 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing True Generalisability of Audio-Visual Speech Recognisers
Jun 05, 2026Current Audio-Visual Speech Recognition (AVSR) models achieve near-perfect performance on the standard LRS3 benchmark, raising concerns of adaptive overfitting. To systematically assess true generalisability, we construct a highly controlled, unseen evaluation set subsampled from the massive MultiVSR dataset. Unlike standard out-of-distribution benchmarks, our subset strictly matches the acoustic, visual, and demographic distributions of the LRS3 test set. Evaluating five state-of-the-art architectures reveals a universal performance collapse, proving that current systems fail to generalise even under strictly aligned conditions. Through a fine-grained attribute analysis across seven factors, we isolate the specific drivers of this degradation. Furthermore, we uncover a profound lexical bias, expose distinct error patterns, and surprisingly reveal that audio-visual performance even lags behind audio-only settings. We release our matched test set for future benchmarking.
Uncovering the Visual Contribution in Audio-Visual Speech Recognition
Dec 22, 2024



Audio-Visual Speech Recognition (AVSR) combines auditory and visual speech cues to enhance the accuracy and robustness of speech recognition systems. Recent advancements in AVSR have improved performance in noisy environments compared to audio-only counterparts. However, the true extent of the visual contribution, and whether AVSR systems fully exploit the available cues in the visual domain, remains unclear. This paper assesses AVSR systems from a different perspective, by considering human speech perception. We use three systems: Auto-AVSR, AVEC and AV-RelScore. We first quantify the visual contribution using effective SNR gains at 0 dB and then investigate the use of visual information in terms of its temporal distribution and word-level informativeness. We show that low WER does not guarantee high SNR gains. Our results suggest that current methods do not fully exploit visual information, and we recommend future research to report effective SNR gains alongside WERs.
Improving Whispered Speech Recognition Performance using Pseudo-whispered based Data Augmentation
Nov 09, 2023
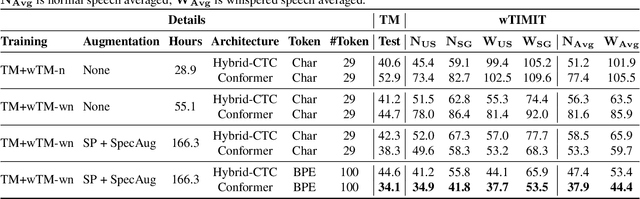

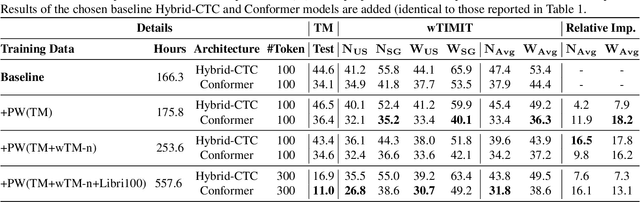
Whispering is a distinct form of speech known for its soft, breathy, and hushed characteristics, often used for private communication. The acoustic characteristics of whispered speech differ substantially from normally phonated speech and the scarcity of adequate training data leads to low automatic speech recognition (ASR) performance. To address the data scarcity issue, we use a signal processing-based technique that transforms the spectral characteristics of normal speech to those of pseudo-whispered speech. We augment an End-to-End ASR with pseudo-whispered speech and achieve an 18.2% relative reduction in word error rate for whispered speech compared to the baseline. Results for the individual speaker groups in the wTIMIT database show the best results for US English. Further investigation showed that the lack of glottal information in whispered speech has the largest impact on whispered speech ASR performance.