 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Vision Transformer Training: A Data-Centric Perspective
Paper and Code
Sep 29, 2022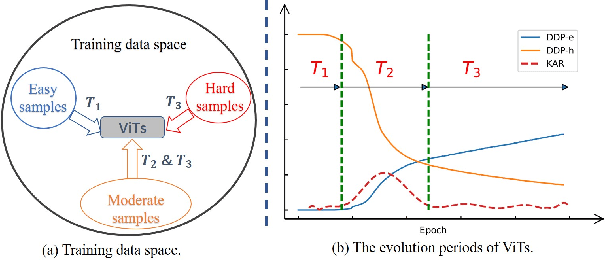
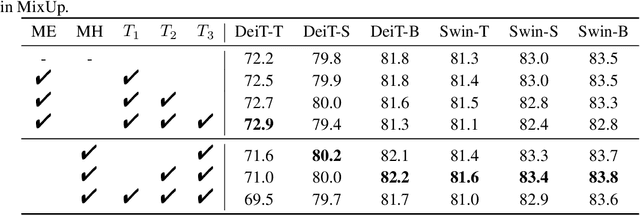
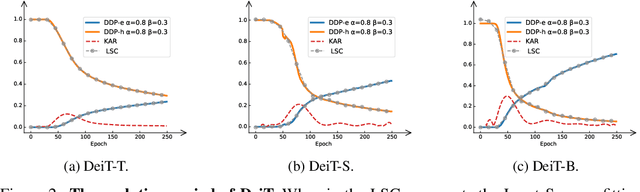
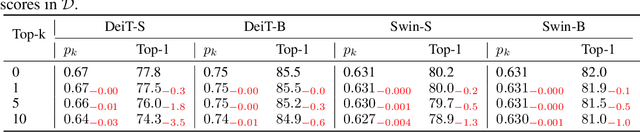
Vision Transformers (ViTs) have shown promising performance compared with Convolutional Neural Networks (CNNs), but the training of ViTs is much harder than CNNs. In this paper, we define several metrics, including Dynamic Data Proportion (DDP) and Knowledge Assimilation Rate (KAR), to investigate the training process, and divide it into three periods accordingly: formation, growth and exploration. In particular, at the last stage of training, we observe that only a tiny portion of training examples is used to optimize the model. Given the data-hungry nature of ViTs, we thus ask a simple but important question: is it possible to provide abundant ``effective'' training examples at EVERY stage of training? To address this issue, we need to address two critical questions, \ie, how to measure the ``effectiveness'' of individual training examples, and how to systematically generate enough number of ``effective'' examples when they are running out. To answer the first question, we find that the ``difficulty'' of training samples can be adopted as an indicator to measure the ``effectiveness'' of training samples. To cope with the second question, we propose to dynamically adjust the ``difficulty'' distribution of the training data in these evolution stages. To achieve these two purposes, we propose a novel data-centric ViT training framework to dynamically measure the ``difficulty'' of training samples and generate ``effective'' samples for models at different training stages. Furthermore, to further enlarge the number of ``effective'' samples and alleviate the overfitting problem in the late training stage of ViTs, we propose a patch-level erasing strategy dubbed PatchErasing. Extensive experiments demonstrate the effectiveness of the proposed data-centric ViT training framework and techniques.