 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Knowledge Tracing performance on synthesised student data
Jan 30, 2024



Knowledge Tracing (KT) aims to predict the future performance of students by tracking the development of their knowledge states. Despite all the recent progress made in this field, the application of KT models in education systems is still restricted from the data perspectives: 1) limited access to real life data due to data protection concerns, 2) lack of diversity in public datasets, 3) noises in benchmark datasets such as duplicate records. To resolve these problems, we simulated student data with three statistical strategies based on public datasets and tested their performance on two KT baselines. While we observe only minor performance improvement with additional synthetic data, our work shows that using only synthetic data for training can lead to similar performance as real data.
Measuring Sentiment Bias in Machine Translation
Jun 12, 2023

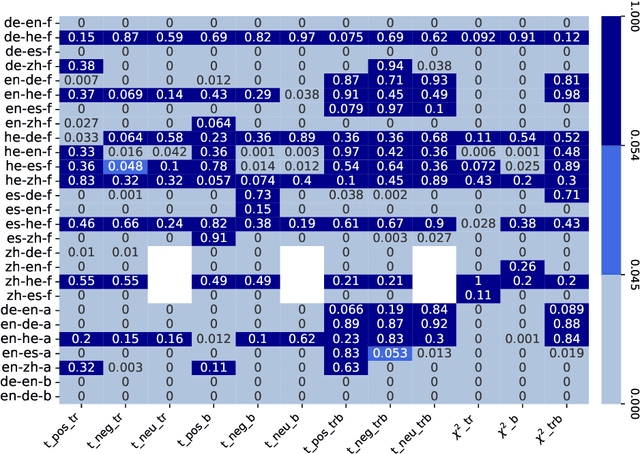

Biases induced to text by generative models have become an increasingly large topic in recent years. In this paper we explore how machine translation might introduce a bias in sentiments as classified by sentiment analysis models. For this, we compare three open access machine translation models for five different languages on two parallel corpora to test if the translation process causes a shift in sentiment classes recognized in the texts. Though our statistic test indicate shifts in the label probability distributions, we find none that appears consistent enough to assume a bias induced by the translation process.