 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring data augmentation in bias mitigation against non-native-accented speech
Dec 24, 2023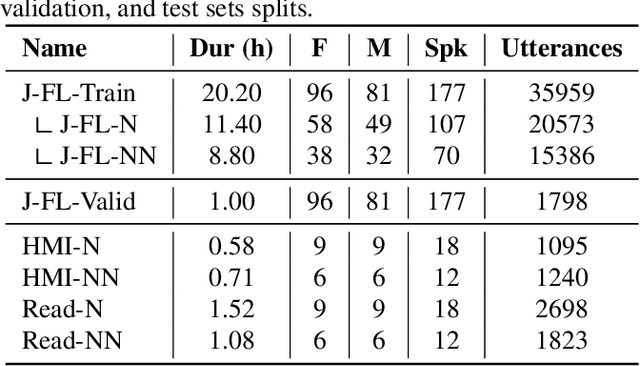
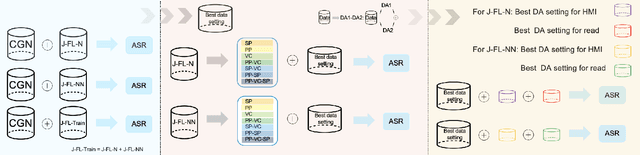
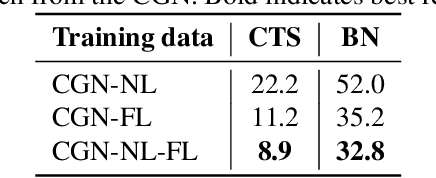
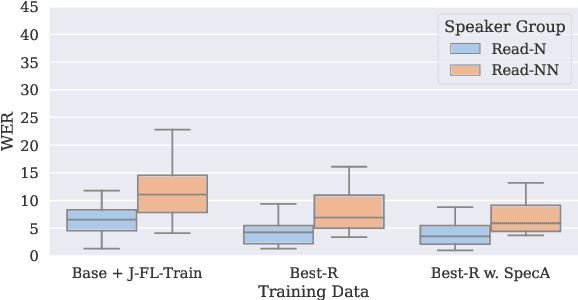
Automatic speech recognition (ASR) should serve every speaker, not only the majority ``standard'' speakers of a language. In order to build inclusive ASR, mitigating the bias against speaker groups who speak in a ``non-standard'' or ``diverse'' way is crucial. We aim to mitigate the bias against non-native-accented Flemish in a Flemish ASR system. Since this is a low-resource problem, we investigate the optimal type of data augmentation, i.e., speed/pitch perturbation, cross-lingual voice conversion-based methods, and SpecAugment, applied to both native Flemish and non-native-accented Flemish, for bias mitigation. The results showed that specific types of data augmentation applied to both native and non-native-accented speech improve non-native-accented ASR while applying data augmentation to the non-native-accented speech is more conducive to bias reduction. Combining both gave the largest bias reduction for human-machine interaction (HMI) as well as read-type speech.
Measuring Sentiment Bias in Machine Translation
Jun 12, 2023

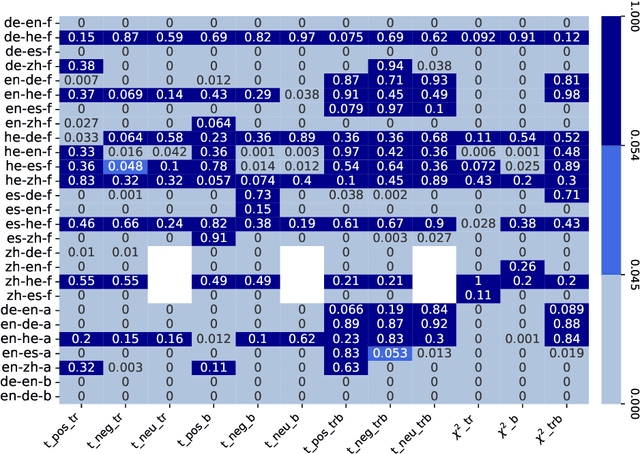

Biases induced to text by generative models have become an increasingly large topic in recent years. In this paper we explore how machine translation might introduce a bias in sentiments as classified by sentiment analysis models. For this, we compare three open access machine translation models for five different languages on two parallel corpora to test if the translation process causes a shift in sentiment classes recognized in the texts. Though our statistic test indicate shifts in the label probability distributions, we find none that appears consistent enough to assume a bias induced by the translation process.
Allophant: Cross-lingual Phoneme Recognition with Articulatory Attributes
Jun 07, 2023



This paper proposes Allophant, a multilingual phoneme recognizer. It requires only a phoneme inventory for cross-lingual transfer to a target language, allowing for low-resource recognition. The architecture combines a compositional phone embedding approach with individually supervised phonetic attribute classifiers in a multi-task architecture. We also introduce Allophoible, an extension of the PHOIBLE database. When combined with a distance based mapping approach for grapheme-to-phoneme outputs, it allows us to train on PHOIBLE inventories directly. By training and evaluating on 34 languages, we found that the addition of multi-task learning improves the model's capability of being applied to unseen phonemes and phoneme inventories. On supervised languages we achieve phoneme error rate improvements of 11 percentage points (pp.) compared to a baseline without multi-task learning. Evaluation of zero-shot transfer on 84 languages yielded a decrease in PER of 2.63 pp. over the baseline.