 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression of end-to-end non-autoregressive image-to-speech system for low-resourced devices
Nov 30, 2023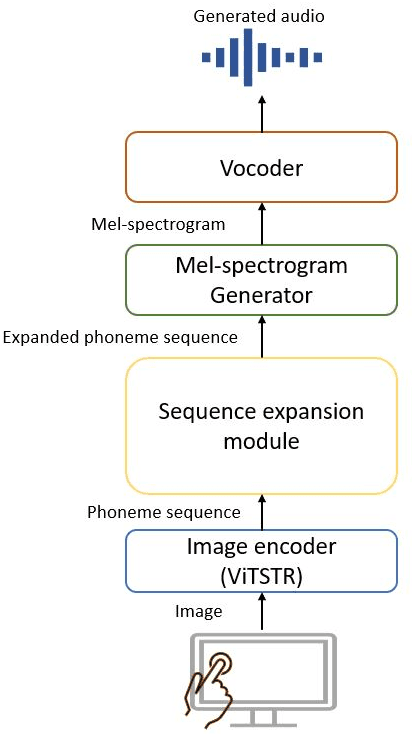

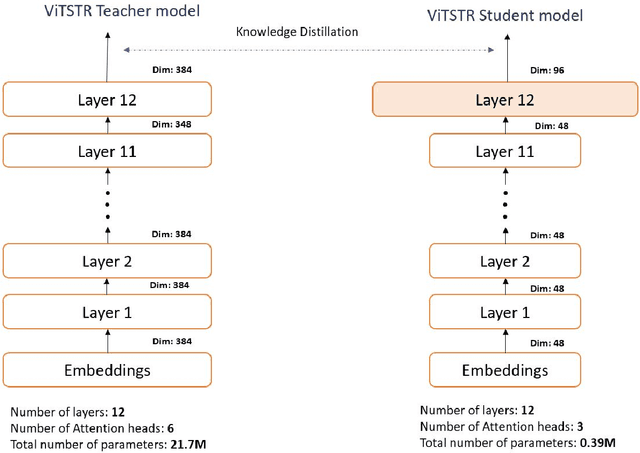
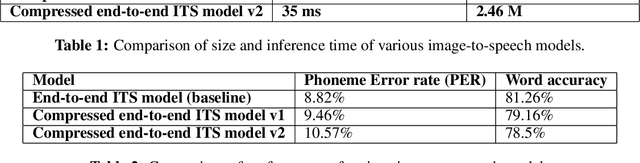
People with visual impairments have difficulty accessing touchscreen-enabled personal computing devices like mobile phones and laptops. The image-to-speech (ITS) systems can assist them in mitigating this problem, but their huge model size makes it extremely hard to be deployed on low-resourced embedded devices. In this paper, we aim to overcome this challenge by developing an efficient endto-end neural architecture for generating audio from tiny segments of display content on low-resource devices. We introduced a vision transformers-based image encoder and utilized knowledge distillation to compress the model from 6.1 million to 2.46 million parameters. Human and automatic evaluation results show that our approach leads to a very minimal drop in performance and can speed up the inference time by 22%.
An End-to-End Neural Network for Image-to-Audio Transformation
Mar 10, 2023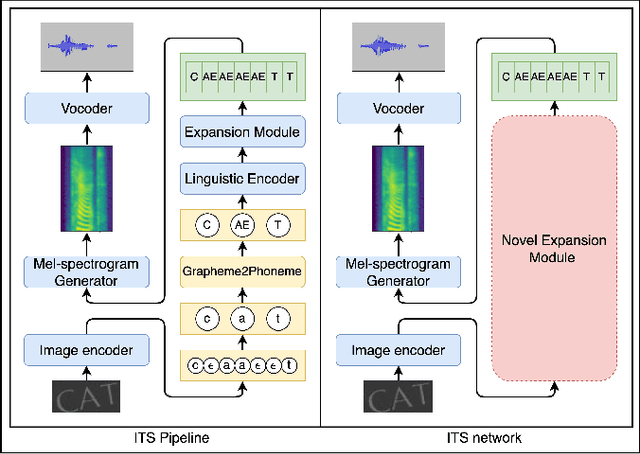
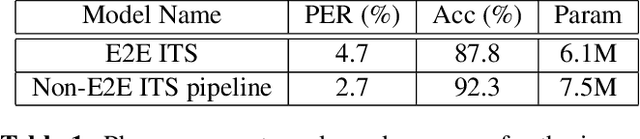
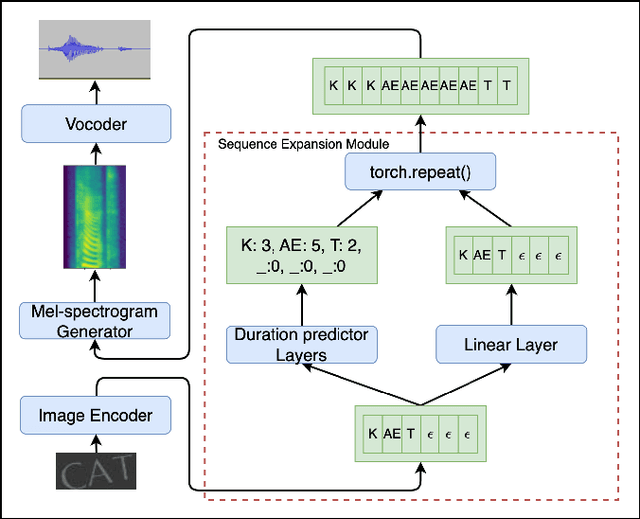
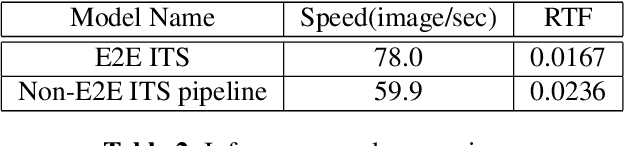
This paper describes an end-to-end (E2E) neural architecture for the audio rendering of small portions of display content on low resource personal computing devices. It is intended to address the problem of accessibility for vision-impaired or vision-distracted users at the hardware level. Neural image-to-text (ITT) and text-to-speech (TTS) approaches are reviewed and a new technique is introduced to efficiently integrate them in a way that is both efficient and back-propagate-able, leading to a non-autoregressive E2E image-to-speech (ITS) neural network that is efficient and trainable. Experimental results are presented showing that, compared with the non-E2E approach, the proposed E2E system is 29% faster and uses 19% fewer parameters with a 2% reduction in phone accuracy. A future direction to address accuracy is presented.
Structural sparsification for Far-field Speaker Recognition with GNA
Oct 25, 2019
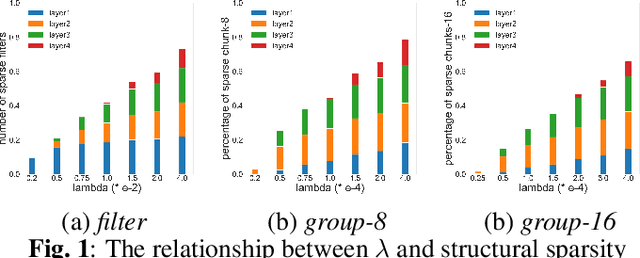
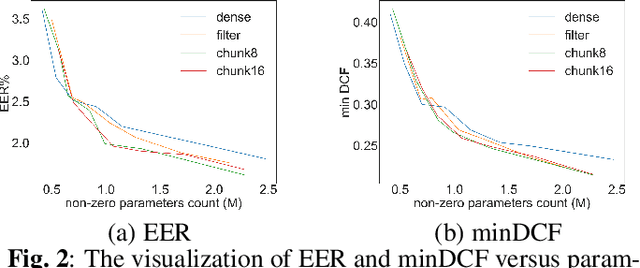
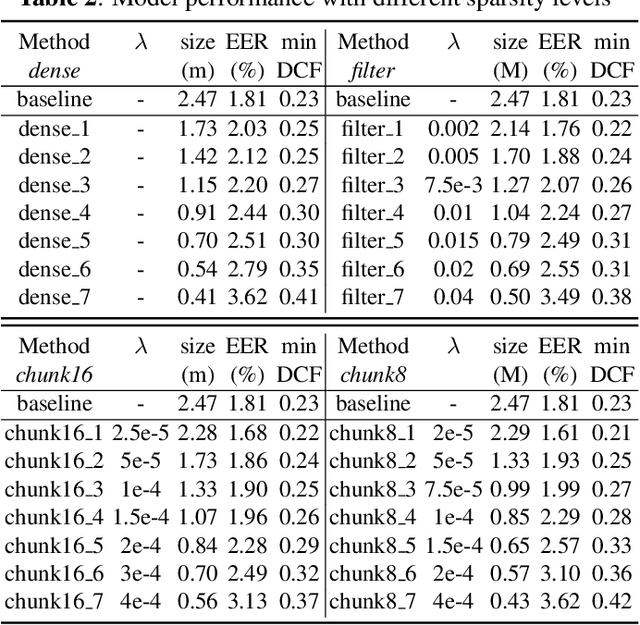
Recently, deep neural networks (DNN) have been widely used in speaker recognition area. In order to achieve fast response time and high accuracy, the requirements for hardware resources increase rapidly. However, as the speaker recognition application is often implemented on mobile devices, it is necessary to maintain a low computational cost while keeping high accuracy in far-field condition. In this paper, we apply structural sparsification on time-delay neural networks (TDNN) to remove redundant structures and accelerate the execution. On our targeted hardware, our model can remove 60% of parameters and only slightly increasing equal error rate (EER) by 0.18% while our structural sparse model can achieve more than 2x speedup.