 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2VParser: Adaptive Decomposition Tokens for Partial Alignment in Text to Video Retrieval
Jul 28, 2025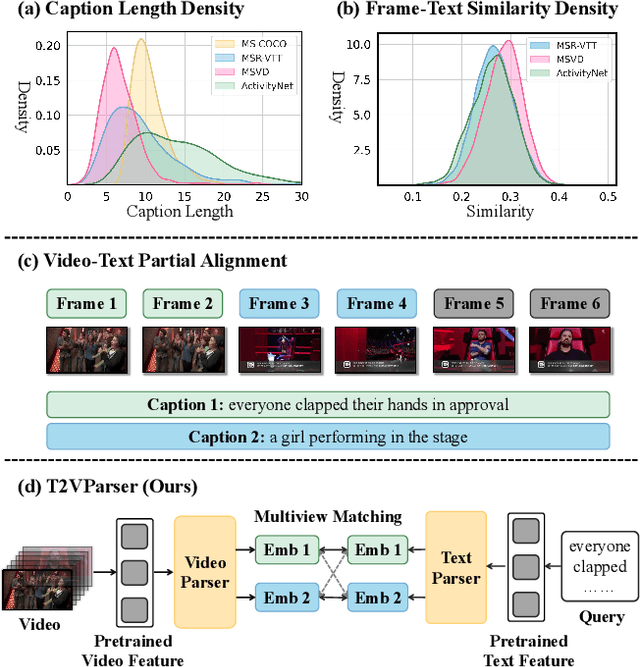
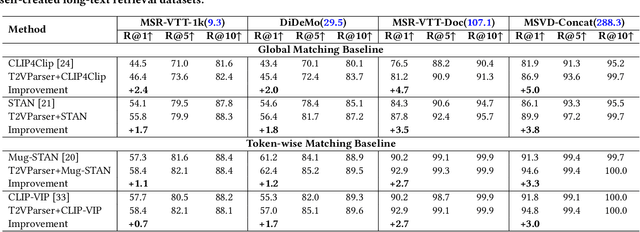
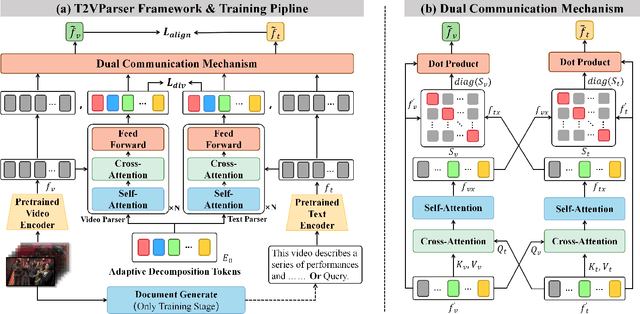
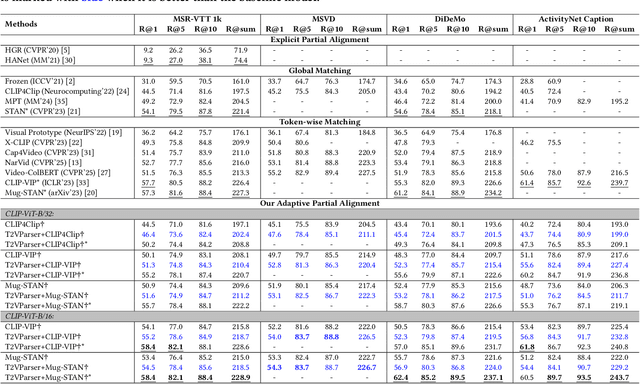
Text-to-video retrieval essentially aims to train models to align visual content with textual descriptions accurately. Due to the impressive general multimodal knowledge demonstrated by image-text pretrained models such as CLIP, existing work has primarily focused on extending CLIP knowledge for video-text tasks. However, videos typically contain richer information than images. In current video-text datasets, textual descriptions can only reflect a portion of the video content, leading to partial misalignment in video-text matching. Therefore, directly aligning text representations with video representations can result in incorrect supervision, ignoring the inequivalence of information. In this work, we propose T2VParser to extract multiview semantic representations from text and video, achieving adaptive semantic alignment rather than aligning the entire representation. To extract corresponding representations from different modalities, we introduce Adaptive Decomposition Tokens, which consist of a set of learnable tokens shared across modalities. The goal of T2VParser is to emphasize precise alignment between text and video while retaining the knowledge of pretrained models. Experimental results demonstrate that T2VParser achieves accurate partial alignment through effective cross-modal content decomposition. The code is available at https://github.com/Lilidamowang/T2VParser.
ProAPO: Progressively Automatic Prompt Optimization for Visual Classification
Feb 27, 2025
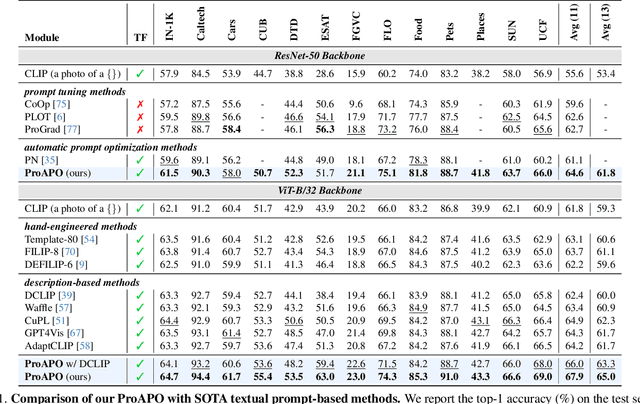
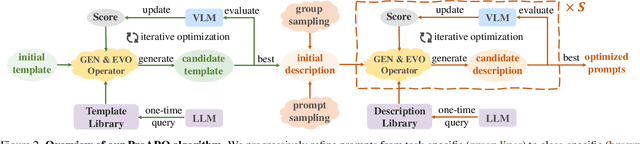
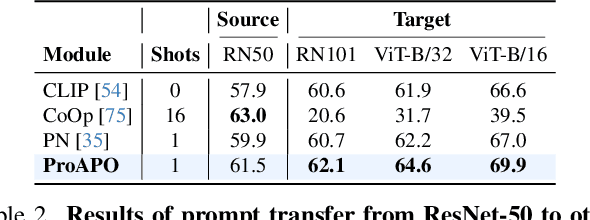
Vision-language models (VLMs) have made significant progress in image classification by training with large-scale paired image-text data. Their performances largely depend on the prompt quality. While recent methods show that visual descriptions generated by large language models (LLMs) enhance the generalization of VLMs, class-specific prompts may be inaccurate or lack discrimination due to the hallucination in LLMs. In this paper, we aim to find visually discriminative prompts for fine-grained categories with minimal supervision and no human-in-the-loop. An evolution-based algorithm is proposed to progressively optimize language prompts from task-specific templates to class-specific descriptions. Unlike optimizing templates, the search space shows an explosion in class-specific candidate prompts. This increases prompt generation costs, iterative times, and the overfitting problem. To this end, we first introduce several simple yet effective edit-based and evolution-based operations to generate diverse candidate prompts by one-time query of LLMs. Then, two sampling strategies are proposed to find a better initial search point and reduce traversed categories, saving iteration costs. Moreover, we apply a novel fitness score with entropy constraints to mitigate overfitting. In a challenging one-shot image classification setting, our method outperforms existing textual prompt-based methods and improves LLM-generated description methods across 13 datasets. Meanwhile, we demonstrate that our optimal prompts improve adapter-based methods and transfer effectively across different backbones.
T2VIndexer: A Generative Video Indexer for Efficient Text-Video Retrieval
Aug 21, 2024



Current text-video retrieval methods mainly rely on cross-modal matching between queries and videos to calculate their similarity scores, which are then sorted to obtain retrieval results. This method considers the matching between each candidate video and the query, but it incurs a significant time cost and will increase notably with the increase of candidates. Generative models are common in natural language processing and computer vision, and have been successfully applied in document retrieval, but their application in multimodal retrieval remains unexplored. To enhance retrieval efficiency, in this paper, we introduce a model-based video indexer named T2VIndexer, which is a sequence-to-sequence generative model directly generating video identifiers and retrieving candidate videos with constant time complexity. T2VIndexer aims to reduce retrieval time while maintaining high accuracy. To achieve this goal, we propose video identifier encoding and query-identifier augmentation approaches to represent videos as short sequences while preserving their semantic information. Our method consistently enhances the retrieval efficiency of current state-of-the-art models on four standard datasets. It enables baselines with only 30\%-50\% of the original retrieval time to achieve better retrieval performance on MSR-VTT (+1.0%), MSVD (+1.8%), ActivityNet (+1.5%), and DiDeMo (+0.2%). The code is available at https://github.com/Lilidamowang/T2VIndexer-generativeSearch.
IIU: Independent Inference Units for Knowledge-based Visual Question Answering
Aug 15, 2024Knowledge-based visual question answering requires external knowledge beyond visible content to answer the question correctly. One limitation of existing methods is that they focus more on modeling the inter-modal and intra-modal correlations, which entangles complex multimodal clues by implicit embeddings and lacks interpretability and generalization ability. The key challenge to solve the above problem is to separate the information and process it separately at the functional level. By reusing each processing unit, the generalization ability of the model to deal with different data can be increased. In this paper, we propose Independent Inference Units (IIU) for fine-grained multi-modal reasoning to decompose intra-modal information by the functionally independent units. Specifically, IIU processes each semantic-specific intra-modal clue by an independent inference unit, which also collects complementary information by communication from different units. To further reduce the impact of redundant information, we propose a memory update module to maintain semantic-relevant memory along with the reasoning process gradually. In comparison with existing non-pretrained multi-modal reasoning models on standard datasets, our model achieves a new state-of-the-art, enhancing performance by 3%, and surpassing basic pretrained multi-modal models. The experimental results show that our IIU model is effective in disentangling intra-modal clues as well as reasoning units to provide explainable reasoning evidence. Our code is available at https://github.com/Lilidamowang/IIU.