 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective and Subjective Evaluation of Diffusion-Based Speech Enhancement for Dysarthric Speech
Aug 25, 2025Dysarthric speech poses significant challenges for automatic speech recognition (ASR) systems due to its high variability and reduced intelligibility. In this work we explore the use of diffusion models for dysarthric speech enhancement, which is based on the hypothesis that using diffusion-based speech enhancement moves the distribution of dysarthric speech closer to that of typical speech, which could potentially improve dysarthric speech recognition performance. We assess the effect of two diffusion-based and one signal-processing-based speech enhancement algorithms on intelligibility and speech quality of two English dysarthric speech corpora. We applied speech enhancement to both typical and dysarthric speech and evaluate the ASR performance using Whisper-Turbo, and the subjective and objective speech quality of the original and enhanced dysarthric speech. We also fine-tuned Whisper-Turbo on the enhanced speech to assess its impact on recognition performance.
As Biased as You Measure: Methodological Pitfalls of Bias Evaluations in Speaker Verification Research
Aug 24, 2024
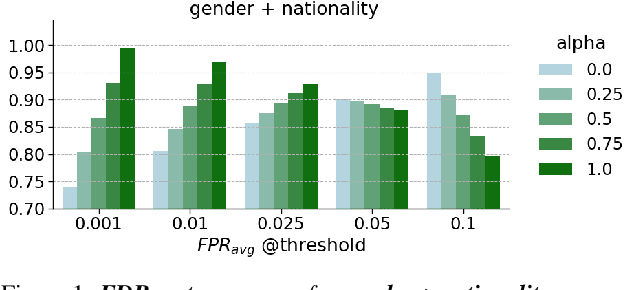
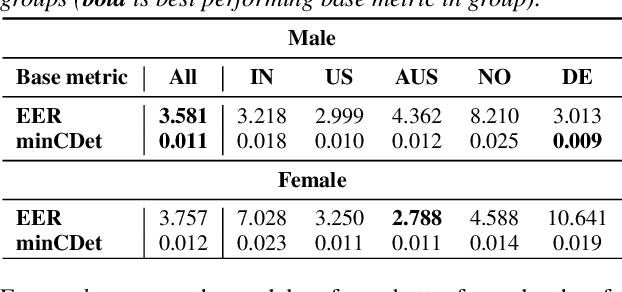
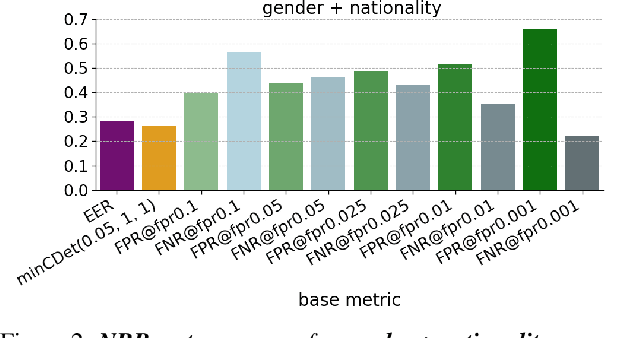
Detecting and mitigating bias in speaker verification systems is important, as datasets, processing choices and algorithms can lead to performance differences that systematically favour some groups of people while disadvantaging others. Prior studies have thus measured performance differences across groups to evaluate bias. However, when comparing results across studies, it becomes apparent that they draw contradictory conclusions, hindering progress in this area. In this paper we investigate how measurement impacts the outcomes of bias evaluations. We show empirically that bias evaluations are strongly influenced by base metrics that measure performance, by the choice of ratio or difference-based bias measure, and by the aggregation of bias measures into meta-measures. Based on our findings, we recommend the use of ratio-based bias measures, in particular when the values of base metrics are small, or when base metrics with different orders of magnitude need to be compared.
Improving child speech recognition with augmented child-like speech
Jun 12, 2024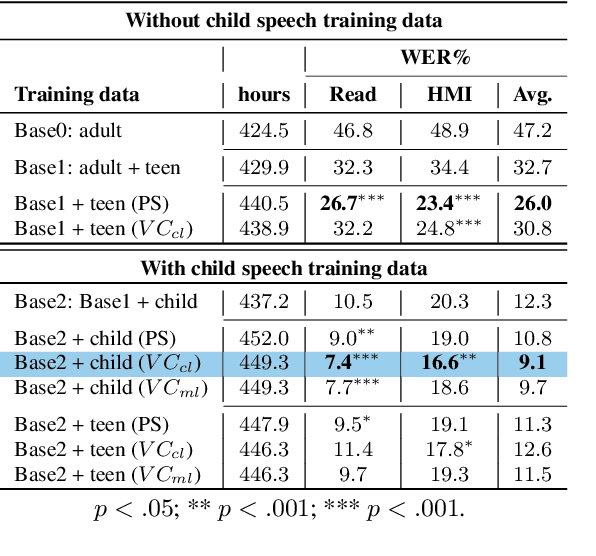
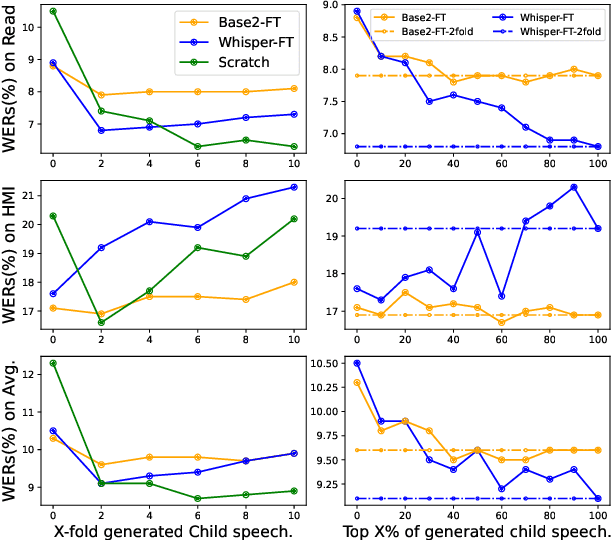
State-of-the-art ASRs show suboptimal performance for child speech. The scarcity of child speech limits the development of child speech recognition (CSR). Therefore, we studied child-to-child voice conversion (VC) from existing child speakers in the dataset and additional (new) child speakers via monolingual and cross-lingual (Dutch-to-German) VC, respectively. The results showed that cross-lingual child-to-child VC significantly improved child ASR performance. Experiments on the impact of the quantity of child-to-child cross-lingual VC-generated data on fine-tuning (FT) ASR models gave the best results with two-fold augmentation for our FT-Conformer model and FT-Whisper model which reduced WERs with ~3% absolute compared to the baseline, and with six-fold augmentation for the model trained from scratch, which improved by an absolute 3.6% WER. Moreover, using a small amount of "high-quality" VC-generated data achieved similar results to those of our best-FT models.
Exploring data augmentation in bias mitigation against non-native-accented speech
Dec 24, 2023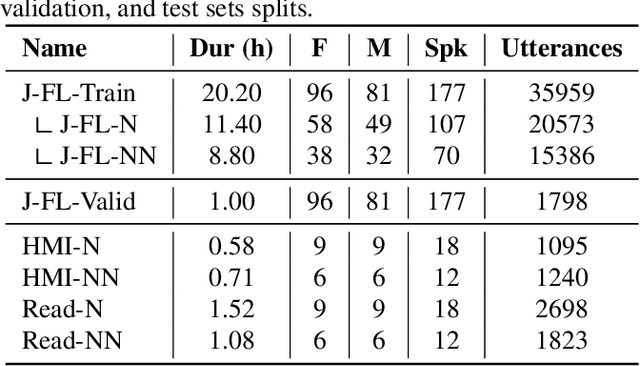
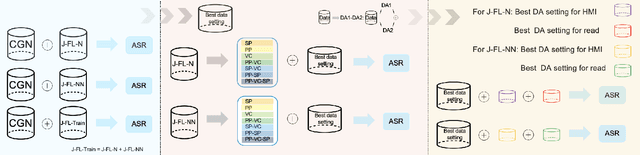
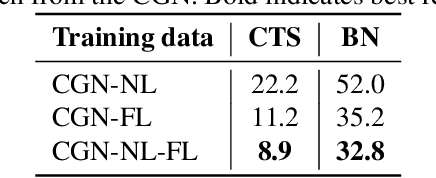
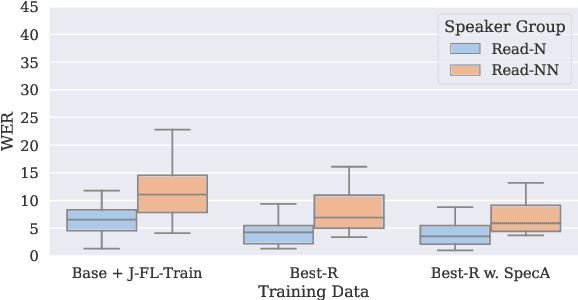
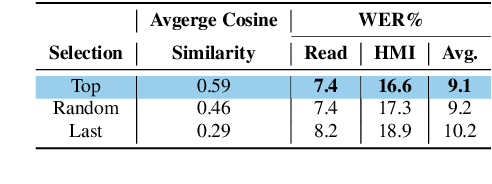
Automatic speech recognition (ASR) should serve every speaker, not only the majority ``standard'' speakers of a language. In order to build inclusive ASR, mitigating the bias against speaker groups who speak in a ``non-standard'' or ``diverse'' way is crucial. We aim to mitigate the bias against non-native-accented Flemish in a Flemish ASR system. Since this is a low-resource problem, we investigate the optimal type of data augmentation, i.e., speed/pitch perturbation, cross-lingual voice conversion-based methods, and SpecAugment, applied to both native Flemish and non-native-accented Flemish, for bias mitigation. The results showed that specific types of data augmentation applied to both native and non-native-accented speech improve non-native-accented ASR while applying data augmentation to the non-native-accented speech is more conducive to bias reduction. Combining both gave the largest bias reduction for human-machine interaction (HMI) as well as read-type speech.
Improving Whispered Speech Recognition Performance using Pseudo-whispered based Data Augmentation
Nov 09, 2023
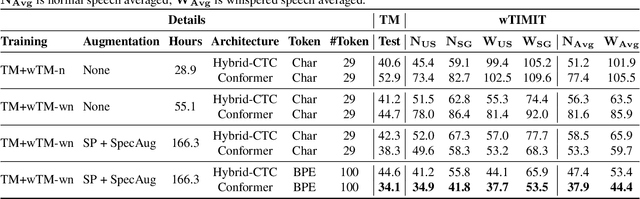

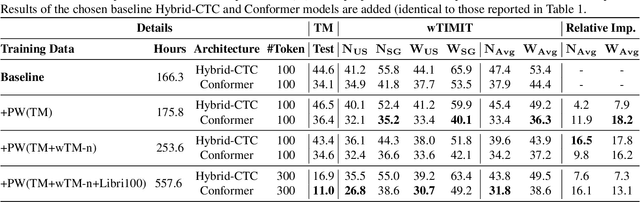
Whispering is a distinct form of speech known for its soft, breathy, and hushed characteristics, often used for private communication. The acoustic characteristics of whispered speech differ substantially from normally phonated speech and the scarcity of adequate training data leads to low automatic speech recognition (ASR) performance. To address the data scarcity issue, we use a signal processing-based technique that transforms the spectral characteristics of normal speech to those of pseudo-whispered speech. We augment an End-to-End ASR with pseudo-whispered speech and achieve an 18.2% relative reduction in word error rate for whispered speech compared to the baseline. Results for the individual speaker groups in the wTIMIT database show the best results for US English. Further investigation showed that the lack of glottal information in whispered speech has the largest impact on whispered speech ASR performance.
Using Data Augmentations and VTLN to Reduce Bias in Dutch End-to-End Speech Recognition Systems
Jul 05, 2023Speech technology has improved greatly for norm speakers, i.e., adult native speakers of a language without speech impediments or strong accents. However, non-norm or diverse speaker groups show a distinct performance gap with norm speakers, which we refer to as bias. In this work, we aim to reduce bias against different age groups and non-native speakers of Dutch. For an end-to-end (E2E) ASR system, we use state-of-the-art speed perturbation and spectral augmentation as data augmentation techniques and explore Vocal Tract Length Normalization (VTLN) to normalise for spectral differences due to differences in anatomy. The combination of data augmentation and VTLN reduced the average WER and bias across various diverse speaker groups by 6.9% and 3.9%, respectively. The VTLN model trained on Dutch was also effective in improving performance of Mandarin Chinese child speech, thus, showing generalisability across languages
Predicting within and across language phoneme recognition performance of self-supervised learning speech pre-trained models
Jun 24, 2022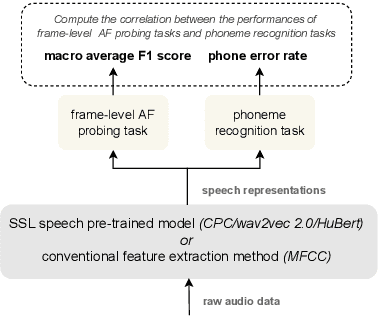
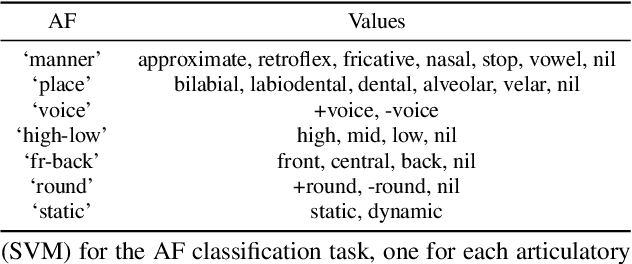
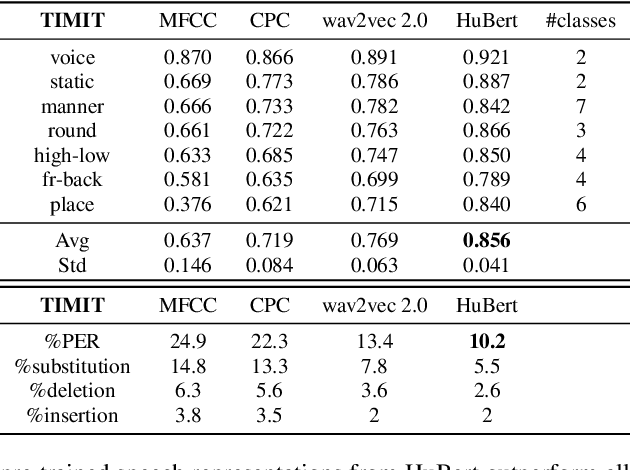
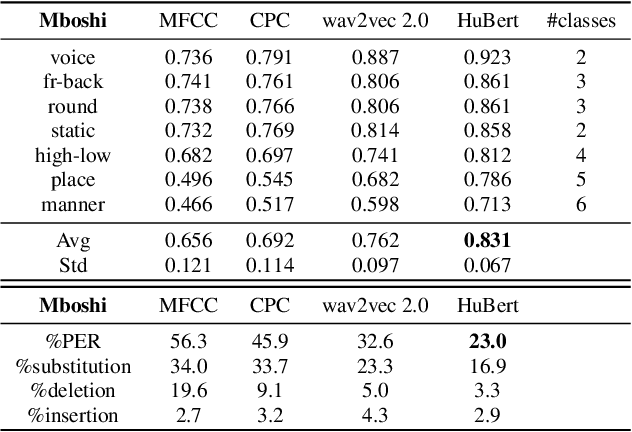
In this work, we analyzed and compared speech representations extracted from different frozen self-supervised learning (SSL) speech pre-trained models on their ability to capture articulatory features (AF) information and their subsequent prediction of phone recognition performance for within and across language scenarios. Specifically, we compared CPC, wav2vec 2.0, and HuBert. First, frame-level AF probing tasks were implemented. Subsequently, phone-level end-to-end ASR systems for phoneme recognition tasks were implemented, and the performance on the frame-level AF probing task and the phone accuracy were correlated. Compared to the conventional speech representation MFCC, all SSL pre-trained speech representations captured more AF information, and achieved better phoneme recognition performance within and across languages, with HuBert performing best. The frame-level AF probing task is a good predictor of phoneme recognition performance, showing the importance of capturing AF information in the speech representations. Compared with MFCC, in the within-language scenario, the performance of these SSL speech pre-trained models on AF probing tasks achieved a maximum relative increase of 34.4%, and it resulted in the lowest PER of 10.2%. In the cross-language scenario, the maximum relative increase of 26.7% also resulted in the lowest PER of 23.0%.