 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CLEAR Benchmark: Continual LEArning on Real-World Imagery
Paper and Code

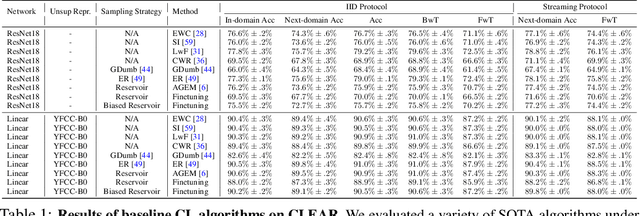
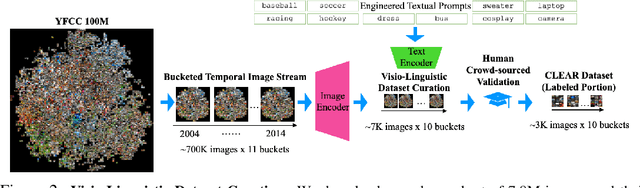
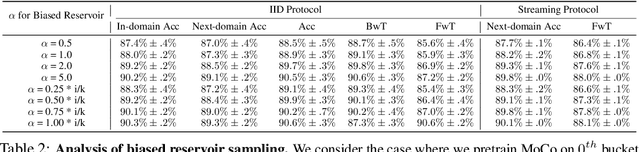
Continual learning (CL) is widely regarded as crucial challenge for lifelong AI. However, existing CL benchmarks, e.g. Permuted-MNIST and Split-CIFAR, make use of artificial temporal variation and do not align with or generalize to the real-world. In this paper, we introduce CLEAR, the first continual image classification benchmark dataset with a natural temporal evolution of visual concepts in the real world that spans a decade (2004-2014). We build CLEAR from existing large-scale image collections (YFCC100M) through a novel and scalable low-cost approach to visio-linguistic dataset curation. Our pipeline makes use of pretrained vision-language models (e.g. CLIP) to interactively build labeled datasets, which are further validated with crowd-sourcing to remove errors and even inappropriate images (hidden in original YFCC100M). The major strength of CLEAR over prior CL benchmarks is the smooth temporal evolution of visual concepts with real-world imagery, including both high-quality labeled data along with abundant unlabeled samples per time period for continual semi-supervised learning. We find that a simple unsupervised pre-training step can already boost state-of-the-art CL algorithms that only utilize fully-supervised data. Our analysis also reveals that mainstream CL evaluation protocols that train and test on iid data artificially inflate performance of CL system. To address this, we propose novel "streaming" protocols for CL that always test on the (near) future. Interestingly, streaming protocols (a) can simplify dataset curation since today's testset can be repurposed for tomorrow's trainset and (b) can produce more generalizable models with more accurate estimates of performance since all labeled data from each time-period is used for both training and testing (unlike classic iid train-test splits).