 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of Deep Learning Segmentation for Real-Time Free-Breathing Cardiac Magnetic Resonance Imaging
Dec 01, 2023In recent years, a variety of deep learning networks for cardiac MRI (CMR) segmentation have been developed and analyzed. However, nearly all of them are focused on cine CMR under breathold. In this work, accuracy of deep learning methods is assessed for volumetric analysis (via segmentation) of the left ventricle in real-time free-breathing CMR at rest and under exercise stress. Data from healthy volunteers (n=15) for cine and real-time free-breathing CMR were analyzed retrospectively. Segmentations of a commercial software (comDL) and a freely available neural network (nnU-Net), were compared to a reference created via the manual correction of comDL segmentation. Segmentation of left ventricular endocardium (LV), left ventricular myocardium (MYO), and right ventricle (RV) is evaluated for both end-systolic and end-diastolic phases and analyzed with Dice's coefficient (DC). The volumetric analysis includes LV end-diastolic volume (EDV), LV end-systolic volume (ESV), and LV ejection fraction (EF). For cine CMR, nnU-Net and comDL achieve a DC above 0.95 for LV and 0.9 for MYO, and RV. For real-time CMR, the accuracy of nnU-Net exceeds that of comDL overall. For real-time CMR at rest, nnU-Net achieves a DC of 0.94 for LV, 0.89 for MYO, and 0.90 for RV; mean absolute differences between nnU-Net and reference are 2.9mL for EDV, 3.5mL for ESV and 2.6% for EF. For real-time CMR under exercise stress, nnU-Net achieves a DC of 0.92 for LV, 0.85 for MYO, and 0.83 for RV; mean absolute differences between nnU-Net and reference are 11.4mL for EDV, 2.9mL for ESV and 3.6% for EF. Deep learning methods designed or trained for cine CMR segmentation can perform well on real-time CMR. For real-time free-breathing CMR at rest, the performance of deep learning methods is comparable to inter-observer variability in cine CMR and is usable or fully automatic segmentation.
Generative Image Priors for MRI Reconstruction Trained from Magnitude-Only Images
Aug 04, 2023



Purpose: In this work, we present a workflow to construct generic and robust generative image priors from magnitude-only images. The priors can then be used for regularization in reconstruction to improve image quality. Methods: The workflow begins with the preparation of training datasets from magnitude-only MR images. This dataset is then augmented with phase information and used to train generative priors of complex images. Finally, trained priors are evaluated using both linear and nonlinear reconstruction for compressed sensing parallel imaging with various undersampling schemes. Results: The results of our experiments demonstrate that priors trained on complex images outperform priors trained only on magnitude images. Additionally, a prior trained on a larger dataset exhibits higher robustness. Finally, we show that the generative priors are superior to L1 -wavelet regularization for compressed sensing parallel imaging with high undersampling. Conclusion: These findings stress the importance of incorporating phase information and leveraging large datasets to raise the performance and reliability of the generative priors for MRI reconstruction. Phase augmentation makes it possible to use existing image databases for training.
Deep, Deep Learning with BART
Feb 28, 2022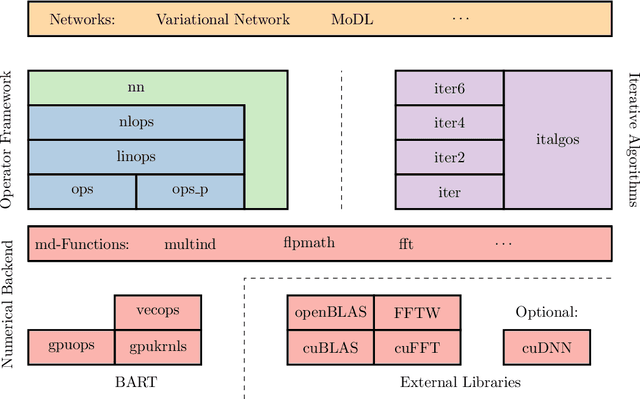
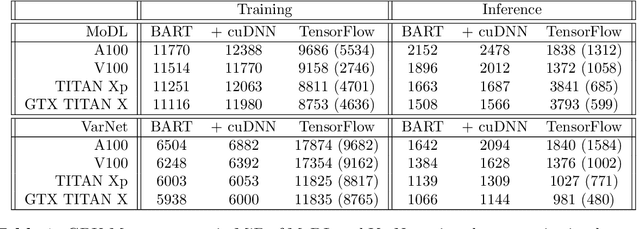
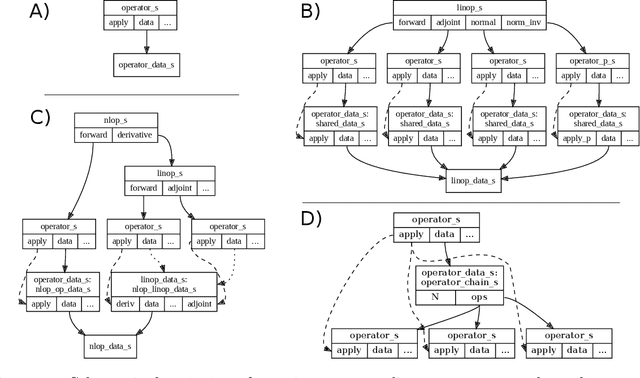
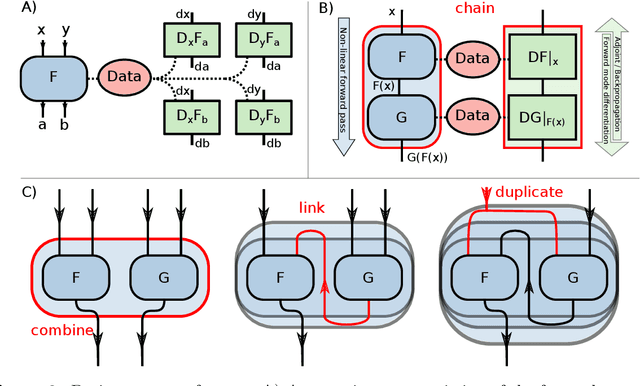
Purpose: To develop a deep-learning-based image reconstruction framework for reproducible research in MRI. Methods: The BART toolbox offers a rich set of implementations of calibration and reconstruction algorithms for parallel imaging and compressed sensing. In this work, BART was extended by a non-linear operator framework that provides automatic differentiation to allow computation of gradients. Existing MRI-specific operators of BART, such as the non-uniform fast Fourier transform, are directly integrated into this framework and are complemented by common building blocks used in neural networks. To evaluate the use of the framework for advanced deep-learning-based reconstruction, two state-of-the-art unrolled reconstruction networks, namely the Variational Network [1] and MoDL [2], were implemented. Results: State-of-the-art deep image-reconstruction networks can be constructed and trained using BART's gradient based optimization algorithms. The BART implementation achieves a similar performance in terms of training time and reconstruction quality compared to the original implementations based on TensorFlow. Conclusion: By integrating non-linear operators and neural networks into BART, we provide a general framework for deep-learning-based reconstruction in MRI.