 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECA: Efficient Continual Alignment for Open-Ended Image-to-Text Generation
Jun 10, 2026Incremental Learning (IL) for Open-ended Image-to-Text Generation (OpenITG) enables models to continuously generate accurate, contextually relevant text for new images while preserving previously acquired knowledge. Unlike prior studies, this paper addresses a more practical scenario in which the predominant category of visual data shifts over time as environments evolve. In this context, we introduce a new notion of continual alignment, which incrementally adapts the alignment module within pre-trained VLMs to preserve high-quality cross-modal representations. Based on this idea, we propose Efficient Continual Alignment (ECA), a novel exemplar-free IL approach for OpenITG. The key challenge is enabling the model to acquire new, task-specific features while minimizing interference with the established alignment without accessing raw data from previous tasks. To address this, ECA employs three core mechanisms: a Mixture of Query (MoQ) module that adapts task-specific query tokens, a Fisher Dynamic Expansion (FeDEx) that dynamically expands model structure based on a Fisher Information Matrix (FIM)-based metric, and an embedding dictionary with Dictionary Replay (DR) to retain past knowledge. To evaluate ECA's performance, we construct four new IL OpenITG benchmarks that better reflect real-world scenarios. Experimental results demonstrate that ECA significantly mitigates catastrophic forgetting and improves IL performance compared to baseline methods. Code and benchmarks are available at https://github.com/Snowball0823/ECA.
WestWorld: A Knowledge-Encoded Scalable Trajectory World Model for Diverse Robotic Systems
Mar 15, 2026Trajectory world models play a crucial role in robotic dynamics learning, planning, and control. While recent works have explored trajectory world models for diverse robotic systems, they struggle to scale to a large number of distinct system dynamics and overlook domain knowledge of physical structures. To address these limitations, we introduce WestWorld, a knoWledge-Encoded Scalable Trajectory World model for diverse robotic systems. To tackle the scalability challenge, we propose a novel system-aware Mixture-of-Experts (Sys-MoE) that dynamically combines and routes specialized experts for different robotic systems via a learnable system embedding. To further enhance zero-shot generalization, we incorporate domain knowledge of robot physical structures by introducing a structural embedding that aligns trajectory representations with morphological information. After pretraining on 89 complex environments spanning diverse morphologies across both simulation and real-world settings, WestWorld achieves significant improvements over competitive baselines in zero- and few-shot trajectory prediction. Additionally, it shows strong scalability across a wide range of robotic environments and significantly improves performance on downstream model-based control for different robots. Finally, we deploy our model on a real-world Unitree Go1, where it demonstrates stable locomotion performance (see our demo on the website: https://westworldrobot.github.io/). The code will be available upon publication.
ODESteer: A Unified ODE-Based Steering Framework for LLM Alignment
Feb 19, 2026Activation steering, or representation engineering, offers a lightweight approach to align large language models (LLMs) by manipulating their internal activations at inference time. However, current methods suffer from two key limitations: \textit{(i)} the lack of a unified theoretical framework for guiding the design of steering directions, and \textit{(ii)} an over-reliance on \textit{one-step steering} that fail to capture complex patterns of activation distributions. In this work, we propose a unified ordinary differential equations (ODEs)-based \textit{theoretical} framework for activation steering in LLM alignment. We show that conventional activation addition can be interpreted as a first-order approximation to the solution of an ODE. Based on this ODE perspective, identifying a steering direction becomes equivalent to designing a \textit{barrier function} from control theory. Derived from this framework, we introduce ODESteer, a kind of ODE-based steering guided by barrier functions, which shows \textit{empirical} advancement in LLM alignment. ODESteer identifies steering directions by defining the barrier function as the log-density ratio between positive and negative activations, and employs it to construct an ODE for \textit{multi-step and adaptive} steering. Compared to state-of-the-art activation steering methods, ODESteer achieves consistent empirical improvements on diverse LLM alignment benchmarks, a notable $5.7\%$ improvement over TruthfulQA, $2.5\%$ over UltraFeedback, and $2.4\%$ over RealToxicityPrompts. Our work establishes a principled new view of activation steering in LLM alignment by unifying its theoretical foundations via ODEs, and validating it empirically through the proposed ODESteer method.
Hybrid Memory Replay: Blending Real and Distilled Data for Class Incremental Learning
Oct 20, 2024



Incremental learning (IL) aims to acquire new knowledge from current tasks while retaining knowledge learned from previous tasks. Replay-based IL methods store a set of exemplars from previous tasks in a buffer and replay them when learning new tasks. However, there is usually a size-limited buffer that cannot store adequate real exemplars to retain the knowledge of previous tasks. In contrast, data distillation (DD) can reduce the exemplar buffer's size, by condensing a large real dataset into a much smaller set of more information-compact synthetic exemplars. Nevertheless, DD's performance gain on IL quickly vanishes as the number of synthetic exemplars grows. To overcome the weaknesses of real-data and synthetic-data buffers, we instead optimize a hybrid memory including both types of data. Specifically, we propose an innovative modification to DD that distills synthetic data from a sliding window of checkpoints in history (rather than checkpoints on multiple training trajectories). Conditioned on the synthetic data, we then optimize the selection of real exemplars to provide complementary improvement to the DD objective. The optimized hybrid memory combines the strengths of synthetic and real exemplars, effectively mitigating catastrophic forgetting in Class IL (CIL) when the buffer size for exemplars is limited. Notably, our method can be seamlessly integrated into most existing replay-based CIL models. Extensive experiments across multiple benchmarks demonstrate that our method significantly outperforms existing replay-based baselines.
Condensed Prototype Replay for Class Incremental Learning
May 25, 2023Incremental learning (IL) suffers from catastrophic forgetting of old tasks when learning new tasks. This can be addressed by replaying previous tasks' data stored in a memory, which however is usually prone to size limits and privacy leakage. Recent studies store only class centroids as prototypes and augment them with Gaussian noises to create synthetic data for replay. However, they cannot effectively avoid class interference near their margins that leads to forgetting. Moreover, the injected noises distort the rich structure between real data and prototypes, hence even detrimental to IL. In this paper, we propose YONO that You Only Need to replay One condensed prototype per class, which for the first time can even outperform memory-costly exemplar-replay methods. To this end, we develop a novel prototype learning method that (1) searches for more representative prototypes in high-density regions by an attentional mean-shift algorithm and (2) moves samples in each class to their prototype to form a compact cluster distant from other classes. Thereby, the class margins are maximized, which effectively reduces interference causing future forgetting. In addition, we extend YONO to YONO+, which creates synthetic replay data by random sampling in the neighborhood of each prototype in the representation space. We show that the synthetic data can further improve YONO. Extensive experiments on IL benchmarks demonstrate the advantages of YONO/YONO+ over existing IL methods in terms of both accuracy and forgetting.
DSAM: A Distance Shrinking with Angular Marginalizing Loss for High Performance Vehicle Re-identificatio
Nov 25, 2020

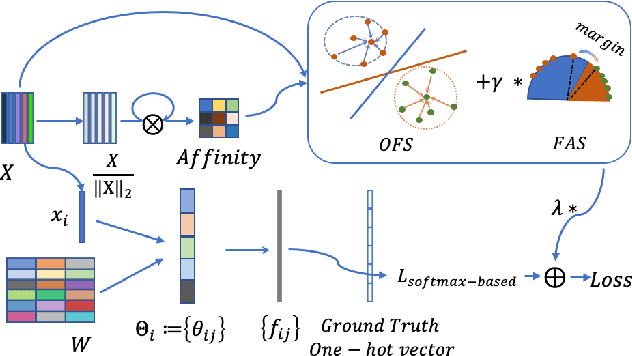
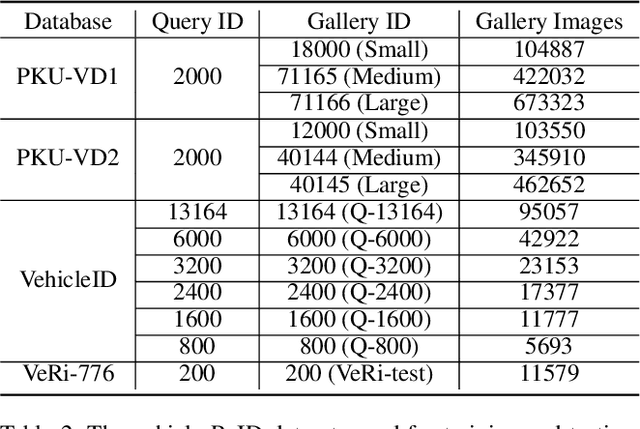
Vehicle Re-identification (ReID) is an important yet challenging problem in computer vision. Compared to other visual objects like faces and persons, vehicles simultaneously exhibit much larger intraclass viewpoint variations and interclass visual similarities, making most exiting loss functions designed for face recognition and person ReID unsuitable for vehicle ReID. To obtain a high-performance vehicle ReID model, we present a novel Distance Shrinking with Angular Marginalizing (DSAM) loss function to perform hybrid learning in both the Original Feature Space (OFS) and the Feature Angular Space (FAS) using the local verification and the global identification information. Specifically, it shrinks the distance between samples of the same class locally in the Original Feature Space while keeps samples of different classes far away in the Feature Angular Space. The shrinking and marginalizing operations are performed during each iteration of the training process and are suitable for different SoftMax based loss functions. We evaluate the DSAM loss function on three large vehicle ReID datasets with detailed analyses and extensive comparisons with many competing vehicle ReID methods. Experimental results show that our DSAM loss enhances the SoftMax loss by a large margin on the PKU-VD1-Large dataset: 10.41% for mAP, 5.29% for cmc1, and 4.60% for cmc5. Moreover, the mAP is increased by 9.34% on the PKU-VehicleID dataset and 8.73% on the VeRi-776 dataset. Source code will be released to facilitate further studies in this research direction.