 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness Unhardening via Backdoor Attacks in Federated Learning
Oct 21, 2023



In today's data-driven landscape, the delicate equilibrium between safeguarding user privacy and unleashing data potential stands as a paramount concern. Federated learning, which enables collaborative model training without necessitating data sharing, has emerged as a privacy-centric solution. This decentralized approach brings forth security challenges, notably poisoning and backdoor attacks where malicious entities inject corrupted data. Our research, initially spurred by test-time evasion attacks, investigates the intersection of adversarial training and backdoor attacks within federated learning, introducing Adversarial Robustness Unhardening (ARU). ARU is employed by a subset of adversaries to intentionally undermine model robustness during decentralized training, rendering models susceptible to a broader range of evasion attacks. We present extensive empirical experiments evaluating ARU's impact on adversarial training and existing robust aggregation defenses against poisoning and backdoor attacks. Our findings inform strategies for enhancing ARU to counter current defensive measures and highlight the limitations of existing defenses, offering insights into bolstering defenses against ARU.
pFedDef: Defending Grey-Box Attacks for Personalized Federated Learning
Sep 17, 2022
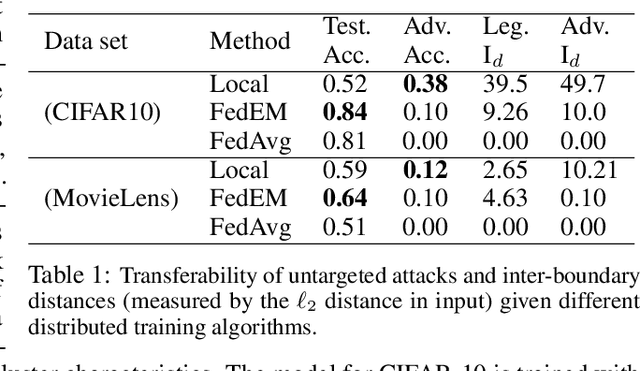
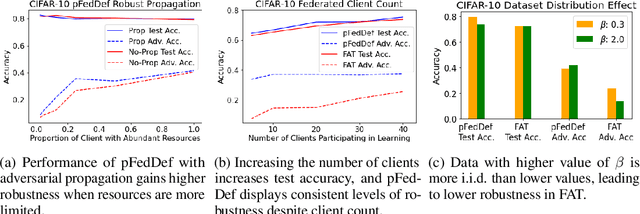

Personalized federated learning allows for clients in a distributed system to train a neural network tailored to their unique local data while leveraging information at other clients. However, clients' models are vulnerable to attacks during both the training and testing phases. In this paper we address the issue of adversarial clients crafting evasion attacks at test time to deceive other clients. For example, adversaries may aim to deceive spam filters and recommendation systems trained with personalized federated learning for monetary gain. The adversarial clients have varying degrees of personalization based on the method of distributed learning, leading to a "grey-box" situation. We are the first to characterize the transferability of such internal evasion attacks for different learning methods and analyze the trade-off between model accuracy and robustness depending on the degree of personalization and similarities in client data. We introduce a defense mechanism, pFedDef, that performs personalized federated adversarial training while respecting resource limitations at clients that inhibit adversarial training. Overall, pFedDef increases relative grey-box adversarial robustness by 62% compared to federated adversarial training and performs well even under limited system resources.