 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisG AV-HuBERT: Viseme-Guided AV-HuBERT
Apr 01, 2026Audio-Visual Speech Recognition (AVSR) systems nowadays integrate Large Language Model (LLM) decoders with transformer-based encoders, achieving state-of-the-art results. However, the relative contributions of improved language modelling versus enhanced audiovisual encoding remain unclear. We propose Viseme-Guided AV-HuBERT (VisG AV-HuBERT), a multi-task fine-tuning framework that incorporates auxiliary viseme classification to strengthen the model's reliance on visual articulatory features. By extending AV-HuBERT with a lightweight viseme prediction sub-network, this method explicitly guides the encoder to preserve visual speech information. Evaluated on LRS3, VisG AV-HuBERT achieves comparable or improved performance over the baseline AV-HuBERT, with notable gains under heavy noise conditions. WER reduces from 13.59% to 6.60% (51.4% relative improvement) at -10 dB Signal-to-Noise Ratio (SNR) for Speech noise. Deeper analysis reveals substantial reductions in substitution errors across noise types, demonstrating improved speech unit discrimination. Evaluation on LRS2 confirms generalization capability. Our results demonstrate that explicit viseme modelling enhances encoder representations, and provides a foundation for enhancing noise-robust AVSR through encoder-level improvements.
The Role of Prosodic and Lexical Cues in Turn-Taking with Self-Supervised Speech Representations
Jan 20, 2026Fluid turn-taking remains a key challenge in human-robot interaction. Self-supervised speech representations (S3Rs) have driven many advances, but it remains unclear whether S3R-based turn-taking models rely on prosodic cues, lexical cues or both. We introduce a vocoder-based approach to control prosody and lexical cues in speech more cleanly than prior work. This allows us to probe the voice-activity projection model, an S3R-based turn-taking model. We find that prediction on prosody-matched, unintelligible noise is similar to accuracy on clean speech. This reveals both prosodic and lexical cues support turn-taking, but either can be used in isolation. Hence, future models may only require prosody, providing privacy and potential performance benefits. When either prosodic or lexical information is disrupted, the model exploits the other without further training, indicating they are encoded in S3Rs with limited interdependence. Results are consistent in CPC-based and wav2vec2.0 S3Rs. We discuss our findings and highlight a number of directions for future work. All code is available to support future research.
Interpreting the Role of Visemes in Audio-Visual Speech Recognition
Sep 19, 2025



Audio-Visual Speech Recognition (AVSR) models have surpassed their audio-only counterparts in terms of performance. However, the interpretability of AVSR systems, particularly the role of the visual modality, remains under-explored. In this paper, we apply several interpretability techniques to examine how visemes are encoded in AV-HuBERT a state-of-the-art AVSR model. First, we use t-distributed Stochastic Neighbour Embedding (t-SNE) to visualize learned features, revealing natural clustering driven by visual cues, which is further refined by the presence of audio. Then, we employ probing to show how audio contributes to refining feature representations, particularly for visemes that are visually ambiguous or under-represented. Our findings shed light on the interplay between modalities in AVSR and could point to new strategies for leveraging visual information to improve AVSR performance.
Visual Cues Support Robust Turn-taking Prediction in Noise
May 28, 2025Accurate predictive turn-taking models (PTTMs) are essential for naturalistic human-robot interaction. However, little is known about their performance in noise. This study therefore explores PTTM performance in types of noise likely to be encountered once deployed. Our analyses reveal PTTMs are highly sensitive to noise. Hold/shift accuracy drops from 84% in clean speech to just 52% in 10 dB music noise. Training with noisy data enables a multimodal PTTM, which includes visual features to better exploit visual cues, with 72% accuracy in 10 dB music noise. The multimodal PTTM outperforms the audio-only PTTM across all noise types and SNRs, highlighting its ability to exploit visual cues; however, this does not always generalise to new types of noise. Analysis also reveals that successful training relies on accurate transcription, limiting the use of ASR-derived transcriptions to clean conditions. We make code publicly available for future research.
Visual Cues Enhance Predictive Turn-Taking for Two-Party Human Interaction
May 27, 2025Turn-taking is richly multimodal. Predictive turn-taking models (PTTMs) facilitate naturalistic human-robot interaction, yet most rely solely on speech. We introduce MM-VAP, a multimodal PTTM which combines speech with visual cues including facial expression, head pose and gaze. We find that it outperforms the state-of-the-art audio-only in videoconferencing interactions (84% vs. 79% hold/shift prediction accuracy). Unlike prior work which aggregates all holds and shifts, we group by duration of silence between turns. This reveals that through the inclusion of visual features, MM-VAP outperforms a state-of-the-art audio-only turn-taking model across all durations of speaker transitions. We conduct a detailed ablation study, which reveals that facial expression features contribute the most to model performance. Thus, our working hypothesis is that when interlocutors can see one another, visual cues are vital for turn-taking and must therefore be included for accurate turn-taking prediction. We additionally validate the suitability of automatic speech alignment for PTTM training using telephone speech. This work represents the first comprehensive analysis of multimodal PTTMs. We discuss implications for future work and make all code publicly available.
Language Bias in Self-Supervised Learning For Automatic Speech Recognition
Jan 31, 2025



Self-supervised learning (SSL) is used in deep learning to train on large datasets without the need for expensive labelling of the data. Recently, large Automatic Speech Recognition (ASR) models such as XLS-R have utilised SSL to train on over one hundred different languages simultaneously. However, deeper investigation shows that the bulk of the training data for XLS-R comes from a small number of languages. Biases learned through SSL have been shown to exist in multiple domains, but language bias in multilingual SSL ASR has not been thoroughly examined. In this paper, we utilise the Lottery Ticket Hypothesis (LTH) to identify language-specific subnetworks within XLS-R and test the performance of these subnetworks on a variety of different languages. We are able to show that when fine-tuning, XLS-R bypasses traditional linguistic knowledge and builds only on weights learned from the languages with the largest data contribution to the pretraining data.
Uncovering the Visual Contribution in Audio-Visual Speech Recognition
Dec 22, 2024



Audio-Visual Speech Recognition (AVSR) combines auditory and visual speech cues to enhance the accuracy and robustness of speech recognition systems. Recent advancements in AVSR have improved performance in noisy environments compared to audio-only counterparts. However, the true extent of the visual contribution, and whether AVSR systems fully exploit the available cues in the visual domain, remains unclear. This paper assesses AVSR systems from a different perspective, by considering human speech perception. We use three systems: Auto-AVSR, AVEC and AV-RelScore. We first quantify the visual contribution using effective SNR gains at 0 dB and then investigate the use of visual information in terms of its temporal distribution and word-level informativeness. We show that low WER does not guarantee high SNR gains. Our results suggest that current methods do not fully exploit visual information, and we recommend future research to report effective SNR gains alongside WERs.
Noise-Robust Hearing Aid Voice Control
Nov 05, 2024



Advancing the design of robust hearing aid (HA) voice control is crucial to increase the HA use rate among hard of hearing people as well as to improve HA users' experience. In this work, we contribute towards this goal by, first, presenting a novel HA speech dataset consisting of noisy own voice captured by 2 behind-the-ear (BTE) and 1 in-ear-canal (IEC) microphones. Second, we provide baseline HA voice control results from the evaluation of light, state-of-the-art keyword spotting models utilizing different combinations of HA microphone signals. Experimental results show the benefits of exploiting bandwidth-limited bone-conducted speech (BCS) from the IEC microphone to achieve noise-robust HA voice control. Furthermore, results also demonstrate that voice control performance can be boosted by assisting BCS by the broader-bandwidth BTE microphone signals. Aiming at setting a baseline upon which the scientific community can continue to progress, the HA noisy speech dataset has been made publicly available.
Learnable Frontends that do not Learn: Quantifying Sensitivity to Filterbank Initialisation
Feb 20, 2023



While much of modern speech and audio processing relies on deep neural networks trained using fixed audio representations, recent studies suggest great potential in acoustic frontends learnt jointly with a backend. In this study, we focus specifically on learnable filterbanks. Prior studies have reported that in frontends using learnable filterbanks initialised to a mel scale, the learned filters do not differ substantially from their initialisation. Using a Gabor-based filterbank, we investigate the sensitivity of a learnable filterbank to its initialisation using several initialisation strategies on two audio tasks: voice activity detection and bird species identification. We use the Jensen-Shannon Distance and analysis of the learned filters before and after training. We show that although performance is overall improved, the filterbanks exhibit strong sensitivity to their initialisation strategy. The limited movement from initialised values suggests that alternate optimisation strategies may allow a learnable frontend to reach better overall performance.
Learnable Acoustic Frontends in Bird Activity Detection
Oct 03, 2022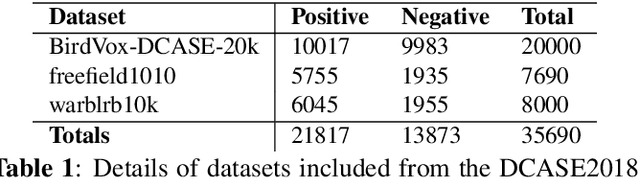
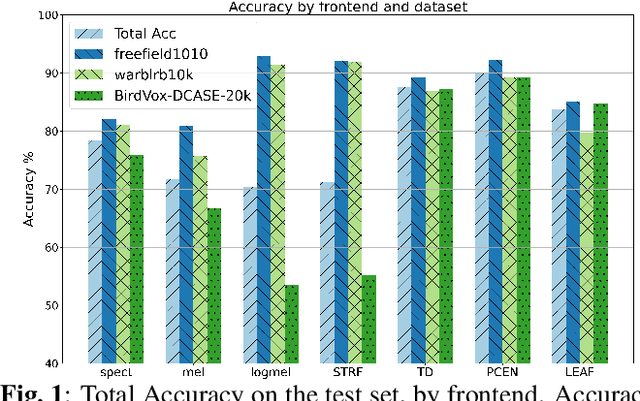
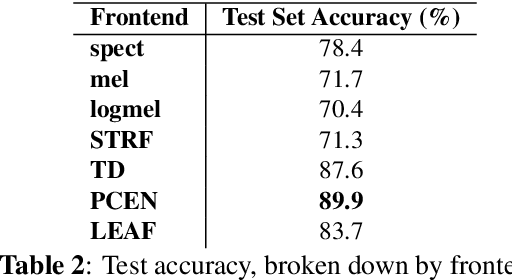

Autonomous recording units and passive acoustic monitoring present minimally intrusive methods of collecting bioacoustics data. Combining this data with species agnostic bird activity detection systems enables the monitoring of activity levels of bird populations. Unfortunately, variability in ambient noise levels and subject distance contribute to difficulties in accurately detecting bird activity in recordings. The choice of acoustic frontend directly affects the impact these issues have on system performance. In this paper, we benchmark traditional fixed-parameter acoustic frontends against the new generation of learnable frontends on a wide-ranging bird audio detection task using data from the DCASE2018 BAD Challenge. We observe that Per-Channel Energy Normalization is the best overall performer, achieving an accuracy of 89.9%, and that in general learnable frontends significantly outperform traditional methods. We also identify challenges in learning filterbanks for bird audio.