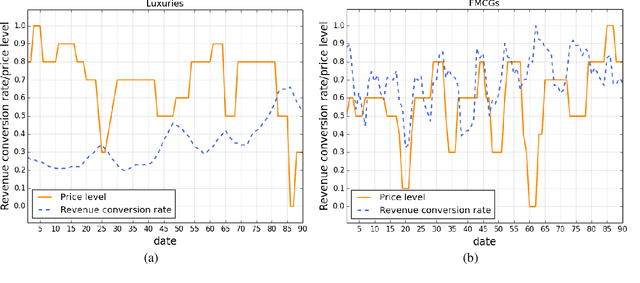

In this paper we present an end-to-end framework for addressing the problem of dynamic pricing on E-commerce platform using methods based on deep reinforcement learning (DRL). By using four groups of different business data to represent the states of each time period, we model the dynamic pricing problem as a Markov Decision Process (MDP). Compared with the state-of-the-art DRL-based dynamic pricing algorithms, our approaches make the following three contributions. First, we extend the discrete set problem to the continuous price set. Second, instead of using revenue as the reward function directly, we define a new function named difference of revenue conversion rates (DRCR). Third, the cold-start problem of MDP is tackled by pre-training and evaluation using some carefully chosen historical sales data. Our approaches are evaluated by both offline evaluation method using real dataset of Alibaba Inc., and online field experiments on Tmall.com, a major online shopping website owned by Alibaba Inc.. In particular, experiment results suggest that DRCR is a more appropriate reward function than revenue, which is widely used by current literature. In the end, field experiments, which last for months on 1000 stock keeping units (SKUs) of products demonstrate that continuous price sets have better performance than discrete sets and show that our approaches significantly outperformed the manual pricing by operation experts.