 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC${^2}$RL: Content and Context Representation Learning for Gloss-free Sign Language Translation and Retrieval
Paper and Code
Aug 19, 2024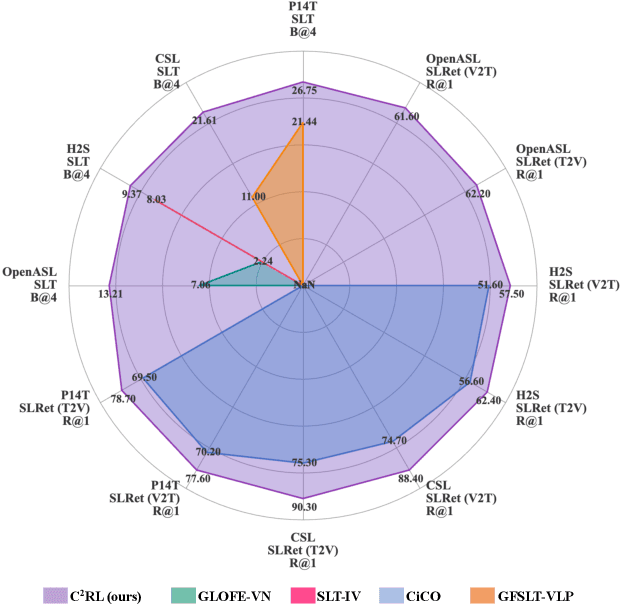
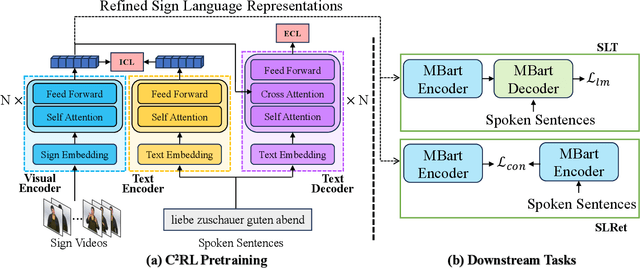
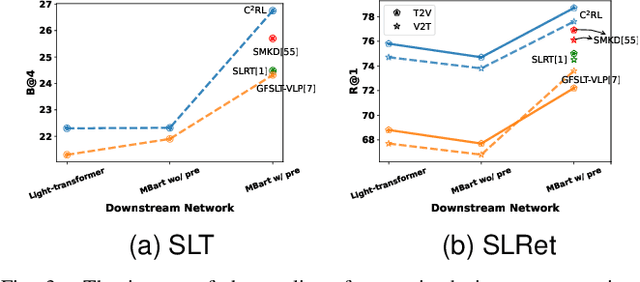
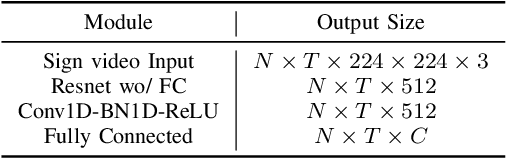
Sign Language Representation Learning (SLRL) is crucial for a range of sign language-related downstream tasks such as Sign Language Translation (SLT) and Sign Language Retrieval (SLRet). Recently, many gloss-based and gloss-free SLRL methods have been proposed, showing promising performance. Among them, the gloss-free approach shows promise for strong scalability without relying on gloss annotations. However, it currently faces suboptimal solutions due to challenges in encoding the intricate, context-sensitive characteristics of sign language videos, mainly struggling to discern essential sign features using a non-monotonic video-text alignment strategy. Therefore, we introduce an innovative pretraining paradigm for gloss-free SLRL, called C${^2}$RL, in this paper. Specifically, rather than merely incorporating a non-monotonic semantic alignment of video and text to learn language-oriented sign features, we emphasize two pivotal aspects of SLRL: Implicit Content Learning (ICL) and Explicit Context Learning (ECL). ICL delves into the content of communication, capturing the nuances, emphasis, timing, and rhythm of the signs. In contrast, ECL focuses on understanding the contextual meaning of signs and converting them into equivalent sentences. Despite its simplicity, extensive experiments confirm that the joint optimization of ICL and ECL results in robust sign language representation and significant performance gains in gloss-free SLT and SLRet tasks. Notably, C${^2}$RL improves the BLEU-4 score by +5.3 on P14T, +10.6 on CSL-daily, +6.2 on OpenASL, and +1.3 on How2Sign. It also boosts the R@1 score by +8.3 on P14T, +14.4 on CSL-daily, and +5.9 on How2Sign. Additionally, we set a new baseline for the OpenASL dataset in the SLRet task.