 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting within and across language phoneme recognition performance of self-supervised learning speech pre-trained models
Paper and Code
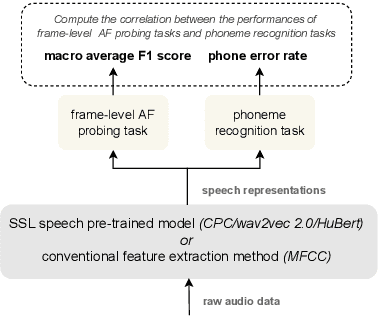
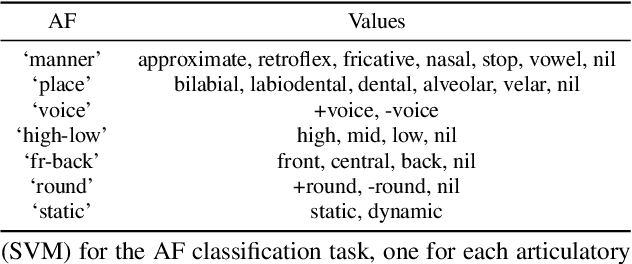
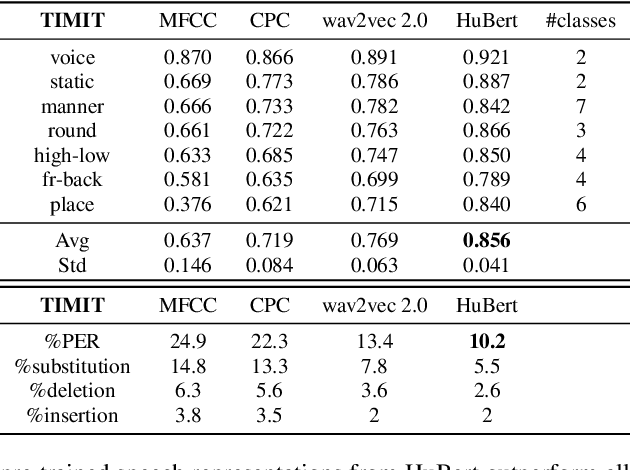
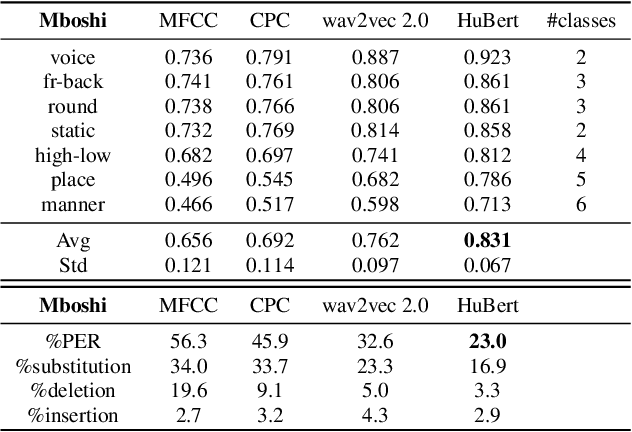
In this work, we analyzed and compared speech representations extracted from different frozen self-supervised learning (SSL) speech pre-trained models on their ability to capture articulatory features (AF) information and their subsequent prediction of phone recognition performance for within and across language scenarios. Specifically, we compared CPC, wav2vec 2.0, and HuBert. First, frame-level AF probing tasks were implemented. Subsequently, phone-level end-to-end ASR systems for phoneme recognition tasks were implemented, and the performance on the frame-level AF probing task and the phone accuracy were correlated. Compared to the conventional speech representation MFCC, all SSL pre-trained speech representations captured more AF information, and achieved better phoneme recognition performance within and across languages, with HuBert performing best. The frame-level AF probing task is a good predictor of phoneme recognition performance, showing the importance of capturing AF information in the speech representations. Compared with MFCC, in the within-language scenario, the performance of these SSL speech pre-trained models on AF probing tasks achieved a maximum relative increase of 34.4%, and it resulted in the lowest PER of 10.2%. In the cross-language scenario, the maximum relative increase of 26.7% also resulted in the lowest PER of 23.0%.