 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review and Roadmap of Deep Causal Model from Different Causal Structures and Representations
Nov 02, 2023



The fusion of causal models with deep learning introducing increasingly intricate data sets, such as the causal associations within images or between textual components, has surfaced as a focal research area. Nonetheless, the broadening of original causal concepts and theories to such complex, non-statistical data has been met with serious challenges. In response, our study proposes redefinitions of causal data into three distinct categories from the standpoint of causal structure and representation: definite data, semi-definite data, and indefinite data. Definite data chiefly pertains to statistical data used in conventional causal scenarios, while semi-definite data refers to a spectrum of data formats germane to deep learning, including time-series, images, text, and others. Indefinite data is an emergent research sphere inferred from the progression of data forms by us. To comprehensively present these three data paradigms, we elaborate on their formal definitions, differences manifested in datasets, resolution pathways, and development of research. We summarize key tasks and achievements pertaining to definite and semi-definite data from myriad research undertakings, present a roadmap for indefinite data, beginning with its current research conundrums. Lastly, we classify and scrutinize the key datasets presently utilized within these three paradigms.
A Review and Roadmap of Deep Learning Causal Discovery in Different Variable Paradigms
Sep 14, 2022



Understanding causality helps to structure interventions to achieve specific goals and enables predictions under interventions. With the growing importance of learning causal relationships, causal discovery tasks have transitioned from using traditional methods to infer potential causal structures from observational data to the field of pattern recognition involved in deep learning. The rapid accumulation of massive data promotes the emergence of causal search methods with brilliant scalability. Existing summaries of causal discovery methods mainly focus on traditional methods based on constraints, scores and FCMs, there is a lack of perfect sorting and elaboration for deep learning-based methods, also lacking some considers and exploration of causal discovery methods from the perspective of variable paradigms. Therefore, we divide the possible causal discovery tasks into three types according to the variable paradigm and give the definitions of the three tasks respectively, define and instantiate the relevant datasets for each task and the final causal model constructed at the same time, then reviews the main existing causal discovery methods for different tasks. Finally, we propose some roadmaps from different perspectives for the current research gaps in the field of causal discovery and point out future research directions.
Multi-level Domain Adaptation for Lane Detection
Jun 21, 2022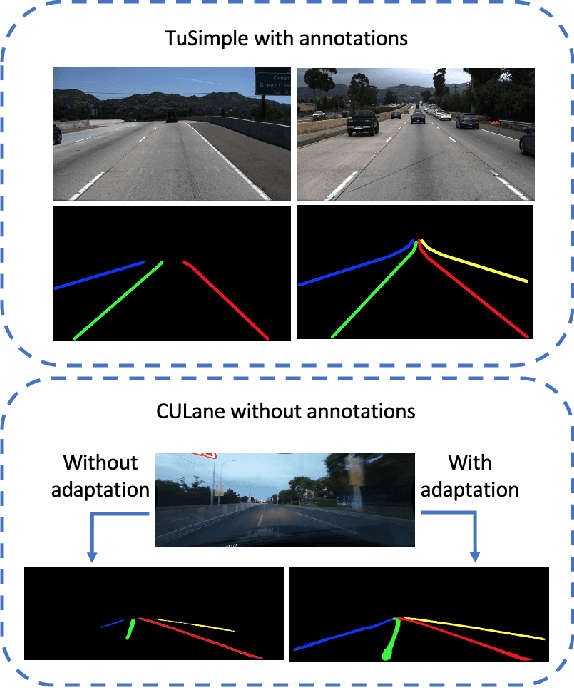

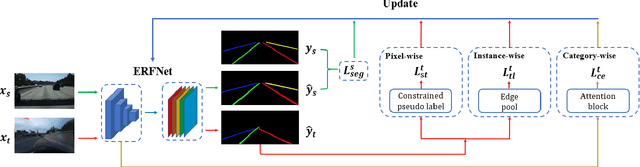
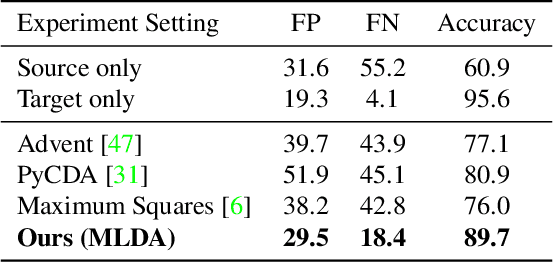
We focus on bridging domain discrepancy in lane detection among different scenarios to greatly reduce extra annotation and re-training costs for autonomous driving. Critical factors hinder the performance improvement of cross-domain lane detection that conventional methods only focus on pixel-wise loss while ignoring shape and position priors of lanes. To address the issue, we propose the Multi-level Domain Adaptation (MLDA) framework, a new perspective to handle cross-domain lane detection at three complementary semantic levels of pixel, instance and category. Specifically, at pixel level, we propose to apply cross-class confidence constraints in self-training to tackle the imbalanced confidence distribution of lane and background. At instance level, we go beyond pixels to treat segmented lanes as instances and facilitate discriminative features in target domain with triplet learning, which effectively rebuilds the semantic context of lanes and contributes to alleviating the feature confusion. At category level, we propose an adaptive inter-domain embedding module to utilize the position prior of lanes during adaptation. In two challenging datasets, ie TuSimple and CULane, our approach improves lane detection performance by a large margin with gains of 8.8% on accuracy and 7.4% on F1-score respectively, compared with state-of-the-art domain adaptation algorithms.
Reconstruct from Top View: A 3D Lane Detection Approach based on Geometry Structure Prior
Jun 21, 2022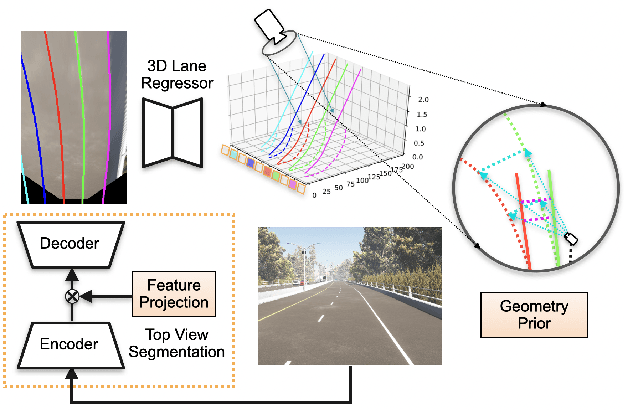
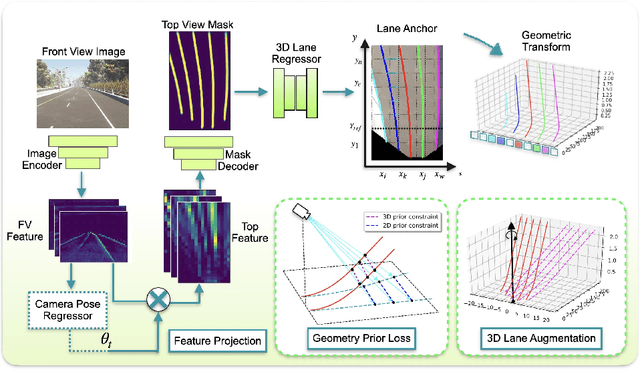
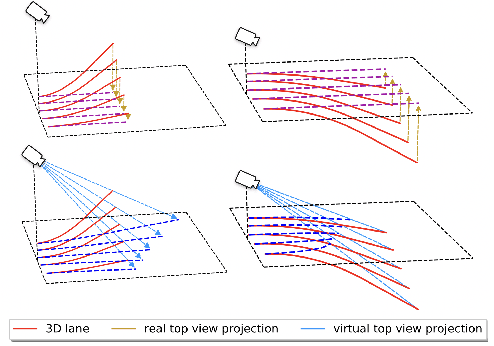

In this paper, we propose an advanced approach in targeting the problem of monocular 3D lane detection by leveraging geometry structure underneath the process of 2D to 3D lane reconstruction. Inspired by previous methods, we first analyze the geometry heuristic between the 3D lane and its 2D representation on the ground and propose to impose explicit supervision based on the structure prior, which makes it achievable to build inter-lane and intra-lane relationships to facilitate the reconstruction of 3D lanes from local to global. Second, to reduce the structure loss in 2D lane representation, we directly extract top view lane information from front view images, which tremendously eases the confusion of distant lane features in previous methods. Furthermore, we propose a novel task-specific data augmentation method by synthesizing new training data for both segmentation and reconstruction tasks in our pipeline, to counter the imbalanced data distribution of camera pose and ground slope to improve generalization on unseen data. Our work marks the first attempt to employ the geometry prior information into DNN-based 3D lane detection and makes it achievable for detecting lanes in an extra-long distance, doubling the original detection range. The proposed method can be smoothly adopted by other frameworks without extra costs. Experimental results show that our work outperforms state-of-the-art approaches by 3.8% F-Score on Apollo 3D synthetic dataset at real-time speed of 82 FPS without introducing extra parameters.
Ensuring Readability and Data-fidelity using Head-modifier Templates in Deep Type Description Generation
May 29, 2019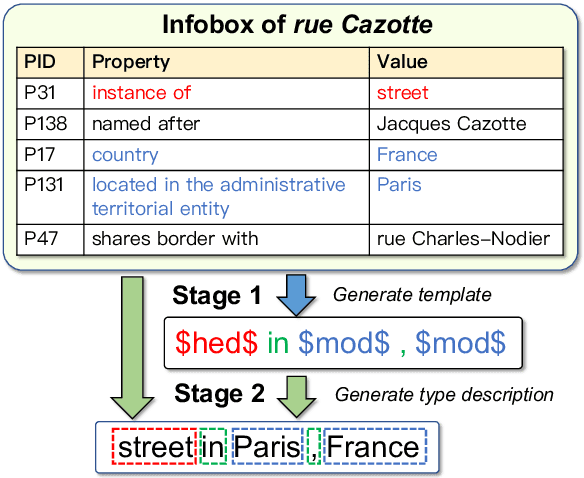
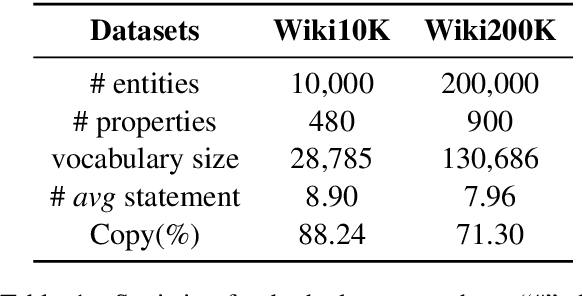
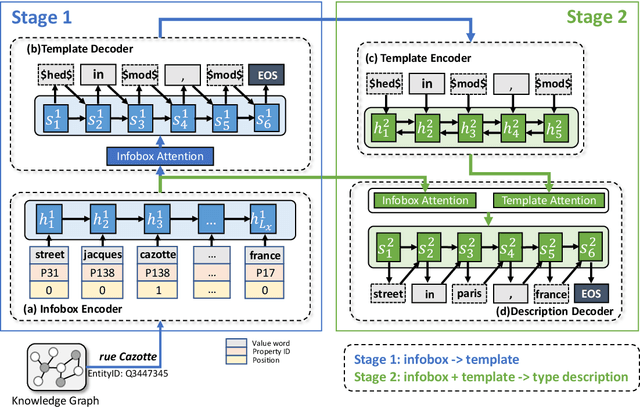
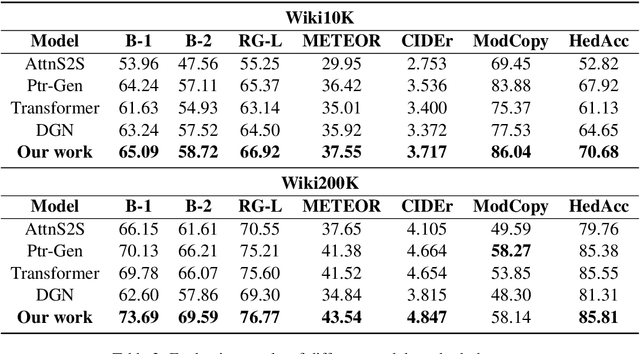
A type description is a succinct noun compound which helps human and machines to quickly grasp the informative and distinctive information of an entity. Entities in most knowledge graphs (KGs) still lack such descriptions, thus calling for automatic methods to supplement such information. However, existing generative methods either overlook the grammatical structure or make factual mistakes in generated texts. To solve these problems, we propose a head-modifier template-based method to ensure the readability and data fidelity of generated type descriptions. We also propose a new dataset and two automatic metrics for this task. Experiments show that our method improves substantially compared with baselines and achieves state-of-the-art performance on both datasets.
KDSL: a Knowledge-Driven Supervised Learning Framework for Word Sense Disambiguation
Sep 24, 2018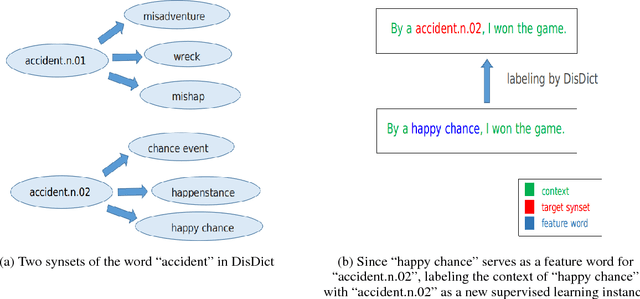

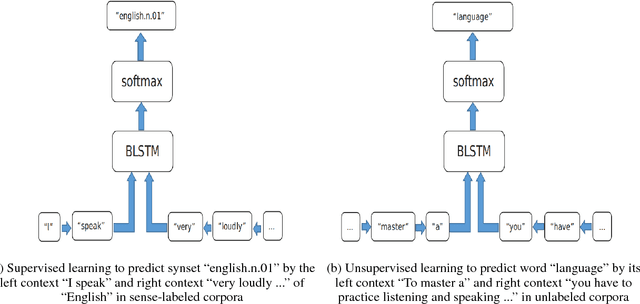
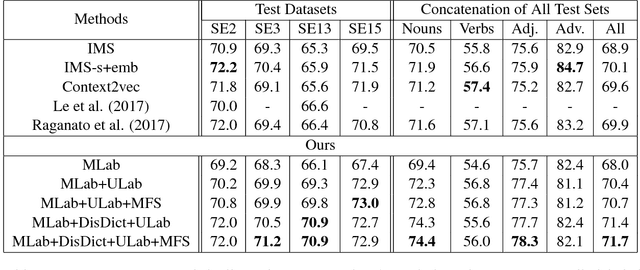
We propose KDSL, a new word sense disambiguation (WSD) framework that utilizes knowledge to automatically generate sense-labeled data for supervised learning. First, from WordNet, we automatically construct a semantic knowledge base called DisDict, which provides refined feature words that highlight the differences among word senses, i.e., synsets. Second, we automatically generate new sense-labeled data by DisDict from unlabeled corpora. Third, these generated data, together with manually labeled data and unlabeled data, are fed to a neural framework conducting supervised and unsupervised learning jointly to model the semantic relations among synsets, feature words and their contexts. The experimental results show that KDSL outperforms several representative state-of-the-art methods on various major benchmarks. Interestingly, it performs relatively well even when manually labeled data is unavailable, thus provides a potential solution for similar tasks in a lack of manual annotations.