 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Resolution-Wise Shared Attention in Hybrid Mamba-U-Nets for Improved Cross-Corpus Speech Enhancement
Oct 02, 2025Recent advances in speech enhancement have shown that models combining Mamba and attention mechanisms yield superior cross-corpus generalization performance. At the same time, integrating Mamba in a U-Net structure has yielded state-of-the-art enhancement performance, while reducing both model size and computational complexity. Inspired by these insights, we propose RWSA-MambaUNet, a novel and efficient hybrid model combining Mamba and multi-head attention in a U-Net structure for improved cross-corpus performance. Resolution-wise shared attention (RWSA) refers to layerwise attention-sharing across corresponding time- and frequency resolutions. Our best-performing RWSA-MambaUNet model achieves state-of-the-art generalization performance on two out-of-domain test sets. Notably, our smallest model surpasses all baselines on the out-of-domain DNS 2020 test set in terms of PESQ, SSNR, and ESTOI, and on the out-of-domain EARS-WHAM_v2 test set in terms of SSNR, ESTOI, and SI-SDR, while using less than half the model parameters and a fraction of the FLOPs.
Learning Robust Spatial Representations from Binaural Audio through Feature Distillation
Aug 28, 2025Recently, deep representation learning has shown strong performance in multiple audio tasks. However, its use for learning spatial representations from multichannel audio is underexplored. We investigate the use of a pretraining stage based on feature distillation to learn a robust spatial representation of binaural speech without the need for data labels. In this framework, spatial features are computed from clean binaural speech samples to form prediction labels. These clean features are then predicted from corresponding augmented speech using a neural network. After pretraining, we throw away the spatial feature predictor and use the learned encoder weights to initialize a DoA estimation model which we fine-tune for DoA estimation. Our experiments demonstrate that the pretrained models show improved performance in noisy and reverberant environments after fine-tuning for direction-of-arrival estimation, when compared to fully supervised models and classic signal processing methods.
Head-steered channel selection method for hearing aid applications using remote microphones
Aug 09, 2025We propose a channel selection method for hearing aid applications using remote microphones, in the presence of multiple competing talkers. The proposed channel selection method uses the hearing aid user's head-steering direction to identify the remote channel originating from the frontal direction of the hearing aid user, which captures the target talker signal. We pose the channel selection task as a multiple hypothesis testing problem, and derive a maximum likelihood solution. Under realistic, simplifying assumptions, the solution selects the remote channel which has the highest weighted squared absolute correlation coefficient with the output of the head-steered hearing aid beamformer. We analyze the performance of the proposed channel selection method using close-talking remote microphones and table microphone arrays. Through simulations using realistic acoustic scenes, we show that the proposed channel selection method consistently outperforms existing methods in accurately finding the remote channel that captures the target talker signal, in the presence of multiple competing talkers, without the use of any additional sensors.
Binaural Localization Model for Speech in Noise
Jul 26, 2025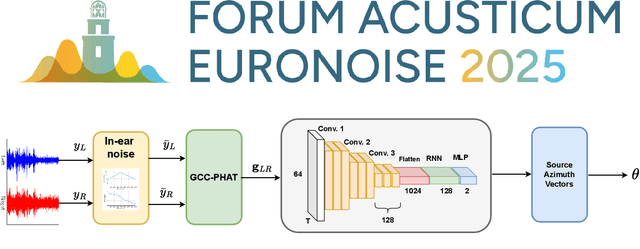
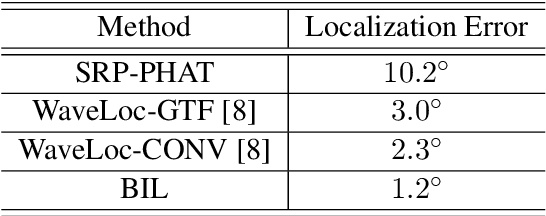
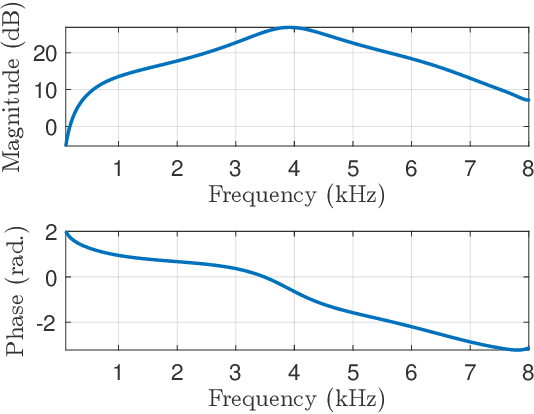
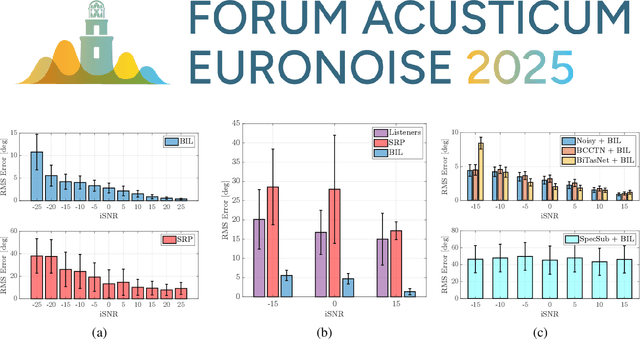
Binaural acoustic source localization is important to human listeners for spatial awareness, communication and safety. In this paper, an end-to-end binaural localization model for speech in noise is presented. A lightweight convolutional recurrent network that localizes sound in the frontal azimuthal plane for noisy reverberant binaural signals is introduced. The model incorporates additive internal ear noise to represent the frequency-dependent hearing threshold of a typical listener. The localization performance of the model is compared with the steered response power algorithm, and the use of the model as a measure of interaural cue preservation for binaural speech enhancement methods is studied. A listening test was performed to compare the performance of the model with human localization of speech in noisy conditions.
MambAttention: Mamba with Multi-Head Attention for Generalizable Single-Channel Speech Enhancement
Jul 01, 2025



With the advent of new sequence models like Mamba and xLSTM, several studies have shown that these models match or outperform state-of-the-art models in single-channel speech enhancement, automatic speech recognition, and self-supervised audio representation learning. However, prior research has demonstrated that sequence models like LSTM and Mamba tend to overfit to the training set. To address this issue, previous works have shown that adding self-attention to LSTMs substantially improves generalization performance for single-channel speech enhancement. Nevertheless, neither the concept of hybrid Mamba and time-frequency attention models nor their generalization performance have been explored for speech enhancement. In this paper, we propose a novel hybrid architecture, MambAttention, which combines Mamba and shared time- and frequency-multi-head attention modules for generalizable single-channel speech enhancement. To train our model, we introduce VoiceBank+Demand Extended (VB-DemandEx), a dataset inspired by VoiceBank+Demand but with more challenging noise types and lower signal-to-noise ratios. Trained on VB-DemandEx, our proposed MambAttention model significantly outperforms existing state-of-the-art LSTM-, xLSTM-, Mamba-, and Conformer-based systems of similar complexity across all reported metrics on two out-of-domain datasets: DNS 2020 and EARS-WHAM_v2, while matching their performance on the in-domain dataset VB-DemandEx. Ablation studies highlight the role of weight sharing between the time- and frequency-multi-head attention modules for generalization performance. Finally, we explore integrating the shared time- and frequency-multi-head attention modules with LSTM and xLSTM, which yields a notable performance improvement on the out-of-domain datasets. However, our MambAttention model remains superior on both out-of-domain datasets across all reported evaluation metrics.
xLSTM-SENet: xLSTM for Single-Channel Speech Enhancement
Jan 10, 2025



While attention-based architectures, such as Conformers, excel in speech enhancement, they face challenges such as scalability with respect to input sequence length. In contrast, the recently proposed Extended Long Short-Term Memory (xLSTM) architecture offers linear scalability. However, xLSTM-based models remain unexplored for speech enhancement. This paper introduces xLSTM-SENet, the first xLSTM-based single-channel speech enhancement system. A comparative analysis reveals that xLSTM-and notably, even LSTM-can match or outperform state-of-the-art Mamba- and Conformer-based systems across various model sizes in speech enhancement on the VoiceBank+Demand dataset. Through ablation studies, we identify key architectural design choices such as exponential gating and bidirectionality contributing to its effectiveness. Our best xLSTM-based model, xLSTM-SENet2, outperforms state-of-the-art Mamba- and Conformer-based systems on the Voicebank+DEMAND dataset.
Noise-Robust Target-Speaker Voice Activity Detection Through Self-Supervised Pretraining
Jan 06, 2025



Target-Speaker Voice Activity Detection (TS-VAD) is the task of detecting the presence of speech from a known target-speaker in an audio frame. Recently, deep neural network-based models have shown good performance in this task. However, training these models requires extensive labelled data, which is costly and time-consuming to obtain, particularly if generalization to unseen environments is crucial. To mitigate this, we propose a causal, Self-Supervised Learning (SSL) pretraining framework, called Denoising Autoregressive Predictive Coding (DN-APC), to enhance TS-VAD performance in noisy conditions. We also explore various speaker conditioning methods and evaluate their performance under different noisy conditions. Our experiments show that DN-APC improves performance in noisy conditions, with a general improvement of approx. 2% in both seen and unseen noise. Additionally, we find that FiLM conditioning provides the best overall performance. Representation analysis via tSNE plots reveals robust initial representations of speech and non-speech from pretraining. This underscores the effectiveness of SSL pretraining in improving the robustness and performance of TS-VAD models in noisy environments.
Noise-Robust Hearing Aid Voice Control
Nov 05, 2024



Advancing the design of robust hearing aid (HA) voice control is crucial to increase the HA use rate among hard of hearing people as well as to improve HA users' experience. In this work, we contribute towards this goal by, first, presenting a novel HA speech dataset consisting of noisy own voice captured by 2 behind-the-ear (BTE) and 1 in-ear-canal (IEC) microphones. Second, we provide baseline HA voice control results from the evaluation of light, state-of-the-art keyword spotting models utilizing different combinations of HA microphone signals. Experimental results show the benefits of exploiting bandwidth-limited bone-conducted speech (BCS) from the IEC microphone to achieve noise-robust HA voice control. Furthermore, results also demonstrate that voice control performance can be boosted by assisting BCS by the broader-bandwidth BTE microphone signals. Aiming at setting a baseline upon which the scientific community can continue to progress, the HA noisy speech dataset has been made publicly available.
The Effect of Training Dataset Size on Discriminative and Diffusion-Based Speech Enhancement Systems
Jun 10, 2024



The performance of deep neural network-based speech enhancement systems typically increases with the training dataset size. However, studies that investigated the effect of training dataset size on speech enhancement performance did not consider recent approaches, such as diffusion-based generative models. Diffusion models are typically trained with massive datasets for image generation tasks, but whether this is also required for speech enhancement is unknown. Moreover, studies that investigated the effect of training dataset size did not control for the data diversity. It is thus unclear whether the performance improvement was due to the increased dataset size or diversity. Therefore, we systematically investigate the effect of training dataset size on the performance of popular state-of-the-art discriminative and diffusion-based speech enhancement systems. We control for the data diversity by using a fixed set of speech utterances, noise segments and binaural room impulse responses to generate datasets of different sizes. We find that the diffusion-based systems do not benefit from increasing the training dataset size as much as the discriminative systems. They perform the best relative to the discriminative systems with datasets of 10 h or less, but they are outperformed by the discriminative systems with datasets of 100 h or more.
Deep low-latency joint speech transmission and enhancement over a gaussian channel
Apr 30, 2024



Ensuring intelligible speech communication for hearing assistive devices in low-latency scenarios presents significant challenges in terms of speech enhancement, coding and transmission. In this paper, we propose novel solutions for low-latency joint speech transmission and enhancement, leveraging deep neural networks (DNNs). Our approach integrates two state-of-the-art DNN architectures for low-latency speech enhancement and low-latency analog joint source-channel-based transmission, creating a combined low-latency system and jointly training both systems in an end-to-end approach. Due to the computational demands of the enhancement system, this order is suitable when high computational power is unavailable in the decoder, like hearing assistive devices. The proposed system enables the configuration of total latency, achieving high performance even at latencies as low as 3 ms, which is typically challenging to attain. The simulation results provide compelling evidence that a joint enhancement and transmission system is superior to a simple concatenation system in diverse settings, encompassing various wireless channel conditions, latencies, and background noise scenarios.