 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DKU-MSXF Speaker Verification System for the VoxCeleb Speaker Recognition Challenge 2023
Paper and Code
Aug 17, 2023

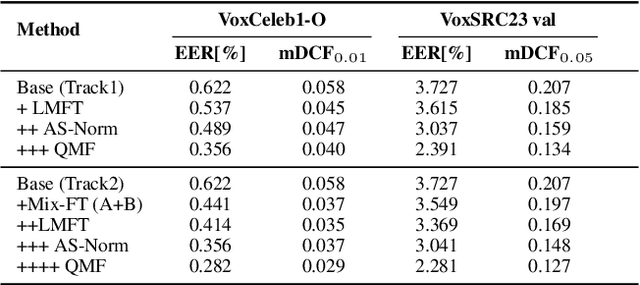
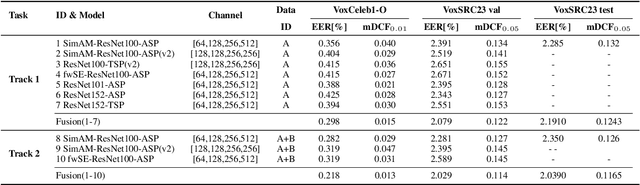
This paper is the system description of the DKU-MSXF System for the track1, track2 and track3 of the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). For Track 1, we utilize a network structure based on ResNet for training. By constructing a cross-age QMF training set, we achieve a substantial improvement in system performance. For Track 2, we inherite the pre-trained model from Track 1 and conducte mixed training by incorporating the VoxBlink-clean dataset. In comparison to Track 1, the models incorporating VoxBlink-clean data exhibit a performance improvement by more than 10% relatively. For Track3, the semi-supervised domain adaptation task, a novel pseudo-labeling method based on triple thresholds and sub-center purification is adopted to make domain adaptation. The final submission achieves mDCF of 0.1243 in task1, mDCF of 0.1165 in Track 2 and EER of 4.952% in Track 3.