 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Video Coding Method Based on Neural Network for CLIC2024
Jan 08, 2024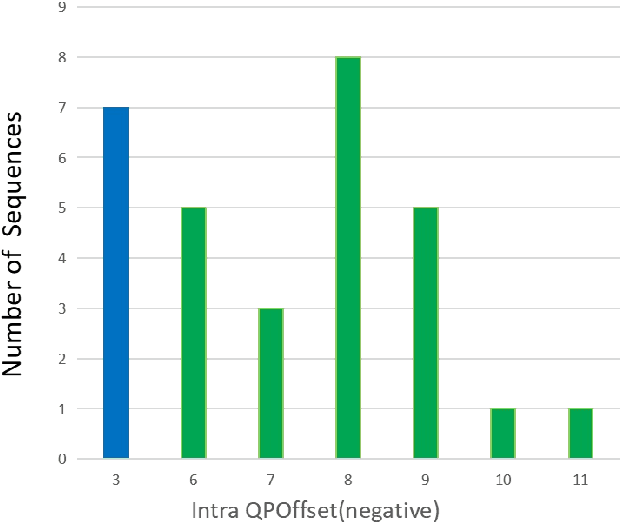

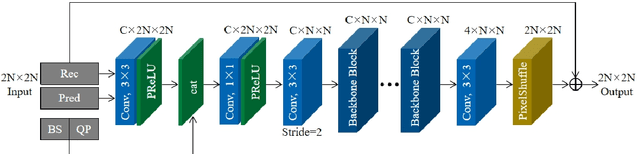
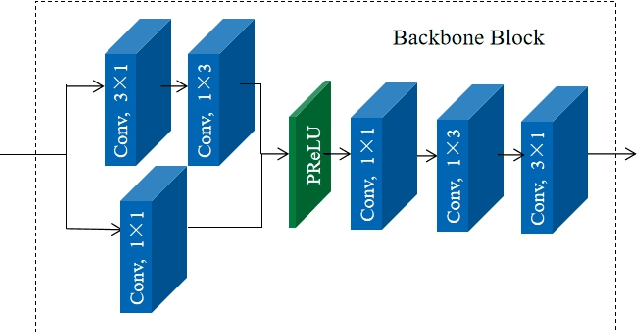
This paper presents a video coding scheme that combines traditional optimization methods with deep learning methods based on the Enhanced Compression Model (ECM). In this paper, the traditional optimization methods adaptively adjust the quantization parameter (QP). The key frame QP offset is set according to the video content characteristics, and the coding tree unit (CTU) level QP of all frames is also adjusted according to the spatial-temporal perception information. Block importance mapping technology (BIM) is also introduced, which adjusts the QP according to the block importance. Meanwhile, the deep learning methods propose a convolutional neural network-based loop filter (CNNLF), which is turned on/off based on the rate-distortion optimization at the CTU and frame level. Besides, intra-prediction using neural networks (NN-intra) is proposed to further improve compression quality, where 8 neural networks are used for predicting blocks of different sizes. The experimental results show that compared with ECM-3.0, the proposed traditional methods and adding deep learning methods improve the PSNR by 0.54 dB and 1 dB at 0.05Mbps, respectively; 0.38 dB and 0.71dB at 0.5 Mbps, respectively, which proves the superiority of our method.
HCE: Improving Performance and Efficiency with Heterogeneously Compressed Neural Network Ensemble
Jan 18, 2023Ensemble learning has gain attention in resent deep learning research as a way to further boost the accuracy and generalizability of deep neural network (DNN) models. Recent ensemble training method explores different training algorithms or settings on multiple sub-models with the same model architecture, which lead to significant burden on memory and computation cost of the ensemble model. Meanwhile, the heurtsically induced diversity may not lead to significant performance gain. We propose a new prespective on exploring the intrinsic diversity within a model architecture to build efficient DNN ensemble. We make an intriguing observation that pruning and quantization, while both leading to efficient model architecture at the cost of small accuracy drop, leads to distinct behavior in the decision boundary. To this end, we propose Heterogeneously Compressed Ensemble (HCE), where we build an efficient ensemble with the pruned and quantized variants from a pretrained DNN model. An diversity-aware training objective is proposed to further boost the performance of the HCE ensemble. Experiemnt result shows that HCE achieves significant improvement in the efficiency-accuracy tradeoff comparing to both traditional DNN ensemble training methods and previous model compression methods.
Structural sparsification for Far-field Speaker Recognition with GNA
Oct 25, 2019
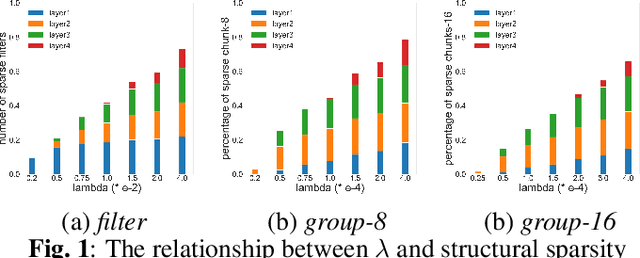
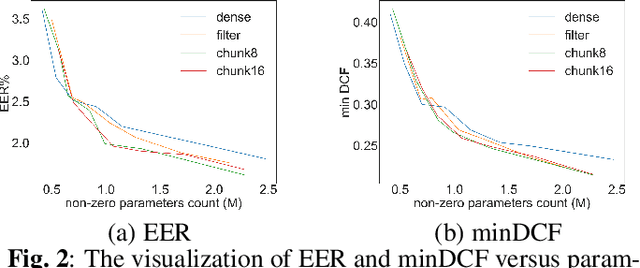
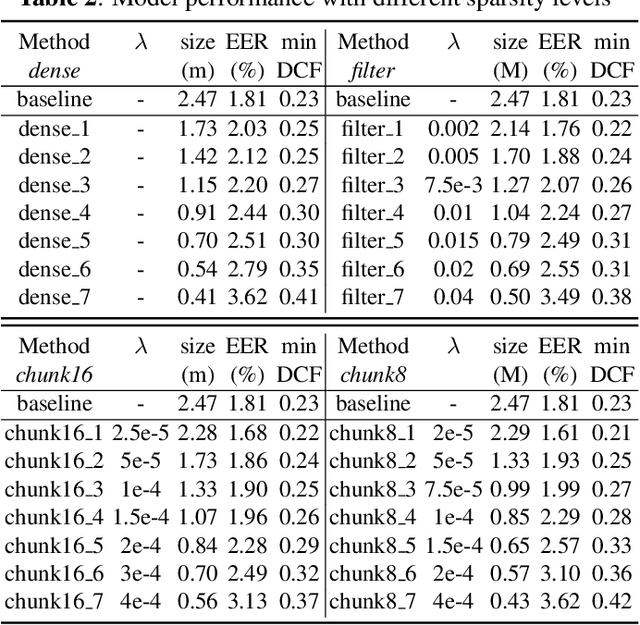
Recently, deep neural networks (DNN) have been widely used in speaker recognition area. In order to achieve fast response time and high accuracy, the requirements for hardware resources increase rapidly. However, as the speaker recognition application is often implemented on mobile devices, it is necessary to maintain a low computational cost while keeping high accuracy in far-field condition. In this paper, we apply structural sparsification on time-delay neural networks (TDNN) to remove redundant structures and accelerate the execution. On our targeted hardware, our model can remove 60% of parameters and only slightly increasing equal error rate (EER) by 0.18% while our structural sparse model can achieve more than 2x speedup.
Low-Power Computer Vision: Status, Challenges, Opportunities
Apr 15, 2019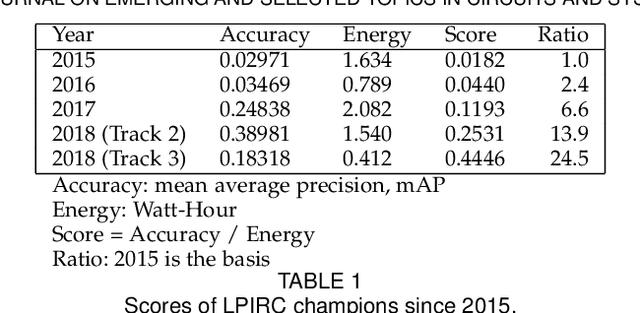
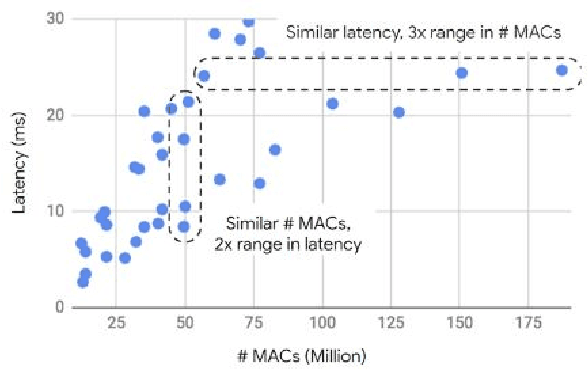
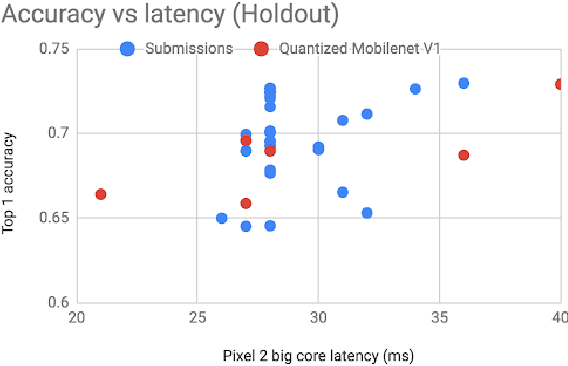
Computer vision has achieved impressive progress in recent years. Meanwhile, mobile phones have become the primary computing platforms for millions of people. In addition to mobile phones, many autonomous systems rely on visual data for making decisions and some of these systems have limited energy (such as unmanned aerial vehicles also called drones and mobile robots). These systems rely on batteries and energy efficiency is critical. This article serves two main purposes: (1) Examine the state-of-the-art for low-power solutions to detect objects in images. Since 2015, the IEEE Annual International Low-Power Image Recognition Challenge (LPIRC) has been held to identify the most energy-efficient computer vision solutions. This article summarizes 2018 winners' solutions. (2) Suggest directions for research as well as opportunities for low-power computer vision.
2018 Low-Power Image Recognition Challenge
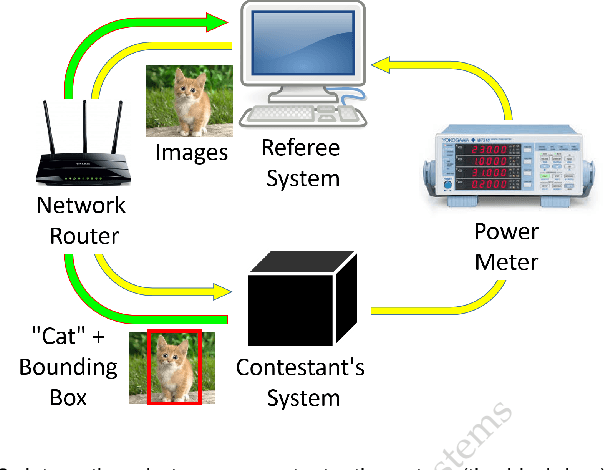
Oct 03, 2018The Low-Power Image Recognition Challenge (LPIRC, https://rebootingcomputing.ieee.org/lpirc) is an annual competition started in 2015. The competition identifies the best technologies that can classify and detect objects in images efficiently (short execution time and low energy consumption) and accurately (high precision). Over the four years, the winners' scores have improved more than 24 times. As computer vision is widely used in many battery-powered systems (such as drones and mobile phones), the need for low-power computer vision will become increasingly important. This paper summarizes LPIRC 2018 by describing the three different tracks and the winners' solutions.