 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of the Scale Invariant Signal to Distortion Ratio in Speech Separation with Noisy References
Aug 20, 2025This paper examines the implications of using the Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) as both evaluation and training objective in supervised speech separation, when the training references contain noise, as is the case with the de facto benchmark WSJ0-2Mix. A derivation of the SI-SDR with noisy references reveals that noise limits the achievable SI-SDR, or leads to undesired noise in the separated outputs. To address this, a method is proposed to enhance references and augment the mixtures with WHAM!, aiming to train models that avoid learning noisy references. Two models trained on these enhanced datasets are evaluated with the non-intrusive NISQA.v2 metric. Results show reduced noise in separated speech but suggest that processing references may introduce artefacts, limiting overall quality gains. Negative correlation is found between SI-SDR and perceived noisiness across models on the WSJ0-2Mix and Libri2Mix test sets, underlining the conclusion from the derivation.
Learning-based A Posteriori Speech Presence Probability Estimation and Applications
Jan 23, 2025



The a posteriori speech presence probability (SPP) is the fundamental component of noise power spectral density (PSD) estimation, which can contribute to speech enhancement and speech recognition systems. Most existing SPP estimators can estimate SPP accurately from the background noise. Nevertheless, numerous challenges persist, including the difficulty of accurately estimating SPP from non-stationary noise with statistics-based methods and the high latency associated with deep learning-based approaches. This paper presents an improved SPP estimation approach based on deep learning to achieve higher SPP estimation accuracy, especially in non-stationary noise conditions. To promote the information extraction performance of the DNN, the global information of the observed signal and the local information of the decoupled frequency bins from the observed signal are connected as hybrid global-local information. The global information is extracted by one encoder. Then, one decoder and two fully connected layers are used to estimate SPP from the information of residual connection. To evaluate the performance of our proposed SPP estimator, the noise PSD estimation and speech enhancement tasks are performed. In contrast to existing minimum mean-square error (MMSE)-based noise PSD estimation approaches, the noise PSD is estimated by the sub-optimal MMSE based on the current frame SPP estimate without smoothing. Directed by the noise PSD estimate, a standard speech enhancement framework, the log spectral amplitude estimator, is employed to extract clean speech from the observed signal. From the experimental results, we can confirm that our proposed SPP estimator can achieve high noise PSD estimation accuracy and speech enhancement performance while requiring low model complexity.
Robust Fixed-Filter Sound Zone Control with Audio-Based Position Tracking
Oct 10, 2024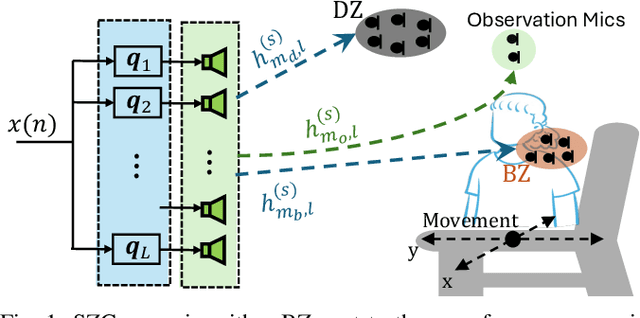
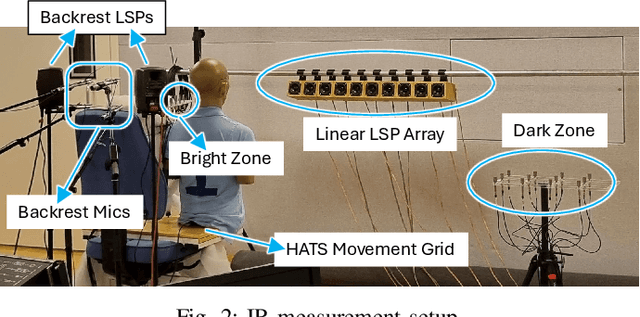
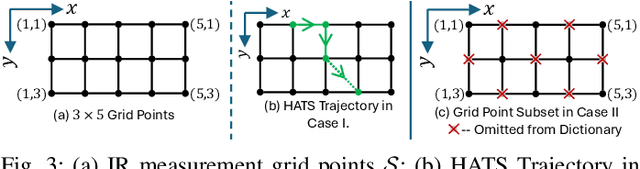
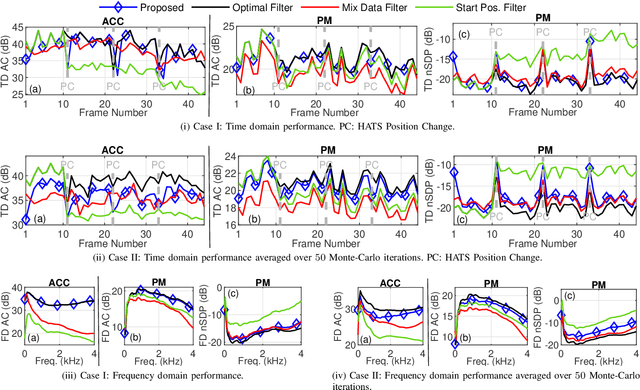
Performance of sound zone control (SZC) systems deployed in practical scenarios are highly sensitive to the location of the listener(s) and can degrade significantly when listener(s) are moving. This paper presents a robust SZC system that adapts to dynamic changes such as moving listeners and varying zone locations using a dictionary-based approach. The proposed system continuously monitors the environment and updates the fixed control filters by tracking the listener position using audio signals only. To test the effectiveness of the proposed SZC method, simulation studies are carried out using practically measured impulse responses. These studies show that SZC, when incorporated with the proposed audio-only position tracking scheme, achieves optimal performance when all listener positions are available in the dictionary. Moreover, even when not all listener positions are included in the dictionary, the method still provides good performance improvement compared to a traditional fixed filter SZC scheme.
Sound Zone Control Robust To Sound Speed Change
Oct 10, 2024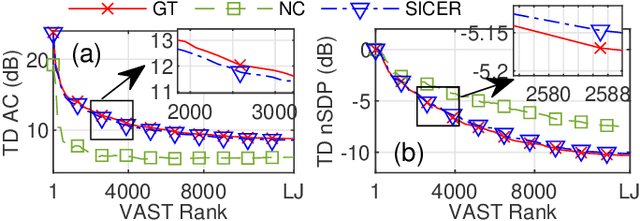
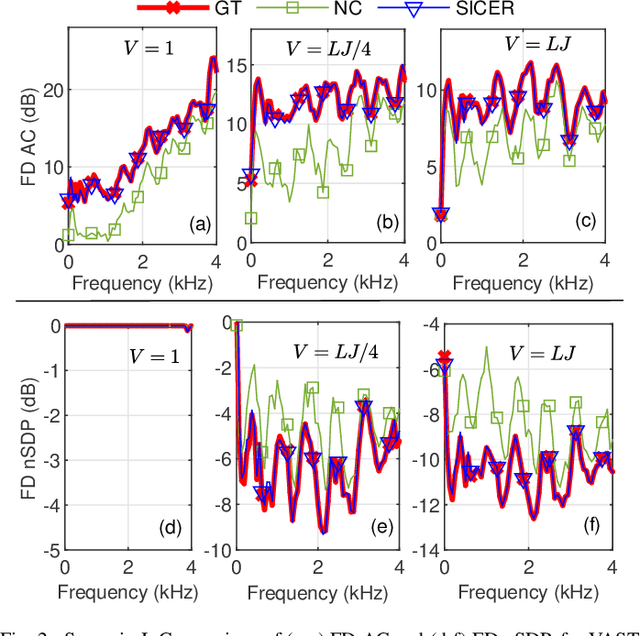
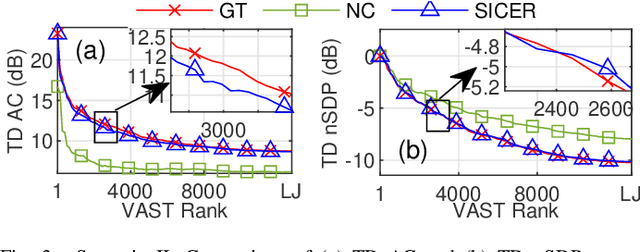
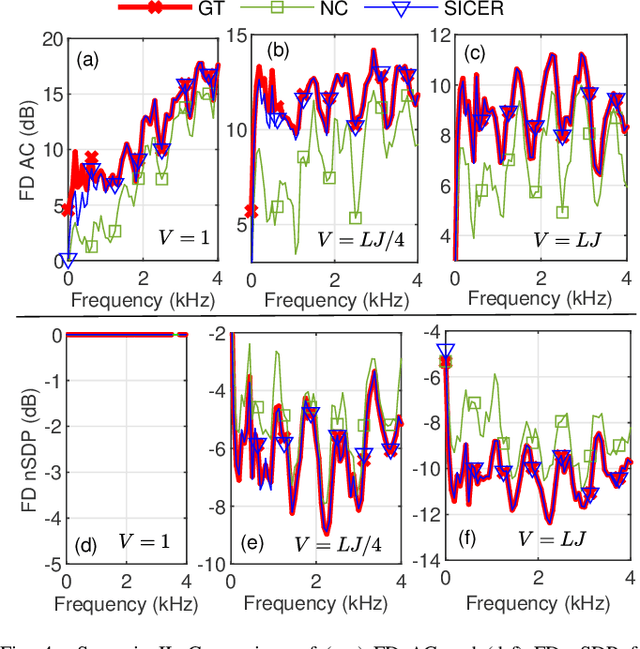
Sound zone control (SZC) implemented using static optimal filters is significantly affected by various perturbations in the acoustic environment, an important one being the fluctuation in the speed of sound, which is in turn influenced by changes in temperature and humidity (TH). This issue arises because control algorithms typically use pre-recorded, static impulse responses (IRs) to design the optimal control filters. The IRs, however, may change with time due to TH changes, which renders the derived control filters to become non-optimal. To address this challenge, we propose a straightforward model called sinc interpolation-compression/expansion-resampling (SICER), which adjusts the IRs to account for both sound speed reduction and increase. Using the proposed technique, IRs measured at a certain TH can be corrected for any TH change and control filters can be re-derived without the need of re-measuring the new IRs (which is impractical when SZC is deployed). We integrate the proposed SICER IR correction method with the recently introduced variable span trade-off (VAST) framework for SZC, and propose a SICER-corrected VAST method that is resilient to sound speed variations. Simulation studies show that the proposed SICER-corrected VAST approach significantly improves acoustic contrast and reduces signal distortion in the presence of sound speed changes.
Frequency bin-wise single channel speech presence probability estimation using multiple DNNs
Feb 23, 2023In this work, we propose a frequency bin-wise method to estimate the single-channel speech presence probability (SPP) with multiple deep neural networks (DNNs) in the short-time Fourier transform domain. Since all frequency bins are typically considered simultaneously as input features for conventional DNN-based SPP estimators, high model complexity is inevitable. To reduce the model complexity and the requirements on the training data, we take a single frequency bin and some of its neighboring frequency bins into account to train separate gate recurrent units. In addition, the noisy speech and the a posteriori probability SPP representation are used to train our model. The experiments were performed on the Deep Noise Suppression challenge dataset. The experimental results show that the speech detection accuracy can be improved when we employ the frequency bin-wise model. Finally, we also demonstrate that our proposed method outperforms most of the state-of-the-art SPP estimation methods in terms of speech detection accuracy and model complexity.
Bayesian Pitch Tracking Based on the Harmonic Model
May 21, 2019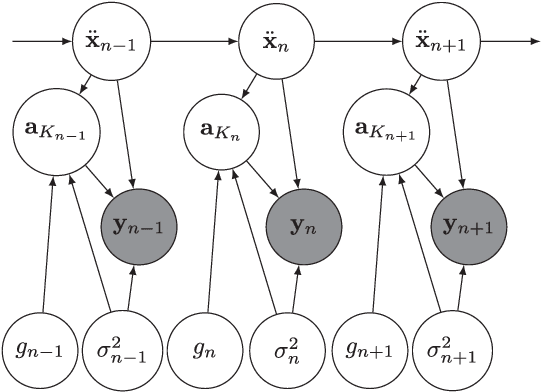
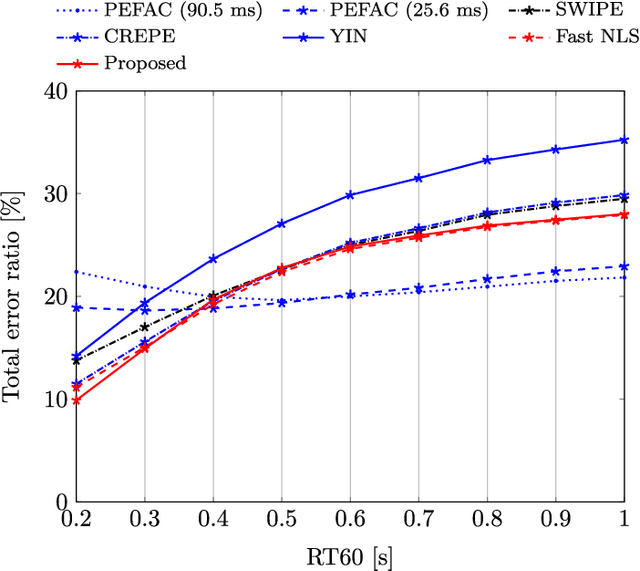
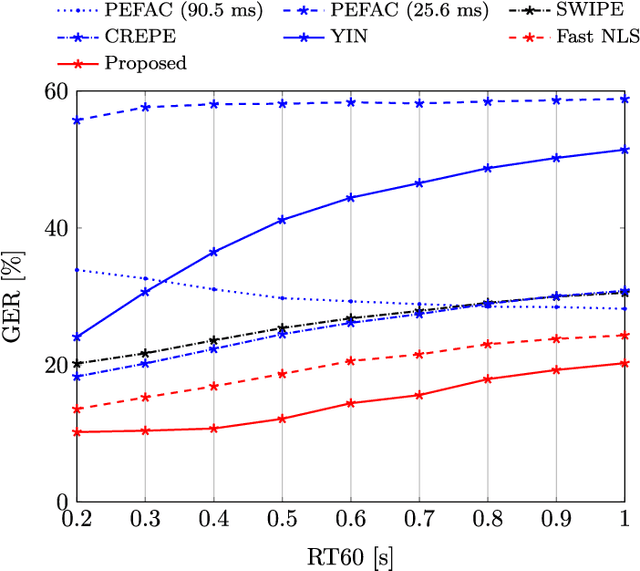
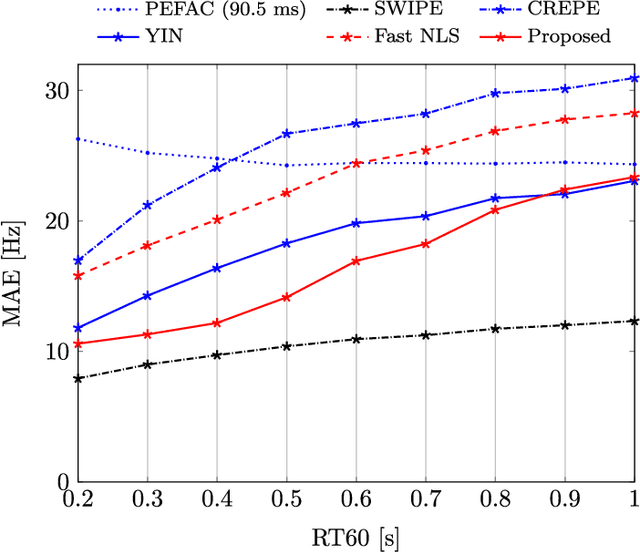
Fundamental frequency is one of the most important characteristics of speech and audio signals. Harmonic model-based fundamental frequency estimators offer a higher estimation accuracy and robustness against noise than the widely used autocorrelation-based methods. However, the traditional harmonic model-based estimators do not take the temporal smoothness of the fundamental frequency, the model order, and the voicing into account as they process each data segment independently. In this paper, a fully Bayesian fundamental frequency tracking algorithm based on the harmonic model and a first-order Markov process model is proposed. Smoothness priors are imposed on the fundamental frequencies, model orders, and voicing using first-order Markov process models. Using these Markov models, fundamental frequency estimation and voicing detection errors can be reduced. Using the harmonic model, the proposed fundamental frequency tracker has an improved robustness to noise. An analytical form of the likelihood function, which can be computed efficiently, is derived. Compared to the state-of-the-art neural network and non-parametric approaches, the proposed fundamental frequency tracking algorithm reduces the mean absolute errors and gross errors by 15\% and 20\% on the Keele pitch database and 36\% and 26\% on sustained /a/ sounds from a database of Parkinson's disease voices under 0 dB white Gaussian noise. A MATLAB version of the proposed algorithm is made freely available for reproduction of the results\footnote{An implementation of the proposed algorithm using MATLAB may be found in \url{https://tinyurl.com/yxn4a543}
A Variational EM Method for Pole-Zero Modeling of Speech with Mixed Block Sparse and Gaussian Excitation
Jun 24, 2017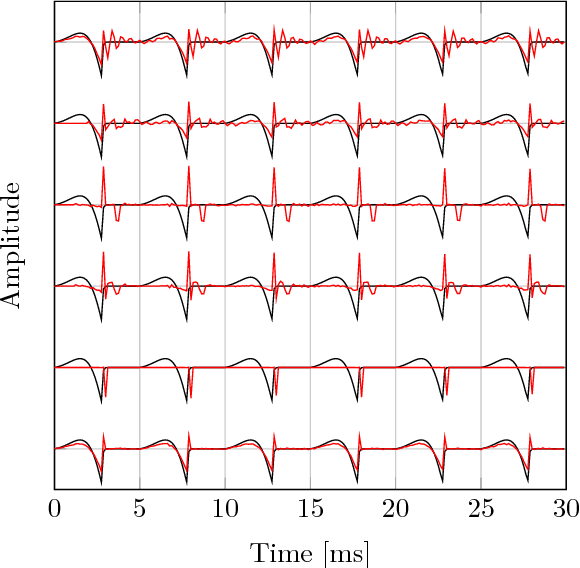
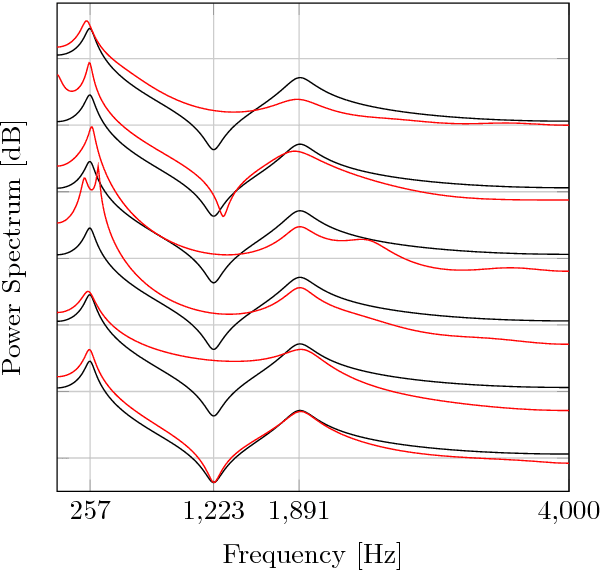

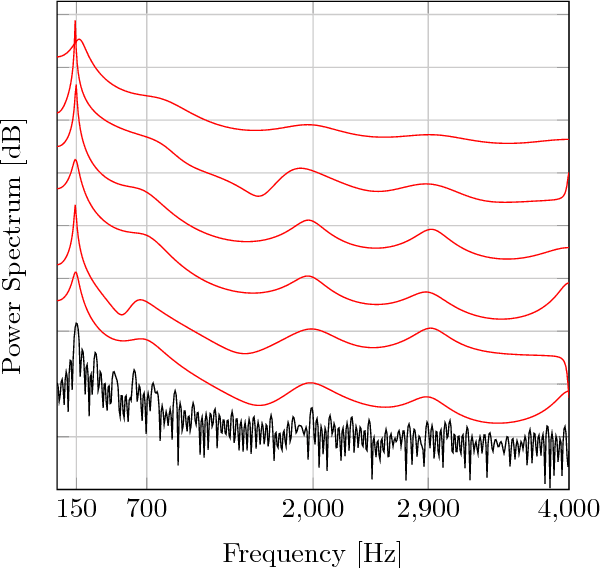
The modeling of speech can be used for speech synthesis and speech recognition. We present a speech analysis method based on pole-zero modeling of speech with mixed block sparse and Gaussian excitation. By using a pole-zero model, instead of the all-pole model, a better spectral fitting can be expected. Moreover, motivated by the block sparse glottal flow excitation during voiced speech and the white noise excitation for unvoiced speech, we model the excitation sequence as a combination of block sparse signals and white noise. A variational EM (VEM) method is proposed for estimating the posterior PDFs of the block sparse residuals and point estimates of mod- elling parameters within a sparse Bayesian learning framework. Compared to conventional pole-zero and all-pole based methods, experimental results show that the proposed method has lower spectral distortion and good performance in reconstructing of the block sparse excitation.