 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Center Audio/Video Intelligence on Device (DAVID) -- An Edge-AI Platform for Smart-Toys
Nov 18, 2023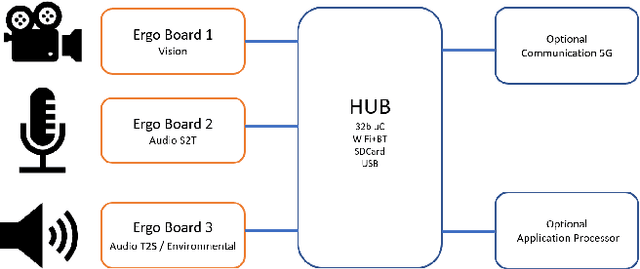
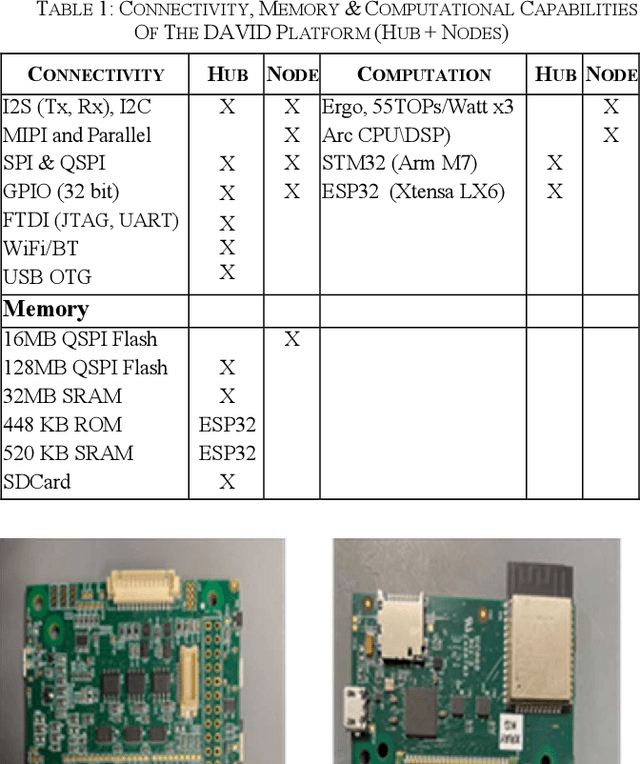

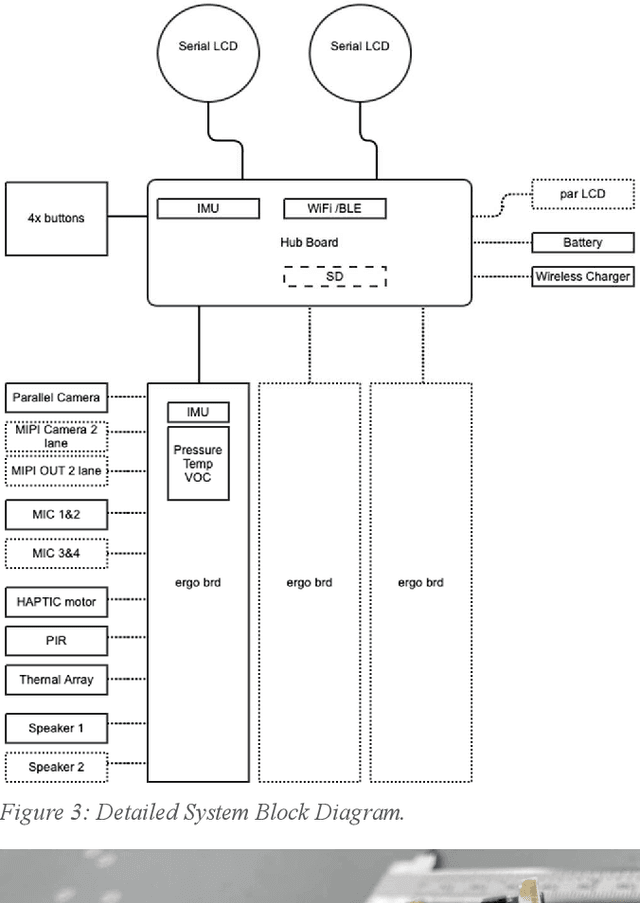
An overview is given of the DAVID Smart-Toy platform, one of the first Edge AI platform designs to incorporate advanced low-power data processing by neural inference models co-located with the relevant image or audio sensors. There is also on-board capability for in-device text-to-speech generation. Two alternative embodiments are presented: a smart Teddy-bear, and a roving dog-like robot. The platform offers a speech-driven user interface and can observe and interpret user actions and facial expressions via its computer vision sensor node. A particular benefit of this design is that no personally identifiable information passes beyond the neural inference nodes thus providing inbuilt compliance with data protection regulations.
AV Taris: Online Audio-Visual Speech Recognition
Dec 14, 2020


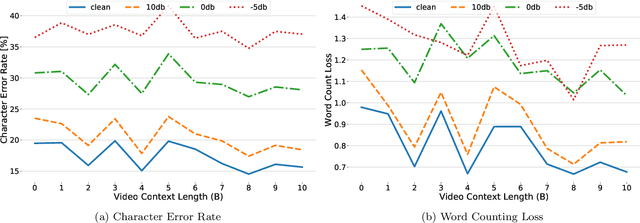
In recent years, Automatic Speech Recognition (ASR) technology has approached human-level performance on conversational speech under relatively clean listening conditions. In more demanding situations involving distant microphones, overlapped speech, background noise, or natural dialogue structures, the ASR error rate is at least an order of magnitude higher. The visual modality of speech carries the potential to partially overcome these challenges and contribute to the sub-tasks of speaker diarisation, voice activity detection, and the recovery of the place of articulation, and can compensate for up to 15dB of noise on average. This article develops AV Taris, a fully differentiable neural network model capable of decoding audio-visual speech in real time. We achieve this by connecting two recently proposed models for audio-visual speech integration and online speech recognition, namely AV Align and Taris. We evaluate AV Taris under the same conditions as AV Align and Taris on one of the largest publicly available audio-visual speech datasets, LRS2. Our results show that AV Taris is superior to the audio-only variant of Taris, demonstrating the utility of the visual modality to speech recognition within the real time decoding framework defined by Taris. Compared to an equivalent Transformer-based AV Align model that takes advantage of full sentences without meeting the real-time requirement, we report an absolute degradation of approximately 3% with AV Taris. As opposed to the more popular alternative for online speech recognition, namely the RNN Transducer, Taris offers a greatly simplified fully differentiable training pipeline. As a consequence, AV Taris has the potential to popularise the adoption of Audio-Visual Speech Recognition (AVSR) technology and overcome the inherent limitations of the audio modality in less optimal listening conditions.
Learning to Count Words in Fluent Speech enables Online Speech Recognition
Jun 11, 2020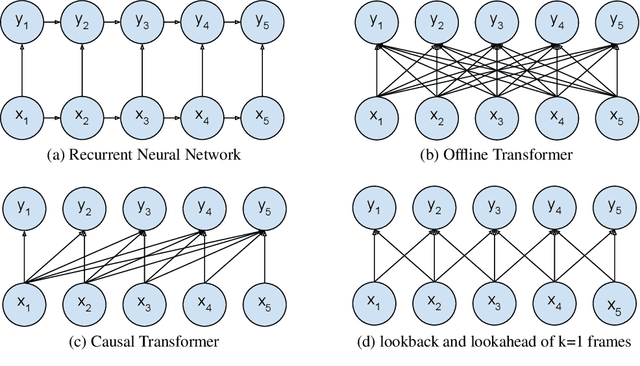


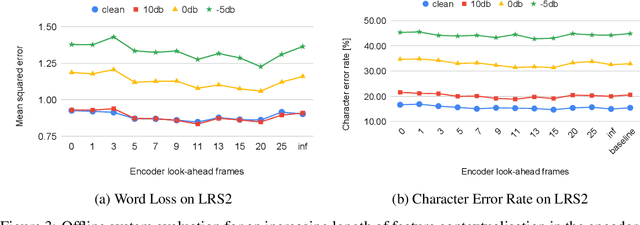
Sequence to Sequence models, in particular the Transformer, achieve state of the art results in Automatic Speech Recognition. Practical usage is however limited to cases where full utterance latency is acceptable. In this work we introduce Taris, a Transformer-based online speech recognition system aided by an auxiliary task of incremental word counting. We use the cumulative word sum to dynamically segment speech and enable its eager decoding into words. Experiments performed on the LRS2 and LibriSpeech datasets, of unconstrained and read speech respectively, show that the online system performs on a par with the offline one, while having a dynamic algorithmic delay of 5 segments. Furthermore, we show that the estimated segment length distribution resembles the word length distribution obtained with forced alignment, although our system does not require an exact segment-to-word equivalence. Taris introduces a negligible overhead compared to a standard Transformer, while the local relationship modelling between inputs and outputs grants invariance to sequence length by design.
Should we hard-code the recurrence concept or learn it instead ? Exploring the Transformer architecture for Audio-Visual Speech Recognition
May 19, 2020


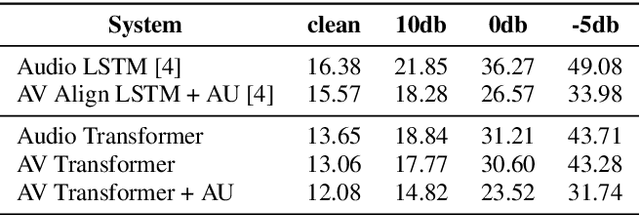
The audio-visual speech fusion strategy AV Align has shown significant performance improvements in audio-visual speech recognition (AVSR) on the challenging LRS2 dataset. Performance improvements range between 7% and 30% depending on the noise level when leveraging the visual modality of speech in addition to the auditory one. This work presents a variant of AV Align where the recurrent Long Short-term Memory (LSTM) computation block is replaced by the more recently proposed Transformer block. We compare the two methods, discussing in greater detail their strengths and weaknesses. We find that Transformers also learn cross-modal monotonic alignments, but suffer from the same visual convergence problems as the LSTM model, calling for a deeper investigation into the dominant modality problem in machine learning.
How to Teach DNNs to Pay Attention to the Visual Modality in Speech Recognition
Apr 17, 2020



Audio-Visual Speech Recognition (AVSR) seeks to model, and thereby exploit, the dynamic relationship between a human voice and the corresponding mouth movements. A recently proposed multimodal fusion strategy, AV Align, based on state-of-the-art sequence to sequence neural networks, attempts to model this relationship by explicitly aligning the acoustic and visual representations of speech. This study investigates the inner workings of AV Align and visualises the audio-visual alignment patterns. Our experiments are performed on two of the largest publicly available AVSR datasets, TCD-TIMIT and LRS2. We find that AV Align learns to align acoustic and visual representations of speech at the frame level on TCD-TIMIT in a generally monotonic pattern. We also determine the cause of initially seeing no improvement over audio-only speech recognition on the more challenging LRS2. We propose a regularisation method which involves predicting lip-related Action Units from visual representations. Our regularisation method leads to better exploitation of the visual modality, with performance improvements between 7% and 30% depending on the noise level. Furthermore, we show that the alternative Watch, Listen, Attend, and Spell network is affected by the same problem as AV Align, and that our proposed approach can effectively help it learn visual representations. Our findings validate the suitability of the regularisation method to AVSR and encourage researchers to rethink the multimodal convergence problem when having one dominant modality.
Attention-based Audio-Visual Fusion for Robust Automatic Speech Recognition
Sep 05, 2018


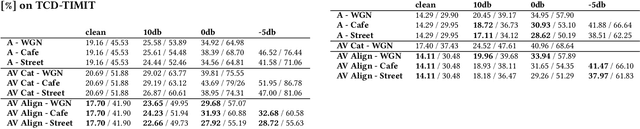
Automatic speech recognition can potentially benefit from the lip motion patterns, complementing acoustic speech to improve the overall recognition performance, particularly in noise. In this paper we propose an audio-visual fusion strategy that goes beyond simple feature concatenation and learns to automatically align the two modalities, leading to enhanced representations which increase the recognition accuracy in both clean and noisy conditions. We test our strategy on the TCD-TIMIT and LRS2 datasets, designed for large vocabulary continuous speech recognition, applying three types of noise at different power ratios. We also exploit state of the art Sequence-to-Sequence architectures, showing that our method can be easily integrated. Results show relative improvements from 7% up to 30% on TCD-TIMIT over the acoustic modality alone, depending on the acoustic noise level. We anticipate that the fusion strategy can easily generalise to many other multimodal tasks which involve correlated modalities.
Can DNNs Learn to Lipread Full Sentences?
May 29, 2018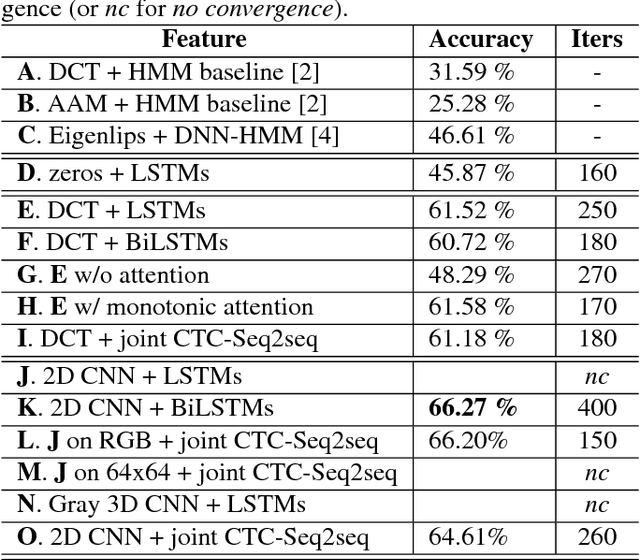
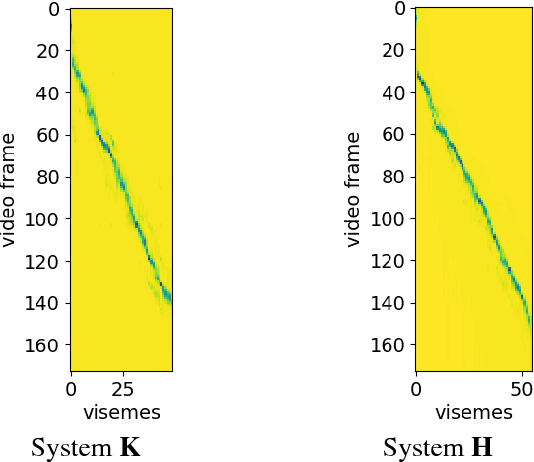

Finding visual features and suitable models for lipreading tasks that are more complex than a well-constrained vocabulary has proven challenging. This paper explores state-of-the-art Deep Neural Network architectures for lipreading based on a Sequence to Sequence Recurrent Neural Network. We report results for both hand-crafted and 2D/3D Convolutional Neural Network visual front-ends, online monotonic attention, and a joint Connectionist Temporal Classification-Sequence-to-Sequence loss. The system is evaluated on the publicly available TCD-TIMIT dataset, with 59 speakers and a vocabulary of over 6000 words. Results show a major improvement on a Hidden Markov Model framework. A fuller analysis of performance across visemes demonstrates that the network is not only learning the language model, but actually learning to lipread.