 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaineCoon: Pursuing A Real-Time Audio-Visual Social World Model
Jun 16, 2026As an increasing majority of global video content is consumed on social platforms for interactive social purposes, video generation models built for social worlds are important but largely overlooked by previous studies. In this work, we define the position of social world models and build a prototype model as the first step towards this goal. While previous world models successfully simulate physical environments or gaming world exploration, they remain fundamentally detached from human-centric social dynamics. To bridge this gap as the first step to social world models, we present MaineCoon, the first real-time audio-visual autoregressive model that has 22B parameters and is capable of real-time streaming generation and sub-second interaction, with a record-breaking frame rate of up to 47.5 FPS, on a single GPU. To the best of our knowledge, MaineCoon is also the first real-time audio-visual generation model specifically optimized for social-interactive applications. To enable efficient and stable training, we introduce several novel techniques into MaineCoon, including self-resampling, cross-modal representation alignment, domain-aware preference optimization, and reinforced online-policy distillation (ROPD). We also design the first agentic streaming inference framework that supports thousand-second-scale or even longer generation while mitigating drift with agentic cache management and prompt planing. These innovations significantly accelerate training while optimizing real-time inference performance. We believe this work not only sets a new state-of-the-art (SOTA) performance benchmark for high-quality, low-latency, and long-horizon audio-visual autoregressive models, but also points out the paradigm shift desired for next-generation AI-native social platforms.
REALM: Retrospective Encoder Alignment for LFP Modeling
May 14, 2026Spike activity has been the dominant neural signal for behavior decoding due to its high spatial and temporal resolution. However, as brain-computer interfaces (BCIs) move toward high channel counts and wireless operation, the high sampling frequency of spike signals becomes a bottleneck due to high power and bandwidth requirements. Local field potentials (LFPs) represent a different spatial-temporal scale of brain activity compared to spikes, offering key advantages including improved long-term stability, reduced energy consumption, and lower bandwidth requirement. Despite these benefits, LFP-based decoding models typically show reduced accuracy and often rely on non-causal architectures that are unsuitable for real-time deployment. To address these challenges, we propose REALM: a retrospective distillation framework that enables causal LFP decoding. Inspired by offline-to-online distillation strategies in speech recognition, REALM transfers representational knowledge from a pretrained multi-session bidirectional LFP model to a causal version for real-time deployment. We first pretrain a bidirectional Mamba-2 teacher model using a masked autoencoding objective. We then distill this teacher model into a compact student model via a combined objective of representation alignment and task supervision. REALM consistently outperforms both causal and non-causal LFP-based SOTA methods for behavior decoding. Notably, our REALM improves decoding performance while achieving a $2\times$ reduction in parameter count and a $10\times$ reduction in training time. These results demonstrate that retrospective distillation effectively bridges the gap between offline and real-time neural decoding. REALM shows that LFP-only models can achieve competitive decoding performance without reliance on spike signals, offering a practical and scalable alternative for next-generation wireless implantable BCIs.
Legal Fact Prediction: Task Definition and Dataset Construction
Sep 11, 2024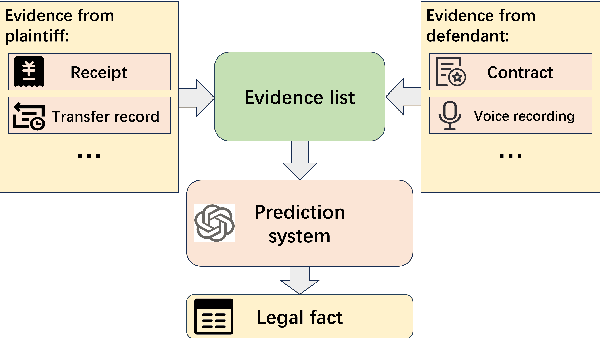

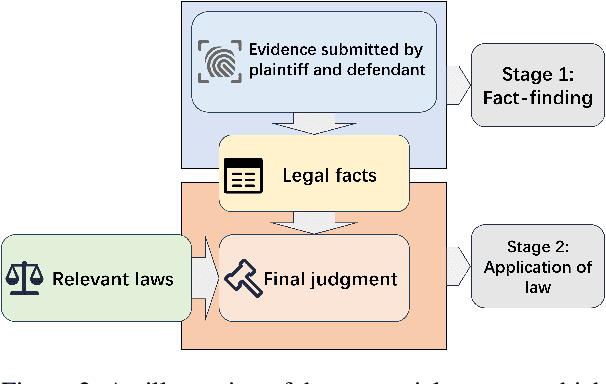
Legal facts refer to the facts that can be proven by acknowledged evidence in a trial. They form the basis for the determination of court judgments. This paper introduces a novel NLP task: legal fact prediction, which aims to predict the legal fact based on a list of evidence. The predicted facts can instruct the parties and their lawyers involved in a trial to strengthen their submissions and optimize their strategies during the trial. Moreover, since real legal facts are difficult to obtain before the final judgment, the predicted facts also serve as an important basis for legal judgment prediction. We construct a benchmark dataset consisting of evidence lists and ground-truth legal facts for real civil loan cases, LFPLoan. Our experiments on this dataset show that this task is non-trivial and requires further considerable research efforts.
Unified Chinese License Plate Detection and Recognition with High Efficiency
May 07, 2022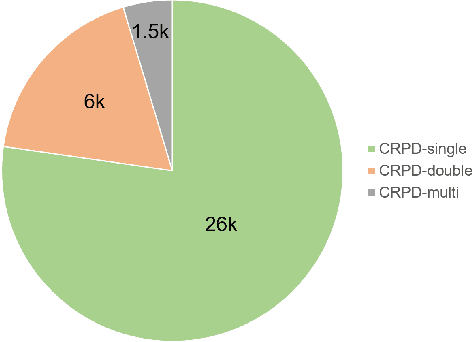
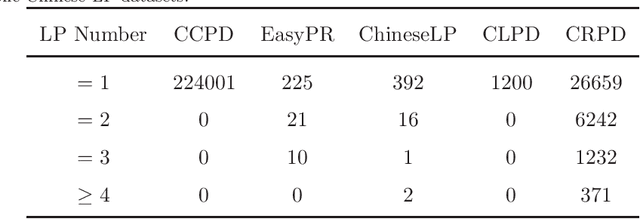

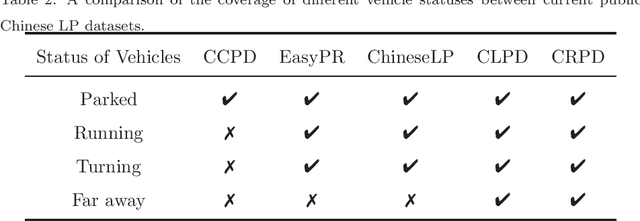
Recently, deep learning-based methods have reached an excellent performance on License Plate (LP) detection and recognition tasks. However, it is still challenging to build a robust model for Chinese LPs since there are not enough large and representative datasets. In this work, we propose a new dataset named Chinese Road Plate Dataset (CRPD) that contains multi-objective Chinese LP images as a supplement to the existing public benchmarks. The images are mainly captured with electronic monitoring systems with detailed annotations. To our knowledge, CRPD is the largest public multi-objective Chinese LP dataset with annotations of vertices. With CRPD, a unified detection and recognition network with high efficiency is presented as the baseline. The network is end-to-end trainable with totally real-time inference efficiency (30 fps with 640p). The experiments on several public benchmarks demonstrate that our method has reached competitive performance. The code and dataset will be publicly available at https://github.com/yxgong0/CRPD.