 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Fixed-Filter Sound Zone Control with Audio-Based Position Tracking
Oct 10, 2024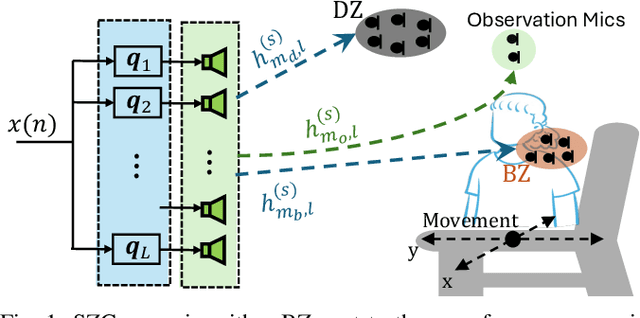
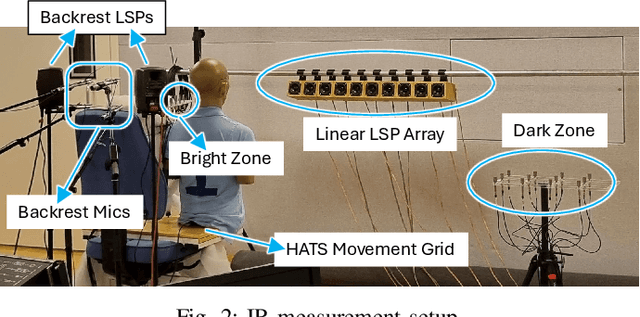
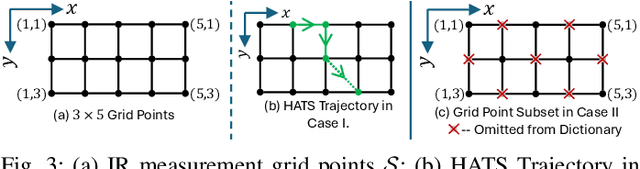
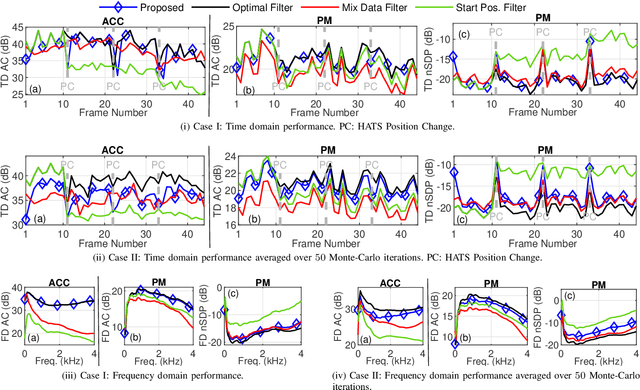
Performance of sound zone control (SZC) systems deployed in practical scenarios are highly sensitive to the location of the listener(s) and can degrade significantly when listener(s) are moving. This paper presents a robust SZC system that adapts to dynamic changes such as moving listeners and varying zone locations using a dictionary-based approach. The proposed system continuously monitors the environment and updates the fixed control filters by tracking the listener position using audio signals only. To test the effectiveness of the proposed SZC method, simulation studies are carried out using practically measured impulse responses. These studies show that SZC, when incorporated with the proposed audio-only position tracking scheme, achieves optimal performance when all listener positions are available in the dictionary. Moreover, even when not all listener positions are included in the dictionary, the method still provides good performance improvement compared to a traditional fixed filter SZC scheme.
Minimum Processing Near-end Listening Enhancement
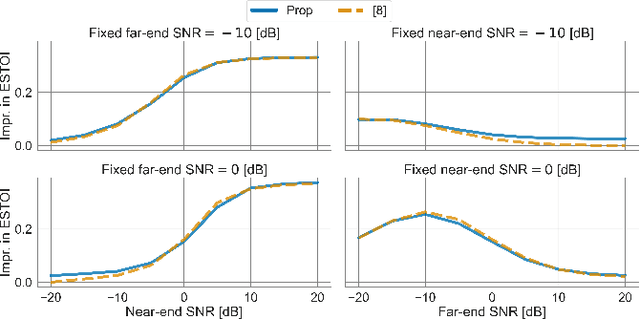
Oct 31, 2022The intelligibility and quality of speech from a mobile phone or public announcement system are often affected by background noise in the listening environment. By pre-processing the speech signal it is possible to improve the speech intelligibility and quality -- this is known as near-end listening enhancement (NLE). Although, existing NLE techniques are able to greatly increase intelligibility in harsh noise environments, in favorable noise conditions the intelligibility of speech reaches a ceiling where it cannot be further enhanced. Actually, the focus of existing methods solely on improving the intelligibility causes unnecessary processing of the speech signal and leads to speech distortions and quality degradations. In this paper, we provide a new rationale for NLE, where the target speech is minimally processed in terms of a processing penalty, provided that a certain performance constraint, e.g., intelligibility, is satisfied. We present a closed-form solution for the case where the performance criterion is an intelligibility estimator based on the approximated speech intelligibility index and the processing penalty is the mean-square error between the processed and the clean speech. This produces an NLE method that adapts to changing noise conditions via a simple gain rule by limiting the processing to the minimum necessary to achieve a desired intelligibility, while at the same time focusing on quality in favorable noise situations by minimizing the amount of speech distortions. Through simulation studies, we show the proposed method attains speech quality on par or better than existing methods in both objective measurements and subjective listening tests, whilst still sustaining objective speech intelligibility performance on par with existing methods.
Joint Far- and Near-End Speech Intelligibility Enhancement based on the Approximated Speech Intelligibility Index
Nov 15, 2021
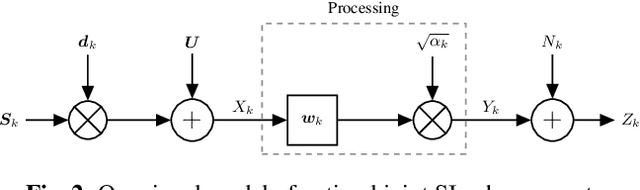
This paper considers speech enhancement of signals picked up in one noisy environment which must be presented to a listener in another noisy environment. Recently, it has been shown that an optimal solution to this problem requires the consideration of the noise sources in both environments jointly. However, the existing optimal mutual information based method requires a complicated system model that includes natural speech variations, and relies on approximations and assumptions of the underlying signal distributions. In this paper, we propose to use a simpler signal model and optimize speech intelligibility based on the Approximated Speech Intelligibility Index (ASII). We derive a closed-form solution to the joint far- and near-end speech enhancement problem that is independent of the marginal distribution of signal coefficients, and that achieves similar performance to existing work. In addition, we do not need to model or optimize for natural speech variations.
Improvement of Noise-Robust Single-Channel Voice Activity Detection with Spatial Pre-processing
Apr 12, 2021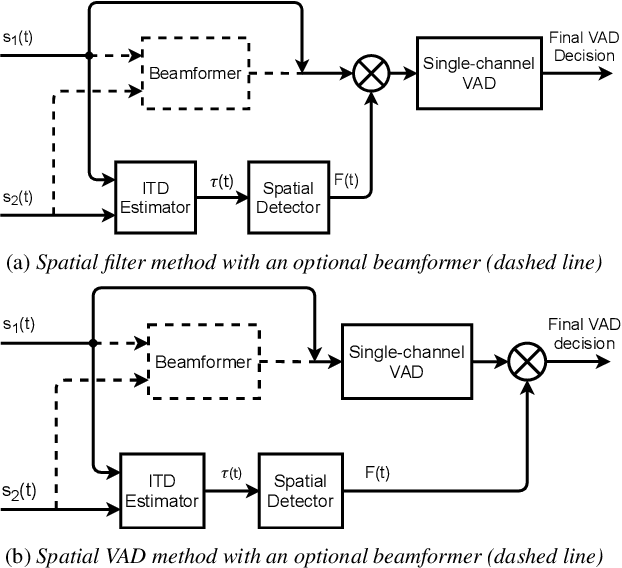
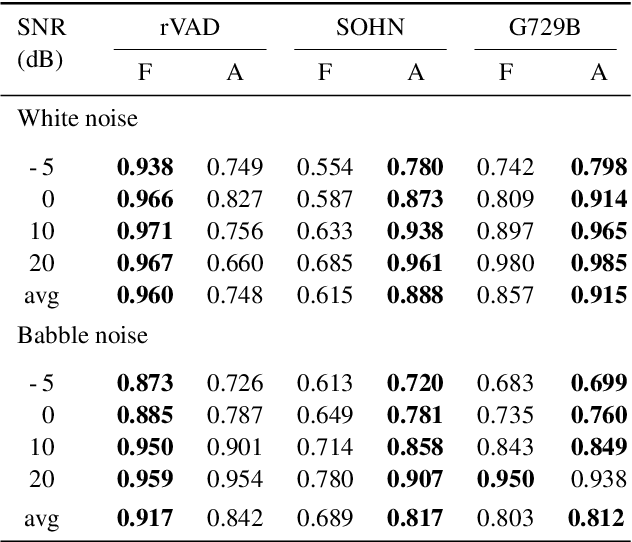
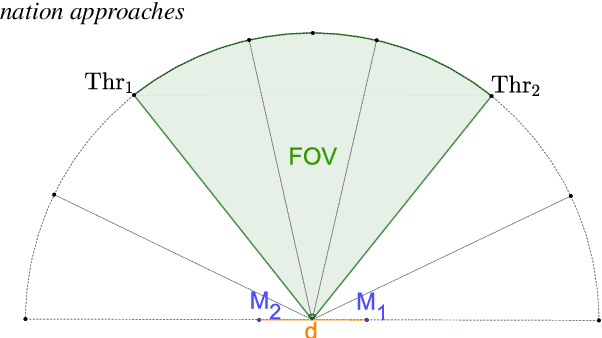
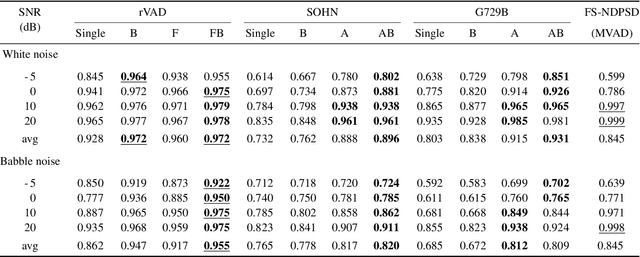
Voice activity detection (VAD) remains a challenge in noisy environments. With access to multiple microphones, prior studies have attempted to improve the noise robustness of VAD by creating multi-channel VAD (MVAD) methods. However, MVAD is relatively new compared to single-channel VAD (SVAD), which has been thoroughly developed in the past. It might therefore be advantageous to improve SVAD methods with pre-processing to obtain superior VAD, which is under-explored. This paper improves SVAD through two pre-processing methods, a beamformer and a spatial target speaker detector. The spatial detector sets signal frames to zero when no potential speaker is present within a target direction. The detector may be implemented as a filter, meaning the input signal for the SVAD is filtered according to the detector's output; or it may be implemented as a spatial VAD to be combined with the SVAD output. The evaluation is made on a noisy reverberant speech database, with clean speech from the Aurora 2 database and with white and babble noise. The results show that SVAD algorithms are significantly improved by the presented pre-processing methods, especially the spatial detector, across all signal-to-noise ratios. The SVAD algorithms with pre-processing significantly outperform a baseline MVAD in challenging noise conditions.