 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Spatial Representations from Binaural Audio through Feature Distillation
Aug 28, 2025Recently, deep representation learning has shown strong performance in multiple audio tasks. However, its use for learning spatial representations from multichannel audio is underexplored. We investigate the use of a pretraining stage based on feature distillation to learn a robust spatial representation of binaural speech without the need for data labels. In this framework, spatial features are computed from clean binaural speech samples to form prediction labels. These clean features are then predicted from corresponding augmented speech using a neural network. After pretraining, we throw away the spatial feature predictor and use the learned encoder weights to initialize a DoA estimation model which we fine-tune for DoA estimation. Our experiments demonstrate that the pretrained models show improved performance in noisy and reverberant environments after fine-tuning for direction-of-arrival estimation, when compared to fully supervised models and classic signal processing methods.
Noise-Robust Target-Speaker Voice Activity Detection Through Self-Supervised Pretraining
Jan 06, 2025



Target-Speaker Voice Activity Detection (TS-VAD) is the task of detecting the presence of speech from a known target-speaker in an audio frame. Recently, deep neural network-based models have shown good performance in this task. However, training these models requires extensive labelled data, which is costly and time-consuming to obtain, particularly if generalization to unseen environments is crucial. To mitigate this, we propose a causal, Self-Supervised Learning (SSL) pretraining framework, called Denoising Autoregressive Predictive Coding (DN-APC), to enhance TS-VAD performance in noisy conditions. We also explore various speaker conditioning methods and evaluate their performance under different noisy conditions. Our experiments show that DN-APC improves performance in noisy conditions, with a general improvement of approx. 2% in both seen and unseen noise. Additionally, we find that FiLM conditioning provides the best overall performance. Representation analysis via tSNE plots reveals robust initial representations of speech and non-speech from pretraining. This underscores the effectiveness of SSL pretraining in improving the robustness and performance of TS-VAD models in noisy environments.
Noise-Robust Keyword Spotting through Self-supervised Pretraining
Mar 27, 2024



Voice assistants are now widely available, and to activate them a keyword spotting (KWS) algorithm is used. Modern KWS systems are mainly trained using supervised learning methods and require a large amount of labelled data to achieve a good performance. Leveraging unlabelled data through self-supervised learning (SSL) has been shown to increase the accuracy in clean conditions. This paper explores how SSL pretraining such as Data2Vec can be used to enhance the robustness of KWS models in noisy conditions, which is under-explored. Models of three different sizes are pretrained using different pretraining approaches and then fine-tuned for KWS. These models are then tested and compared to models trained using two baseline supervised learning methods, one being standard training using clean data and the other one being multi-style training (MTR). The results show that pretraining and fine-tuning on clean data is superior to supervised learning on clean data across all testing conditions, and superior to supervised MTR for testing conditions of SNR above 5 dB. This indicates that pretraining alone can increase the model's robustness. Finally, it is found that using noisy data for pretraining models, especially with the Data2Vec-denoising approach, significantly enhances the robustness of KWS models in noisy conditions.
Self-supervised Pretraining for Robust Personalized Voice Activity Detection in Adverse Conditions
Dec 27, 2023



In this paper, we propose the use of self-supervised pretraining on a large unlabelled data set to improve the performance of a personalized voice activity detection (VAD) model in adverse conditions. We pretrain a long short-term memory (LSTM)-encoder using the autoregressive predictive coding (APC) framework and fine-tune it for personalized VAD. We also propose a denoising variant of APC, with the goal of improving the robustness of personalized VAD. The trained models are systematically evaluated on both clean speech and speech contaminated by various types of noise at different SNR-levels and compared to a purely supervised model. Our experiments show that self-supervised pretraining not only improves performance in clean conditions, but also yields models which are more robust to adverse conditions compared to purely supervised learning.
Improving Label-Deficient Keyword Spotting Using Self-Supervised Pretraining
Oct 04, 2022
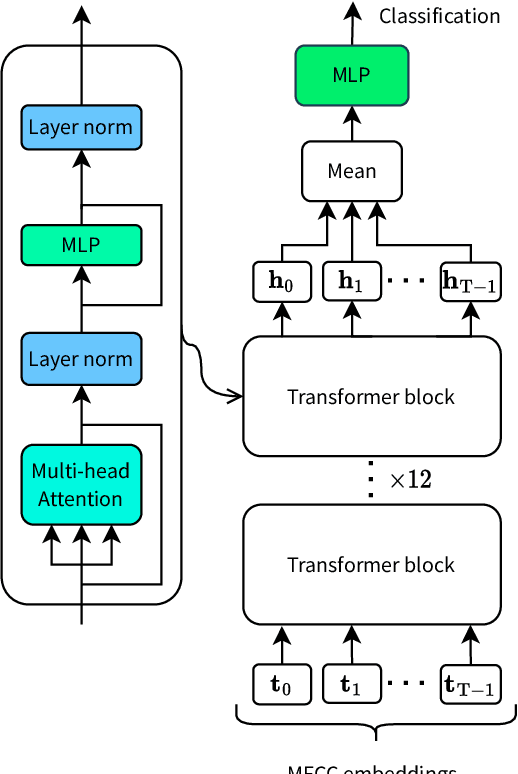

In recent years, the development of accurate deep keyword spotting (KWS) models has resulted in KWS technology being embedded in a number of technologies such as voice assistants. Many of these models rely on large amounts of labelled data to achieve good performance. As a result, their use is restricted to applications for which a large labelled speech data set can be obtained. Self-supervised learning seeks to mitigate the need for large labelled data sets by leveraging unlabelled data, which is easier to obtain in large amounts. However, most self-supervised methods have only been investigated for very large models, whereas KWS models are desired to be small. In this paper, we investigate the use of self-supervised pretraining for the smaller KWS models in a label-deficient scenario. We pretrain the Keyword Transformer model using the self-supervised framework Data2Vec and carry out experiments on a label-deficient setup of the Google Speech Commands data set. It is found that the pretrained models greatly outperform the models without pretraining, showing that Data2Vec pretraining can increase the performance of KWS models in label-deficient scenarios. The source code is made publicly available.
Explainable Machine Learning for Breakdown Prediction in High Gradient RF Cavities
Feb 10, 2022
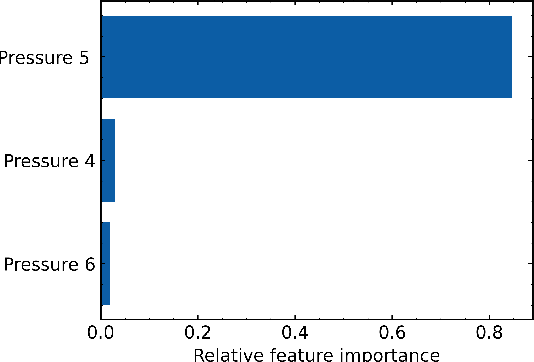

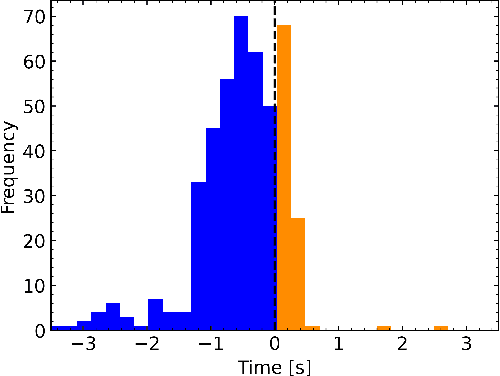
Radio Frequency (RF) breakdowns are one of the most prevalent limiting factors in RF cavities for particle accelerators. During a breakdown, field enhancement associated with small deformations on the cavity surface results in electrical arcs. Such arcs lead to beam aborts, reduce machine availability and can cause irreparable damage on the RF cavity surface. In this paper, we propose a machine learning strategy to discover breakdown precursors in CERN's Compact Linear Collider (CLIC) accelerating structures. By interpreting the parameters of the learned models with explainable Artificial Intelligence (AI), we reverse-engineer physical properties for deriving fast, reliable, and simple rule based models. Based on 6 months of historical data and dedicated experiments, our models show fractions of data with high influence on the occurrence of breakdowns. Specifically, it is shown that in many cases a rise of the vacuum pressure is observed before a breakdown is detected with the current interlock sensors.