 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Engine and the Performance of Different LLM Models in a SLURM based HPC architecture
Aug 25, 2025This work elaborates on a High performance computing (HPC) architecture based on Simple Linux Utility for Resource Management (SLURM) [1] for deploying heterogeneous Large Language Models (LLMs) into a scalable inference engine. Dynamic resource scheduling and seamless integration of containerized microservices have been leveraged herein to manage CPU, GPU, and memory allocations efficiently in multi-node clusters. Extensive experiments, using Llama 3.2 (1B and 3B parameters) [2] and Llama 3.1 (8B and 70B) [3], probe throughput, latency, and concurrency and show that small models can handle up to 128 concurrent requests at sub-50 ms latency, while for larger models, saturation happens with as few as two concurrent users, with a latency of more than 2 seconds. This architecture includes Representational State Transfer Application Programming Interfaces (REST APIs) [4] endpoints for single and bulk inferences, as well as advanced workflows such as multi-step "tribunal" refinement. Experimental results confirm minimal overhead from container and scheduling activities and show that the approach scales reliably both for batch and interactive settings. We further illustrate real-world scenarios, including the deployment of chatbots with retrievalaugmented generation, which helps to demonstrate the flexibility and robustness of the architecture. The obtained results pave ways for significantly more efficient, responsive, and fault-tolerant LLM inference on large-scale HPC infrastructures.
Analysis of Knowledge Tracing performance on synthesised student data
Jan 30, 2024



Knowledge Tracing (KT) aims to predict the future performance of students by tracking the development of their knowledge states. Despite all the recent progress made in this field, the application of KT models in education systems is still restricted from the data perspectives: 1) limited access to real life data due to data protection concerns, 2) lack of diversity in public datasets, 3) noises in benchmark datasets such as duplicate records. To resolve these problems, we simulated student data with three statistical strategies based on public datasets and tested their performance on two KT baselines. While we observe only minor performance improvement with additional synthetic data, our work shows that using only synthetic data for training can lead to similar performance as real data.
Compression of end-to-end non-autoregressive image-to-speech system for low-resourced devices
Nov 30, 2023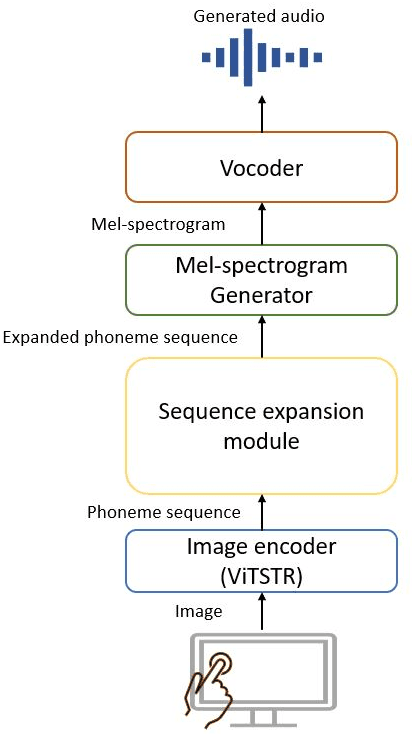

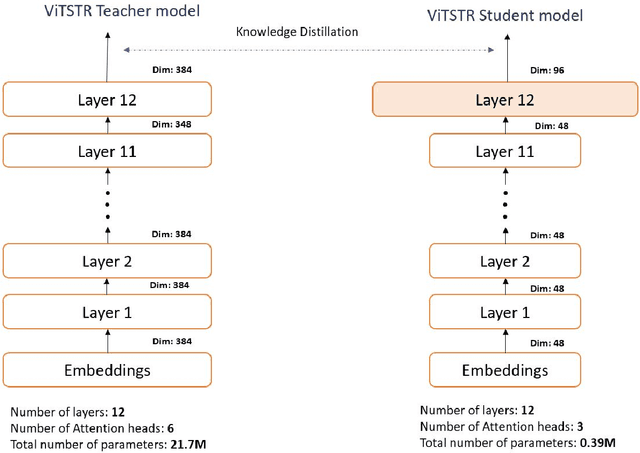
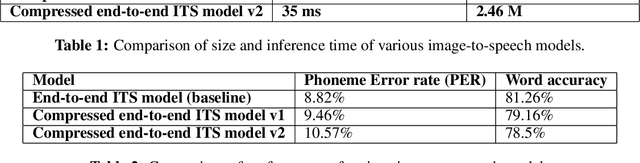
People with visual impairments have difficulty accessing touchscreen-enabled personal computing devices like mobile phones and laptops. The image-to-speech (ITS) systems can assist them in mitigating this problem, but their huge model size makes it extremely hard to be deployed on low-resourced embedded devices. In this paper, we aim to overcome this challenge by developing an efficient endto-end neural architecture for generating audio from tiny segments of display content on low-resource devices. We introduced a vision transformers-based image encoder and utilized knowledge distillation to compress the model from 6.1 million to 2.46 million parameters. Human and automatic evaluation results show that our approach leads to a very minimal drop in performance and can speed up the inference time by 22%.
Measuring Sentiment Bias in Machine Translation
Jun 12, 2023

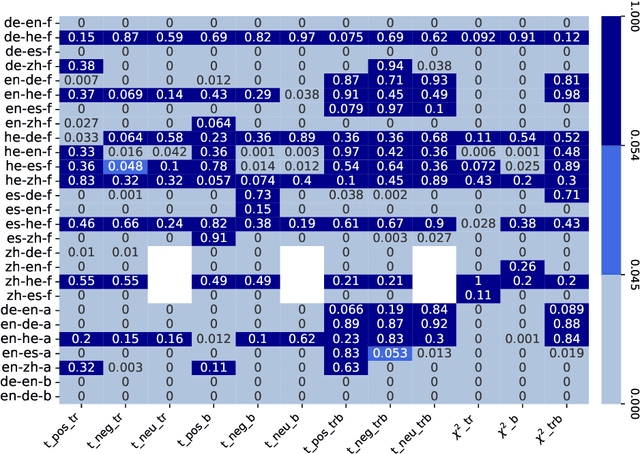

Biases induced to text by generative models have become an increasingly large topic in recent years. In this paper we explore how machine translation might introduce a bias in sentiments as classified by sentiment analysis models. For this, we compare three open access machine translation models for five different languages on two parallel corpora to test if the translation process causes a shift in sentiment classes recognized in the texts. Though our statistic test indicate shifts in the label probability distributions, we find none that appears consistent enough to assume a bias induced by the translation process.
Allophant: Cross-lingual Phoneme Recognition with Articulatory Attributes
Jun 07, 2023



This paper proposes Allophant, a multilingual phoneme recognizer. It requires only a phoneme inventory for cross-lingual transfer to a target language, allowing for low-resource recognition. The architecture combines a compositional phone embedding approach with individually supervised phonetic attribute classifiers in a multi-task architecture. We also introduce Allophoible, an extension of the PHOIBLE database. When combined with a distance based mapping approach for grapheme-to-phoneme outputs, it allows us to train on PHOIBLE inventories directly. By training and evaluating on 34 languages, we found that the addition of multi-task learning improves the model's capability of being applied to unseen phonemes and phoneme inventories. On supervised languages we achieve phoneme error rate improvements of 11 percentage points (pp.) compared to a baseline without multi-task learning. Evaluation of zero-shot transfer on 84 languages yielded a decrease in PER of 2.63 pp. over the baseline.
An End-to-End Neural Network for Image-to-Audio Transformation
Mar 10, 2023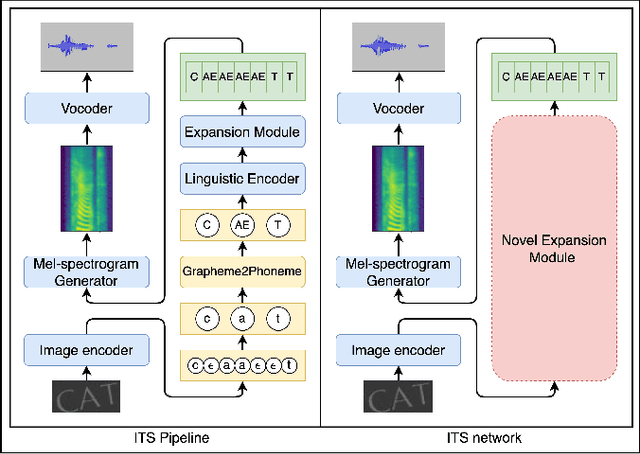
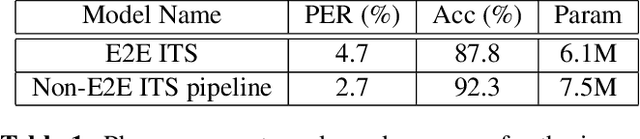
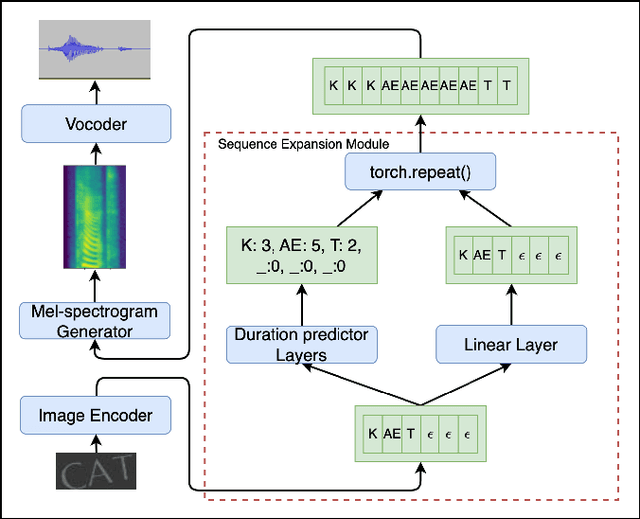
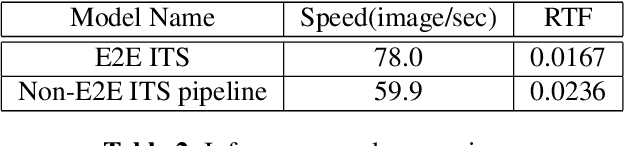
This paper describes an end-to-end (E2E) neural architecture for the audio rendering of small portions of display content on low resource personal computing devices. It is intended to address the problem of accessibility for vision-impaired or vision-distracted users at the hardware level. Neural image-to-text (ITT) and text-to-speech (TTS) approaches are reviewed and a new technique is introduced to efficiently integrate them in a way that is both efficient and back-propagate-able, leading to a non-autoregressive E2E image-to-speech (ITS) neural network that is efficient and trainable. Experimental results are presented showing that, compared with the non-E2E approach, the proposed E2E system is 29% faster and uses 19% fewer parameters with a 2% reduction in phone accuracy. A future direction to address accuracy is presented.
Compact Speaker Embedding: lrx-vector
Aug 11, 2020



Deep neural networks (DNN) have recently been widely used in speaker recognition systems, achieving state-of-the-art performance on various benchmarks. The x-vector architecture is especially popular in this research community, due to its excellent performance and manageable computational complexity. In this paper, we present the lrx-vector system, which is the low-rank factorized version of the x-vector embedding network. The primary objective of this topology is to further reduce the memory requirement of the speaker recognition system. We discuss the deployment of knowledge distillation for training the lrx-vector system and compare against low-rank factorization with SVD. On the VOiCES 2019 far-field corpus we were able to reduce the weights by 28% compared to the full-rank x-vector system while keeping the recognition rate constant (1.83% EER).
* Accepted to INTERSPEECH 2020