 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-based A Posteriori Speech Presence Probability Estimation and Applications
Jan 23, 2025



The a posteriori speech presence probability (SPP) is the fundamental component of noise power spectral density (PSD) estimation, which can contribute to speech enhancement and speech recognition systems. Most existing SPP estimators can estimate SPP accurately from the background noise. Nevertheless, numerous challenges persist, including the difficulty of accurately estimating SPP from non-stationary noise with statistics-based methods and the high latency associated with deep learning-based approaches. This paper presents an improved SPP estimation approach based on deep learning to achieve higher SPP estimation accuracy, especially in non-stationary noise conditions. To promote the information extraction performance of the DNN, the global information of the observed signal and the local information of the decoupled frequency bins from the observed signal are connected as hybrid global-local information. The global information is extracted by one encoder. Then, one decoder and two fully connected layers are used to estimate SPP from the information of residual connection. To evaluate the performance of our proposed SPP estimator, the noise PSD estimation and speech enhancement tasks are performed. In contrast to existing minimum mean-square error (MMSE)-based noise PSD estimation approaches, the noise PSD is estimated by the sub-optimal MMSE based on the current frame SPP estimate without smoothing. Directed by the noise PSD estimate, a standard speech enhancement framework, the log spectral amplitude estimator, is employed to extract clean speech from the observed signal. From the experimental results, we can confirm that our proposed SPP estimator can achieve high noise PSD estimation accuracy and speech enhancement performance while requiring low model complexity.
Frequency bin-wise single channel speech presence probability estimation using multiple DNNs
Feb 23, 2023In this work, we propose a frequency bin-wise method to estimate the single-channel speech presence probability (SPP) with multiple deep neural networks (DNNs) in the short-time Fourier transform domain. Since all frequency bins are typically considered simultaneously as input features for conventional DNN-based SPP estimators, high model complexity is inevitable. To reduce the model complexity and the requirements on the training data, we take a single frequency bin and some of its neighboring frequency bins into account to train separate gate recurrent units. In addition, the noisy speech and the a posteriori probability SPP representation are used to train our model. The experiments were performed on the Deep Noise Suppression challenge dataset. The experimental results show that the speech detection accuracy can be improved when we employ the frequency bin-wise model. Finally, we also demonstrate that our proposed method outperforms most of the state-of-the-art SPP estimation methods in terms of speech detection accuracy and model complexity.
Unified Chinese License Plate Detection and Recognition with High Efficiency
May 07, 2022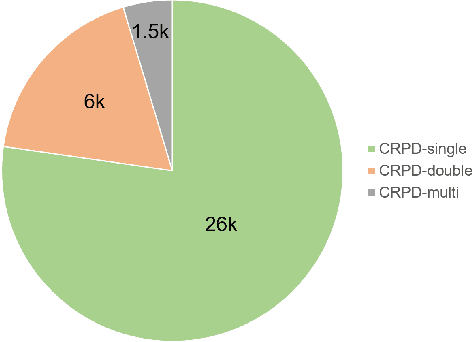
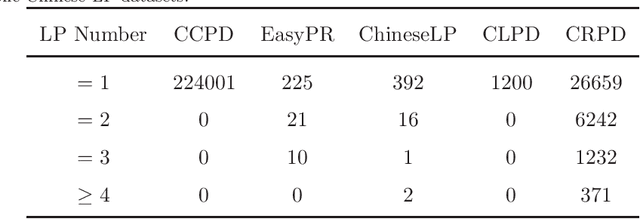

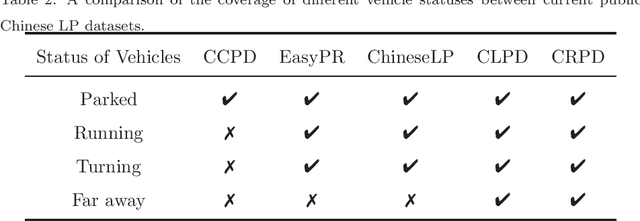
Recently, deep learning-based methods have reached an excellent performance on License Plate (LP) detection and recognition tasks. However, it is still challenging to build a robust model for Chinese LPs since there are not enough large and representative datasets. In this work, we propose a new dataset named Chinese Road Plate Dataset (CRPD) that contains multi-objective Chinese LP images as a supplement to the existing public benchmarks. The images are mainly captured with electronic monitoring systems with detailed annotations. To our knowledge, CRPD is the largest public multi-objective Chinese LP dataset with annotations of vertices. With CRPD, a unified detection and recognition network with high efficiency is presented as the baseline. The network is end-to-end trainable with totally real-time inference efficiency (30 fps with 640p). The experiments on several public benchmarks demonstrate that our method has reached competitive performance. The code and dataset will be publicly available at https://github.com/yxgong0/CRPD.