 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Chinese License Plate Detection and Recognition with High Efficiency
May 07, 2022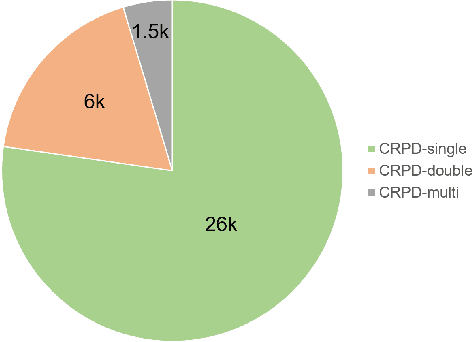
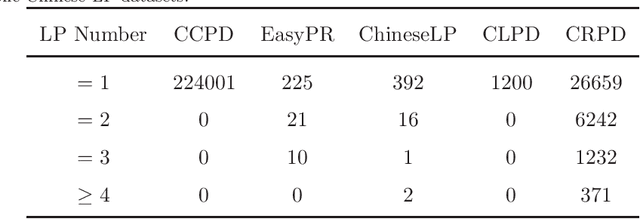

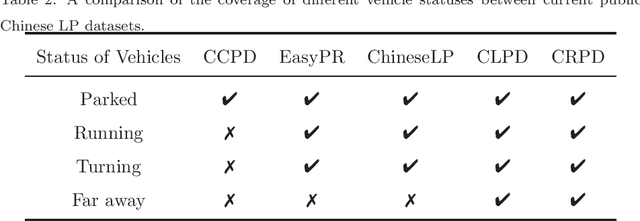
Recently, deep learning-based methods have reached an excellent performance on License Plate (LP) detection and recognition tasks. However, it is still challenging to build a robust model for Chinese LPs since there are not enough large and representative datasets. In this work, we propose a new dataset named Chinese Road Plate Dataset (CRPD) that contains multi-objective Chinese LP images as a supplement to the existing public benchmarks. The images are mainly captured with electronic monitoring systems with detailed annotations. To our knowledge, CRPD is the largest public multi-objective Chinese LP dataset with annotations of vertices. With CRPD, a unified detection and recognition network with high efficiency is presented as the baseline. The network is end-to-end trainable with totally real-time inference efficiency (30 fps with 640p). The experiments on several public benchmarks demonstrate that our method has reached competitive performance. The code and dataset will be publicly available at https://github.com/yxgong0/CRPD.
Focus-Enhanced Scene Text Recognition with Deformable Convolutions
Sep 23, 2019
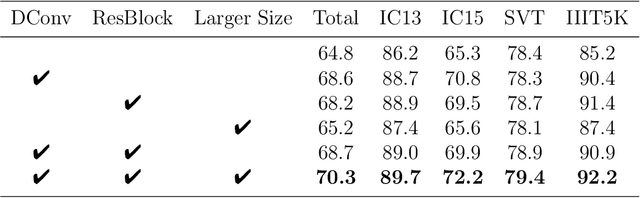
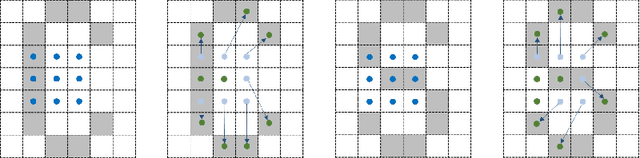
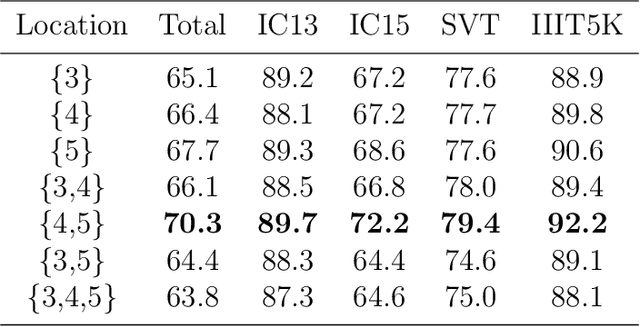
Recently, scene text recognition methods based on deep learning have sprung up in computer vision area. The existing methods achieved great performances, but the recognition of irregular text is still challenging due to the various shapes and distorted patterns. Consider that at the time of reading words in the real world, normally we will not rectify it in our mind but adjust our focus and visual fields. Similarly, through utilizing deformable convolutional layers whose geometric structures are adjustable, we present an enhanced recognition network without the steps of rectification to deal with irregular text in this work. A number of experiments have been applied, where the results on public benchmarks demonstrate the effectiveness of our proposed components and shows that our method has reached satisfactory performances. The code will be publicly available at https://github.com/Alpaca07/dtr soon.
STELA: A Real-Time Scene Text Detector with Learned Anchor
Sep 23, 2019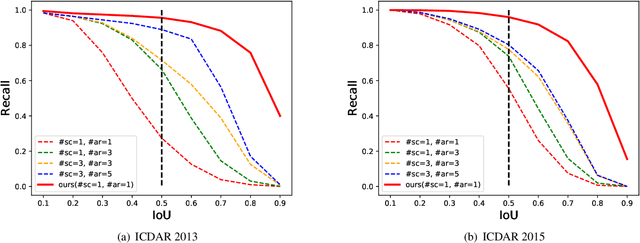
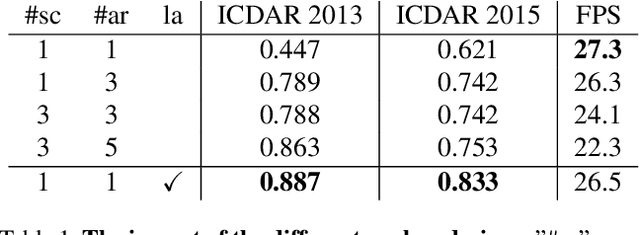
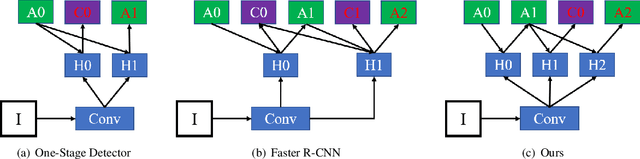
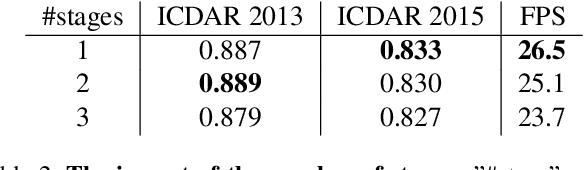
To achieve high coverage of target boxes, a normal strategy of conventional one-stage anchor-based detectors is to utilize multiple priors at each spatial position, especially in scene text detection tasks. In this work, we present a simple and intuitive method for multi-oriented text detection where each location of feature maps only associates with one reference box. The idea is inspired from the twostage R-CNN framework that can estimate the location of objects with any shape by using learned proposals. The aim of our method is to integrate this mechanism into a onestage detector and employ the learned anchor which is obtained through a regression operation to replace the original one into the final predictions. Based on RetinaNet, our method achieves competitive performances on several public benchmarks with a totally real-time efficiency (26:5fps at 800p), which surpasses all of anchor-based scene text detectors. In addition, with less attention on anchor design, we believe our method is easy to be applied on other analogous detection tasks. The code will publicly available at https://github.com/xhzdeng/stela.