 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression of end-to-end non-autoregressive image-to-speech system for low-resourced devices
Paper and Code
Nov 30, 2023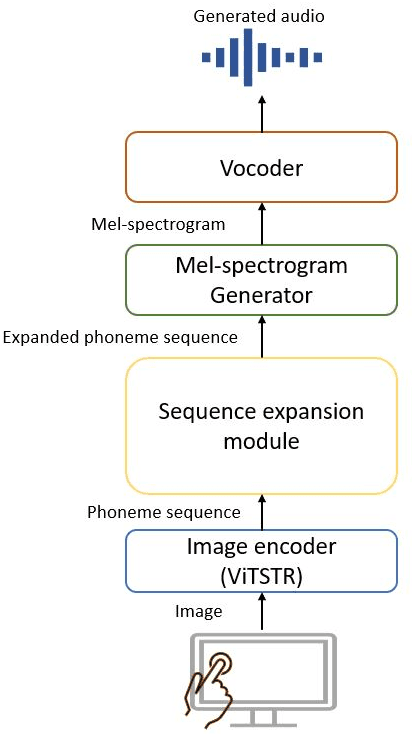

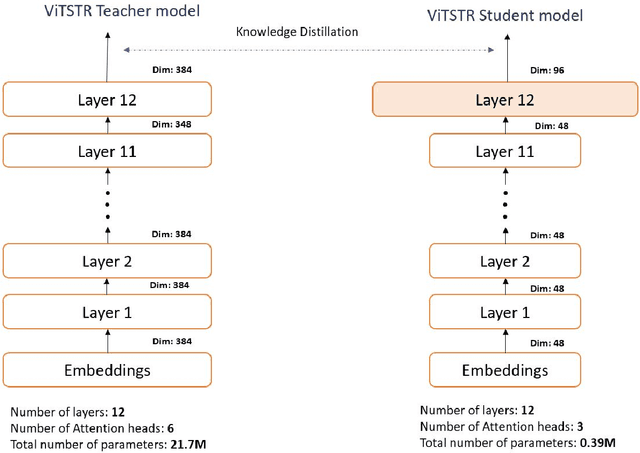
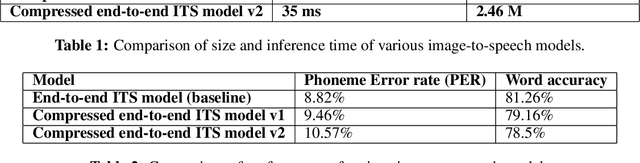
People with visual impairments have difficulty accessing touchscreen-enabled personal computing devices like mobile phones and laptops. The image-to-speech (ITS) systems can assist them in mitigating this problem, but their huge model size makes it extremely hard to be deployed on low-resourced embedded devices. In this paper, we aim to overcome this challenge by developing an efficient endto-end neural architecture for generating audio from tiny segments of display content on low-resource devices. We introduced a vision transformers-based image encoder and utilized knowledge distillation to compress the model from 6.1 million to 2.46 million parameters. Human and automatic evaluation results show that our approach leads to a very minimal drop in performance and can speed up the inference time by 22%.