 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDT2: Exploring the Scaling Limit of UMI Data Towards Zero-Shot Cross-Embodiment Generalization
Feb 03, 2026Vision-Language-Action (VLA) models hold promise for generalist robotics but currently struggle with data scarcity, architectural inefficiencies, and the inability to generalize across different hardware platforms. We introduce RDT2, a robotic foundation model built upon a 7B parameter VLM designed to enable zero-shot deployment on novel embodiments for open-vocabulary tasks. To achieve this, we collected one of the largest open-source robotic datasets--over 10,000 hours of demonstrations in diverse families--using an enhanced, embodiment-agnostic Universal Manipulation Interface (UMI). Our approach employs a novel three-stage training recipe that aligns discrete linguistic knowledge with continuous control via Residual Vector Quantization (RVQ), flow-matching, and distillation for real-time inference. Consequently, RDT2 becomes one of the first models that simultaneously zero-shot generalizes to unseen objects, scenes, instructions, and even robotic platforms. Besides, it outperforms state-of-the-art baselines in dexterous, long-horizon, and dynamic downstream tasks like playing table tennis. See https://rdt-robotics.github.io/rdt2/ for more information.
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Oct 10, 2024



Bimanual manipulation is essential in robotics, yet developing foundation models is extremely challenging due to the inherent complexity of coordinating two robot arms (leading to multi-modal action distributions) and the scarcity of training data. In this paper, we present the Robotics Diffusion Transformer (RDT), a pioneering diffusion foundation model for bimanual manipulation. RDT builds on diffusion models to effectively represent multi-modality, with innovative designs of a scalable Transformer to deal with the heterogeneity of multi-modal inputs and to capture the nonlinearity and high frequency of robotic data. To address data scarcity, we further introduce a Physically Interpretable Unified Action Space, which can unify the action representations of various robots while preserving the physical meanings of original actions, facilitating learning transferrable physical knowledge. With these designs, we managed to pre-train RDT on the largest collection of multi-robot datasets to date and scaled it up to 1.2B parameters, which is the largest diffusion-based foundation model for robotic manipulation. We finally fine-tuned RDT on a self-created multi-task bimanual dataset with over 6K+ episodes to refine its manipulation capabilities. Experiments on real robots demonstrate that RDT significantly outperforms existing methods. It exhibits zero-shot generalization to unseen objects and scenes, understands and follows language instructions, learns new skills with just 1~5 demonstrations, and effectively handles complex, dexterous tasks. We refer to https://rdt-robotics.github.io/rdt-robotics/ for the code and videos.
Embodied Active Defense: Leveraging Recurrent Feedback to Counter Adversarial Patches
Mar 31, 2024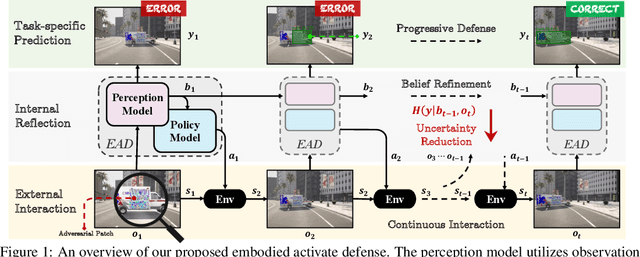



The vulnerability of deep neural networks to adversarial patches has motivated numerous defense strategies for boosting model robustness. However, the prevailing defenses depend on single observation or pre-established adversary information to counter adversarial patches, often failing to be confronted with unseen or adaptive adversarial attacks and easily exhibiting unsatisfying performance in dynamic 3D environments. Inspired by active human perception and recurrent feedback mechanisms, we develop Embodied Active Defense (EAD), a proactive defensive strategy that actively contextualizes environmental information to address misaligned adversarial patches in 3D real-world settings. To achieve this, EAD develops two central recurrent sub-modules, i.e., a perception module and a policy module, to implement two critical functions of active vision. These models recurrently process a series of beliefs and observations, facilitating progressive refinement of their comprehension of the target object and enabling the development of strategic actions to counter adversarial patches in 3D environments. To optimize learning efficiency, we incorporate a differentiable approximation of environmental dynamics and deploy patches that are agnostic to the adversary strategies. Extensive experiments demonstrate that EAD substantially enhances robustness against a variety of patches within just a few steps through its action policy in safety-critical tasks (e.g., face recognition and object detection), without compromising standard accuracy. Furthermore, due to the attack-agnostic characteristic, EAD facilitates excellent generalization to unseen attacks, diminishing the averaged attack success rate by 95 percent across a range of unseen adversarial attacks.