 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring data augmentation in bias mitigation against non-native-accented speech
Paper and Code
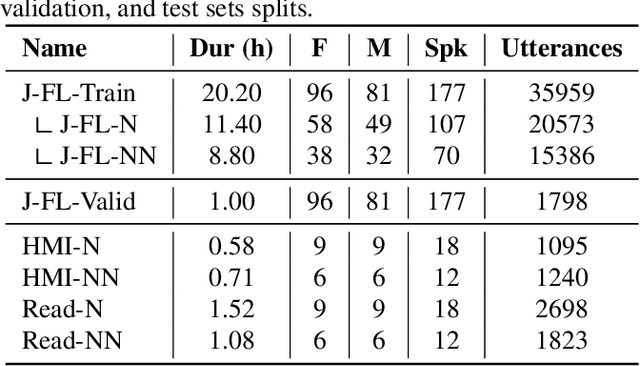
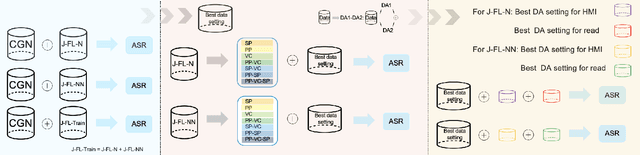
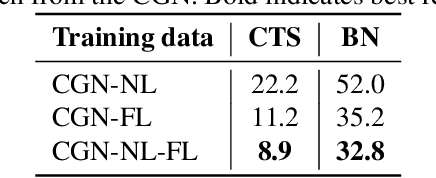
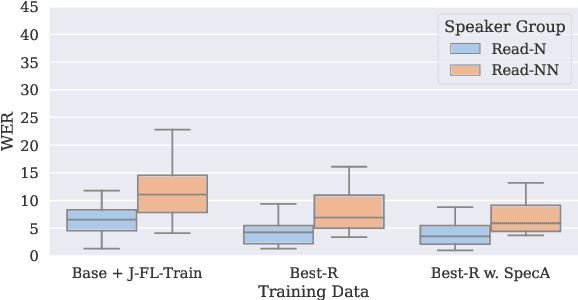
Automatic speech recognition (ASR) should serve every speaker, not only the majority ``standard'' speakers of a language. In order to build inclusive ASR, mitigating the bias against speaker groups who speak in a ``non-standard'' or ``diverse'' way is crucial. We aim to mitigate the bias against non-native-accented Flemish in a Flemish ASR system. Since this is a low-resource problem, we investigate the optimal type of data augmentation, i.e., speed/pitch perturbation, cross-lingual voice conversion-based methods, and SpecAugment, applied to both native Flemish and non-native-accented Flemish, for bias mitigation. The results showed that specific types of data augmentation applied to both native and non-native-accented speech improve non-native-accented ASR while applying data augmentation to the non-native-accented speech is more conducive to bias reduction. Combining both gave the largest bias reduction for human-machine interaction (HMI) as well as read-type speech.