 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Label-Deficient Keyword Spotting Using Self-Supervised Pretraining
Paper and Code

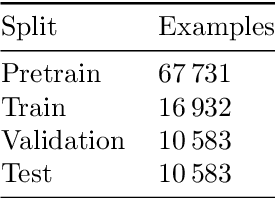
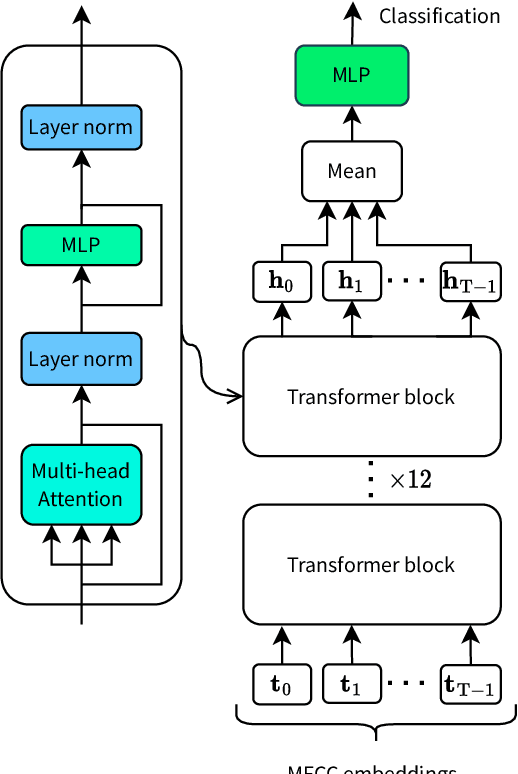

In recent years, the development of accurate deep keyword spotting (KWS) models has resulted in KWS technology being embedded in a number of technologies such as voice assistants. Many of these models rely on large amounts of labelled data to achieve good performance. As a result, their use is restricted to applications for which a large labelled speech data set can be obtained. Self-supervised learning seeks to mitigate the need for large labelled data sets by leveraging unlabelled data, which is easier to obtain in large amounts. However, most self-supervised methods have only been investigated for very large models, whereas KWS models are desired to be small. In this paper, we investigate the use of self-supervised pretraining for the smaller KWS models in a label-deficient scenario. We pretrain the Keyword Transformer model using the self-supervised framework Data2Vec and carry out experiments on a label-deficient setup of the Google Speech Commands data set. It is found that the pretrained models greatly outperform the models without pretraining, showing that Data2Vec pretraining can increase the performance of KWS models in label-deficient scenarios. The source code is made publicly available.