 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Training Dataset Size on Discriminative and Diffusion-Based Speech Enhancement Systems
Jun 10, 2024



The performance of deep neural network-based speech enhancement systems typically increases with the training dataset size. However, studies that investigated the effect of training dataset size on speech enhancement performance did not consider recent approaches, such as diffusion-based generative models. Diffusion models are typically trained with massive datasets for image generation tasks, but whether this is also required for speech enhancement is unknown. Moreover, studies that investigated the effect of training dataset size did not control for the data diversity. It is thus unclear whether the performance improvement was due to the increased dataset size or diversity. Therefore, we systematically investigate the effect of training dataset size on the performance of popular state-of-the-art discriminative and diffusion-based speech enhancement systems. We control for the data diversity by using a fixed set of speech utterances, noise segments and binaural room impulse responses to generate datasets of different sizes. We find that the diffusion-based systems do not benefit from increasing the training dataset size as much as the discriminative systems. They perform the best relative to the discriminative systems with datasets of 10 h or less, but they are outperformed by the discriminative systems with datasets of 100 h or more.
Investigating the Design Space of Diffusion Models for Speech Enhancement
Dec 07, 2023



Diffusion models are a new class of generative models that have shown outstanding performance in image generation literature. As a consequence, studies have attempted to apply diffusion models to other tasks, such as speech enhancement. A popular approach in adapting diffusion models to speech enhancement consists in modelling a progressive transformation between the clean and noisy speech signals. However, one popular diffusion model framework previously laid in image generation literature did not account for such a transformation towards the system input, which prevents from relating the existing diffusion-based speech enhancement systems with the aforementioned diffusion model framework. To address this, we extend this framework to account for the progressive transformation between the clean and noisy speech signals. This allows us to apply recent developments from image generation literature, and to systematically investigate design aspects of diffusion models that remain largely unexplored for speech enhancement, such as the neural network preconditioning, the training loss weighting, the stochastic differential equation (SDE), or the amount of stochasticity injected in the reverse process. We show that the performance of previous diffusion-based speech enhancement systems cannot be attributed to the progressive transformation between the clean and noisy speech signals. Moreover, we show that a proper choice of preconditioning, training loss weighting, SDE and sampler allows to outperform a popular diffusion-based speech enhancement system in terms of perceptual metrics while using fewer sampling steps, thus reducing the computational cost by a factor of four.
Diffusion-Based Speech Enhancement in Matched and Mismatched Conditions Using a Heun-Based Sampler
Dec 05, 2023Diffusion models are a new class of generative models that have recently been applied to speech enhancement successfully. Previous works have demonstrated their superior performance in mismatched conditions compared to state-of-the art discriminative models. However, this was investigated with a single database for training and another one for testing, which makes the results highly dependent on the particular databases. Moreover, recent developments from the image generation literature remain largely unexplored for speech enhancement. These include several design aspects of diffusion models, such as the noise schedule or the reverse sampler. In this work, we systematically assess the generalization performance of a diffusion-based speech enhancement model by using multiple speech, noise and binaural room impulse response (BRIR) databases to simulate mismatched acoustic conditions. We also experiment with a noise schedule and a sampler that have not been applied to speech enhancement before. We show that the proposed system substantially benefits from using multiple databases for training, and achieves superior performance compared to state-of-the-art discriminative models in both matched and mismatched conditions. We also show that a Heun-based sampler achieves superior performance at a smaller computational cost compared to a sampler commonly used for speech enhancement.
Assessing the Generalization Gap of Learning-Based Speech Enhancement Systems in Noisy and Reverberant Environments
Sep 12, 2023



The acoustic variability of noisy and reverberant speech mixtures is influenced by multiple factors, such as the spectro-temporal characteristics of the target speaker and the interfering noise, the signal-to-noise ratio (SNR) and the room characteristics. This large variability poses a major challenge for learning-based speech enhancement systems, since a mismatch between the training and testing conditions can substantially reduce the performance of the system. Generalization to unseen conditions is typically assessed by testing the system with a new speech, noise or binaural room impulse response (BRIR) database different from the one used during training. However, the difficulty of the speech enhancement task can change across databases, which can substantially influence the results. The present study introduces a generalization assessment framework that uses a reference model trained on the test condition, such that it can be used as a proxy for the difficulty of the test condition. This allows to disentangle the effect of the change in task difficulty from the effect of dealing with new data, and thus to define a new measure of generalization performance termed the generalization gap. The procedure is repeated in a cross-validation fashion by cycling through multiple speech, noise, and BRIR databases to accurately estimate the generalization gap. The proposed framework is applied to evaluate the generalization potential of a feedforward neural network (FFNN), Conv-TasNet, DCCRN and MANNER. We find that for all models, the performance degrades the most in speech mismatches, while good noise and room generalization can be achieved by training on multiple databases. Moreover, while recent models show higher performance in matched conditions, their performance substantially decreases in mismatched conditions and can become inferior to that of the FFNN-based system.
On convex conceptual regions in deep network representations
May 26, 2023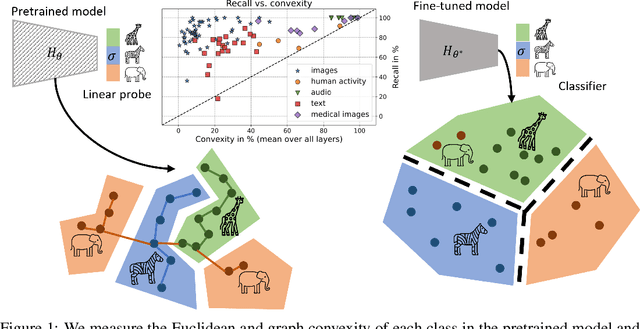
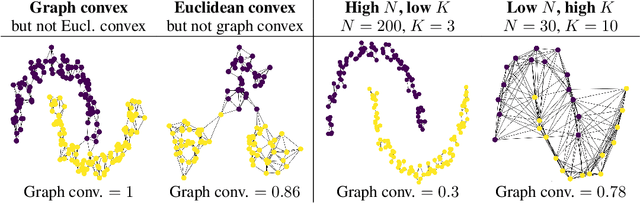

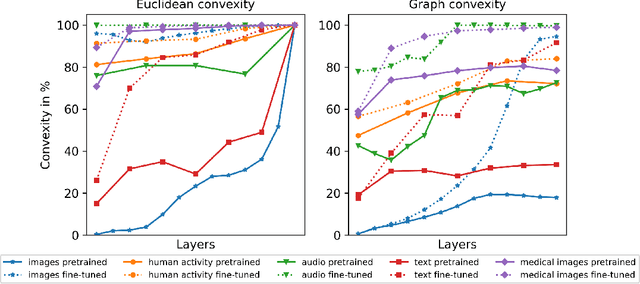
The current study of human-machine alignment aims at understanding the geometry of latent spaces and the correspondence to human representations. G\"ardenfors' conceptual spaces is a prominent framework for understanding human representations. Convexity of object regions in conceptual spaces is argued to promote generalizability, few-shot learning, and intersubject alignment. Based on these insights, we investigate the notion of convexity of concept regions in machine-learned latent spaces. We develop a set of tools for measuring convexity in sampled data and evaluate emergent convexity in layered representations of state-of-the-art deep networks. We show that convexity is robust to basic re-parametrization, hence, meaningful as a quality of machine-learned latent spaces. We find that approximate convexity is pervasive in neural representations in multiple application domains, including models of images, audio, human activity, text, and brain data. We measure convexity separately for labels (i.e., targets for fine-tuning) and other concepts. Generally, we observe that fine-tuning increases the convexity of label regions, while for more general concepts, it depends on the alignment of the concept with the fine-tuning objective. We find evidence that pre-training convexity of class label regions predicts subsequent fine-tuning performance.
On Batching Variable Size Inputs for Training End-to-End Speech Enhancement Systems
Jan 25, 2023



The performance of neural network-based speech enhancement systems is primarily influenced by the model architecture, whereas training times and computational resource utilization are primarily affected by training parameters such as the batch size. Since noisy and reverberant speech mixtures can have different duration, a batching strategy is required to handle variable size inputs during training, in particular for state-of-the-art end-to-end systems. Such strategies usually strive a compromise between zero-padding and data randomization, and can be combined with a dynamic batch size for a more consistent amount of data in each batch. However, the effect of these practices on resource utilization and more importantly network performance is not well documented. This paper is an empirical study of the effect of different batching strategies and batch sizes on the training statistics and speech enhancement performance of a Conv-TasNet, evaluated in both matched and mismatched conditions. We find that using a small batch size during training improves performance in both conditions for all batching strategies. Moreover, using sorted or bucket batching with a dynamic batch size allows for reduced training time and GPU memory usage while achieving similar performance compared to random batching with a fixed batch size.
Road Roughness Estimation Using Machine Learning
Jul 02, 2021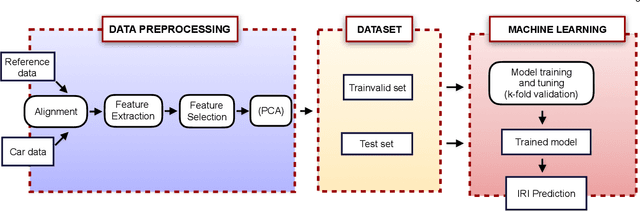

Road roughness is a very important road condition for the infrastructure, as the roughness affects both the safety and ride comfort of passengers. The roads deteriorate over time which means the road roughness must be continuously monitored in order to have an accurate understand of the condition of the road infrastructure. In this paper, we propose a machine learning pipeline for road roughness prediction using the vertical acceleration of the car and the car speed. We compared well-known supervised machine learning models such as linear regression, naive Bayes, k-nearest neighbor, random forest, support vector machine, and the multi-layer perceptron neural network. The models are trained on an optimally selected set of features computed in the temporal and statistical domain. The results demonstrate that machine learning methods can accurately predict road roughness, using the recordings of the cost approachable in-vehicle sensors installed in conventional passenger cars. Our findings demonstrate that the technology is well suited to meet future pavement condition monitoring, by enabling continuous monitoring of a wide road network.
On uncertainty estimation in active learning for image segmentation
Jul 13, 2020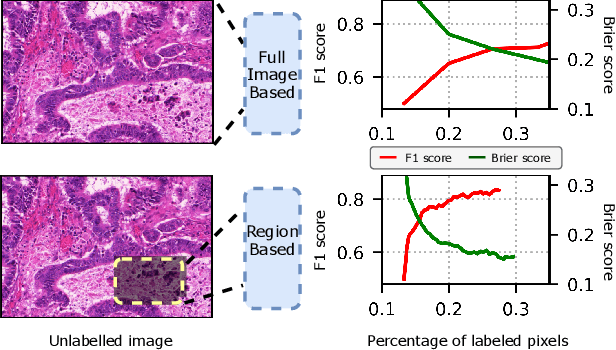

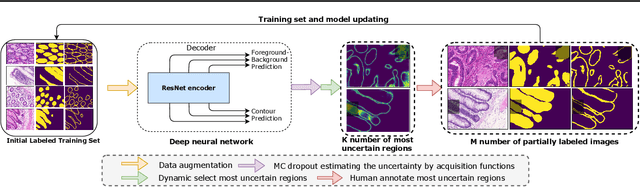
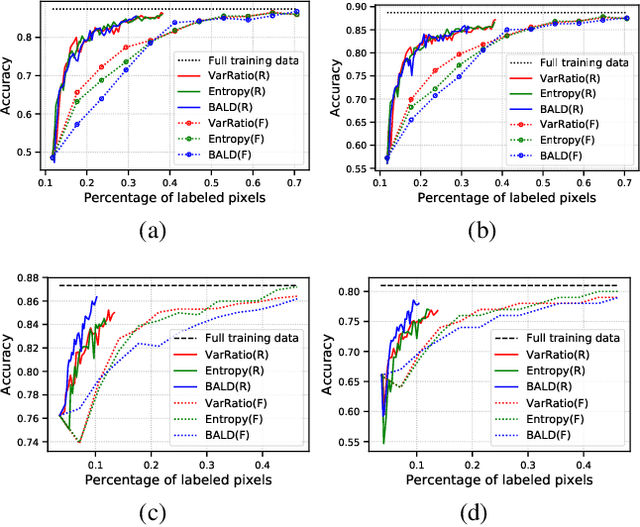
Uncertainty estimation is important for interpreting the trustworthiness of machine learning models in many applications. This is especially critical in the data-driven active learning setting where the goal is to achieve a certain accuracy with minimum labeling effort. In such settings, the model learns to select the most informative unlabeled samples for annotation based on its estimated uncertainty. The highly uncertain predictions are assumed to be more informative for improving model performance. In this paper, we explore uncertainty calibration within an active learning framework for medical image segmentation, an area where labels often are scarce. Various uncertainty estimation methods and acquisition strategies (regions and full images) are investigated. We observe that selecting regions to annotate instead of full images leads to more well-calibrated models. Additionally, we experimentally show that annotating regions can cut 50% of pixels that need to be labeled by humans compared to annotating full images.