 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE: Zero-Shot Image to Image Translation via Pretrained Auto-Contrastive-Encoder
Feb 22, 2023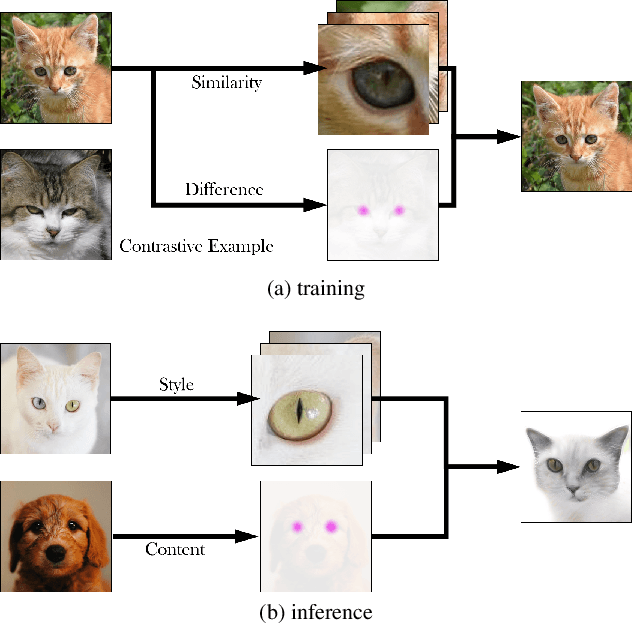



Image-to-image translation is a fundamental task in computer vision. It transforms images from one domain to images in another domain so that they have particular domain-specific characteristics. Most prior works train a generative model to learn the mapping from a source domain to a target domain. However, learning such mapping between domains is challenging because data from different domains can be highly unbalanced in terms of both quality and quantity. To address this problem, we propose a new approach to extract image features by learning the similarities and differences of samples within the same data distribution via a novel contrastive learning framework, which we call Auto-Contrastive-Encoder (ACE). ACE learns the content code as the similarity between samples with the same content information and different style perturbations. The design of ACE enables us to achieve zero-shot image-to-image translation with no training on image translation tasks for the first time. Moreover, our learning method can learn the style features of images on different domains effectively. Consequently, our model achieves competitive results on multimodal image translation tasks with zero-shot learning as well. Additionally, we demonstrate the potential of our method in transfer learning. With fine-tuning, the quality of translated images improves in unseen domains. Even though we use contrastive learning, all of our training can be performed on a single GPU with the batch size of 8.