 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2VParser: Adaptive Decomposition Tokens for Partial Alignment in Text to Video Retrieval
Jul 28, 2025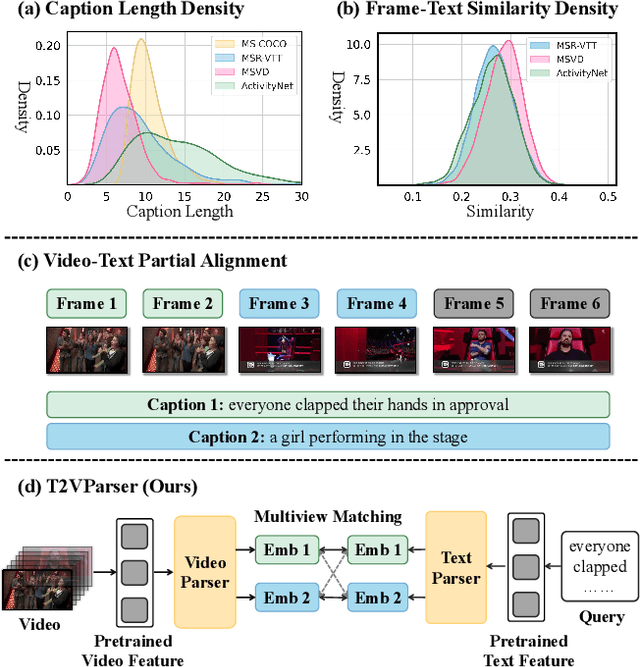
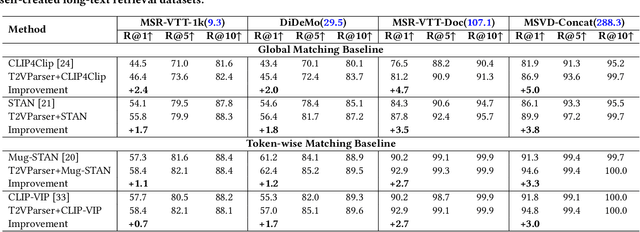
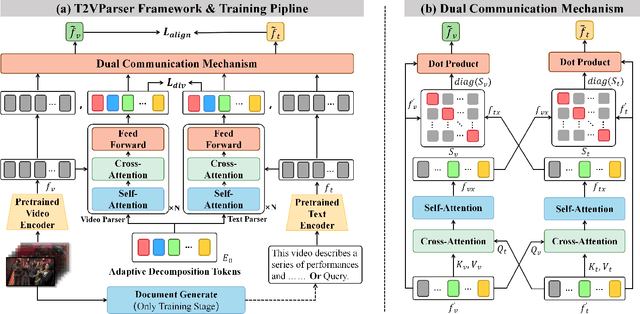
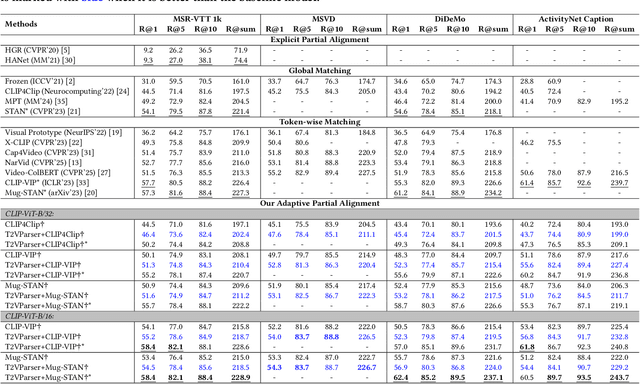
Text-to-video retrieval essentially aims to train models to align visual content with textual descriptions accurately. Due to the impressive general multimodal knowledge demonstrated by image-text pretrained models such as CLIP, existing work has primarily focused on extending CLIP knowledge for video-text tasks. However, videos typically contain richer information than images. In current video-text datasets, textual descriptions can only reflect a portion of the video content, leading to partial misalignment in video-text matching. Therefore, directly aligning text representations with video representations can result in incorrect supervision, ignoring the inequivalence of information. In this work, we propose T2VParser to extract multiview semantic representations from text and video, achieving adaptive semantic alignment rather than aligning the entire representation. To extract corresponding representations from different modalities, we introduce Adaptive Decomposition Tokens, which consist of a set of learnable tokens shared across modalities. The goal of T2VParser is to emphasize precise alignment between text and video while retaining the knowledge of pretrained models. Experimental results demonstrate that T2VParser achieves accurate partial alignment through effective cross-modal content decomposition. The code is available at https://github.com/Lilidamowang/T2VParser.
MADS: Multi-Attribute Document Supervision for Zero-Shot Image Classification
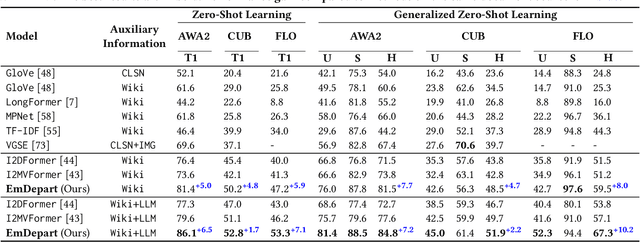
Mar 10, 2025Zero-shot learning (ZSL) aims to train a model on seen classes and recognize unseen classes by knowledge transfer through shared auxiliary information. Recent studies reveal that documents from encyclopedias provide helpful auxiliary information. However, existing methods align noisy documents, entangled in visual and non-visual descriptions, with image regions, yet solely depend on implicit learning. These models fail to filter non-visual noise reliably and incorrectly align non-visual words to image regions, which is harmful to knowledge transfer. In this work, we propose a novel multi-attribute document supervision framework to remove noises at both document collection and model learning stages. With the help of large language models, we introduce a novel prompt algorithm that automatically removes non-visual descriptions and enriches less-described documents in multiple attribute views. Our proposed model, MADS, extracts multi-view transferable knowledge with information decoupling and semantic interactions for semantic alignment at local and global levels. Besides, we introduce a model-agnostic focus loss to explicitly enhance attention to visually discriminative information during training, also improving existing methods without additional parameters. With comparable computation costs, MADS consistently outperforms the SOTA by 7.2% and 8.2% on average in three benchmarks for document-based ZSL and GZSL settings, respectively. Moreover, we qualitatively offer interpretable predictions from multiple attribute views.
ProAPO: Progressively Automatic Prompt Optimization for Visual Classification
Feb 27, 2025
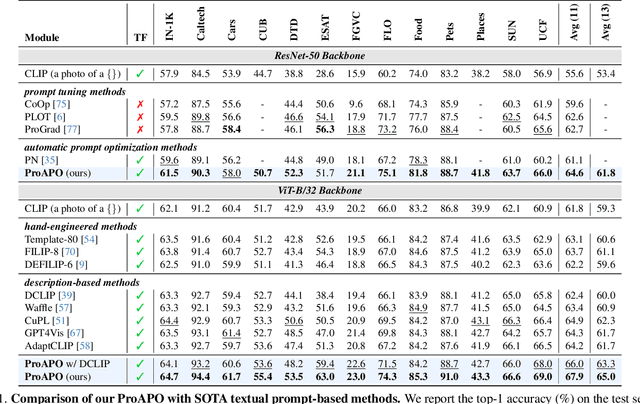
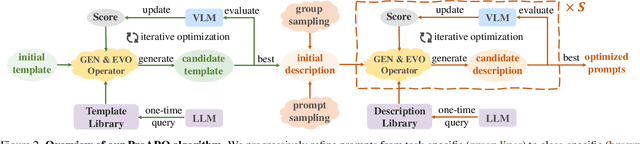
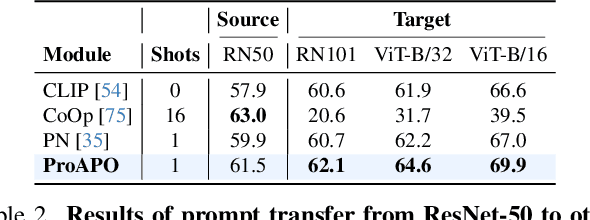
Vision-language models (VLMs) have made significant progress in image classification by training with large-scale paired image-text data. Their performances largely depend on the prompt quality. While recent methods show that visual descriptions generated by large language models (LLMs) enhance the generalization of VLMs, class-specific prompts may be inaccurate or lack discrimination due to the hallucination in LLMs. In this paper, we aim to find visually discriminative prompts for fine-grained categories with minimal supervision and no human-in-the-loop. An evolution-based algorithm is proposed to progressively optimize language prompts from task-specific templates to class-specific descriptions. Unlike optimizing templates, the search space shows an explosion in class-specific candidate prompts. This increases prompt generation costs, iterative times, and the overfitting problem. To this end, we first introduce several simple yet effective edit-based and evolution-based operations to generate diverse candidate prompts by one-time query of LLMs. Then, two sampling strategies are proposed to find a better initial search point and reduce traversed categories, saving iteration costs. Moreover, we apply a novel fitness score with entropy constraints to mitigate overfitting. In a challenging one-shot image classification setting, our method outperforms existing textual prompt-based methods and improves LLM-generated description methods across 13 datasets. Meanwhile, we demonstrate that our optimal prompts improve adapter-based methods and transfer effectively across different backbones.
Visual-Semantic Decomposition and Partial Alignment for Document-based Zero-Shot Learning
Jul 23, 2024
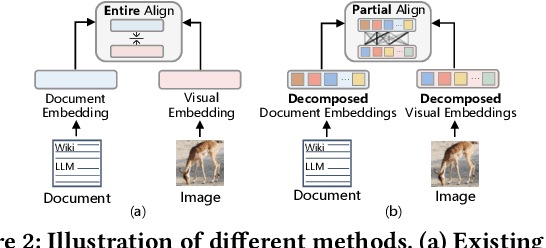
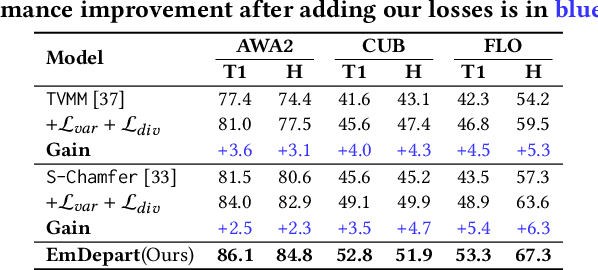
Recent work shows that documents from encyclopedias serve as helpful auxiliary information for zero-shot learning. Existing methods align the entire semantics of a document with corresponding images to transfer knowledge. However, they disregard that semantic information is not equivalent between them, resulting in a suboptimal alignment. In this work, we propose a novel network to extract multi-view semantic concepts from documents and images and align the matching rather than entire concepts. Specifically, we propose a semantic decomposition module to generate multi-view semantic embeddings from visual and textual sides, providing the basic concepts for partial alignment. To alleviate the issue of information redundancy among embeddings, we propose the local-to-semantic variance loss to capture distinct local details and multiple semantic diversity loss to enforce orthogonality among embeddings. Subsequently, two losses are introduced to partially align visual-semantic embedding pairs according to their semantic relevance at the view and word-to-patch levels. Consequently, we consistently outperform state-of-the-art methods under two document sources in three standard benchmarks for document-based zero-shot learning. Qualitatively, we show that our model learns the interpretable partial association.
Watermarking Vision-Language Pre-trained Models for Multi-modal Embedding as a Service
Nov 10, 2023



Recent advances in vision-language pre-trained models (VLPs) have significantly increased visual understanding and cross-modal analysis capabilities. Companies have emerged to provide multi-modal Embedding as a Service (EaaS) based on VLPs (e.g., CLIP-based VLPs), which cost a large amount of training data and resources for high-performance service. However, existing studies indicate that EaaS is vulnerable to model extraction attacks that induce great loss for the owners of VLPs. Protecting the intellectual property and commercial ownership of VLPs is increasingly crucial yet challenging. A major solution of watermarking model for EaaS implants a backdoor in the model by inserting verifiable trigger embeddings into texts, but it is only applicable for large language models and is unrealistic due to data and model privacy. In this paper, we propose a safe and robust backdoor-based embedding watermarking method for VLPs called VLPMarker. VLPMarker utilizes embedding orthogonal transformation to effectively inject triggers into the VLPs without interfering with the model parameters, which achieves high-quality copyright verification and minimal impact on model performance. To enhance the watermark robustness, we further propose a collaborative copyright verification strategy based on both backdoor trigger and embedding distribution, enhancing resilience against various attacks. We increase the watermark practicality via an out-of-distribution trigger selection approach, removing access to the model training data and thus making it possible for many real-world scenarios. Our extensive experiments on various datasets indicate that the proposed watermarking approach is effective and safe for verifying the copyright of VLPs for multi-modal EaaS and robust against model extraction attacks. Our code is available at https://github.com/Pter61/vlpmarker.
Towards Fast and Accurate Image-Text Retrieval with Self-Supervised Fine-Grained Alignment
Aug 27, 2023



Image-text retrieval requires the system to bridge the heterogenous gap between vision and language for accurate retrieval while keeping the network lightweight-enough for efficient retrieval. Existing trade-off solutions mainly study from the view of incorporating cross-modal interactions with the independent-embedding framework or leveraging stronger pretrained encoders, which still demand time-consuming similarity measurement or heavyweight model structure in the retrieval stage. In this work, we propose an image-text alignment module SelfAlign on top of the independent-embedding framework, which improves the retrieval accuracy while maintains the retrieval efficiency without extra supervision. SelfAlign contains two collaborative sub-modules that force image-text alignment at both concept level and context level by self-supervised contrastive learning. It does not require cross-modal embedding interactions during training while maintaining independent image and text encoders during retrieval. With comparable time cost, SelfAlign consistently boosts the accuracy of state-of-the-art non-pretraining independent-embedding models respectively by 9.1%, 4.2% and 6.6% in terms of R@sum score on Flickr30K, MSCOCO 1K and MS-COCO 5K datasets. The retrieval accuracy also outperforms most existing interactive-embedding models with orders of magnitude decrease in retrieval time. The source code is available at: https://github.com/Zjamie813/SelfAlign.
* Accepted in IEEE Transactions on Multimedia (TMM)