 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving child speech recognition with augmented child-like speech
Paper and Code
Jun 12, 2024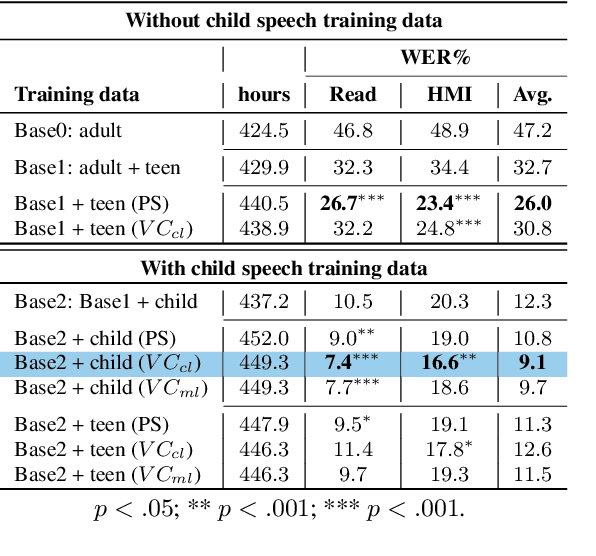
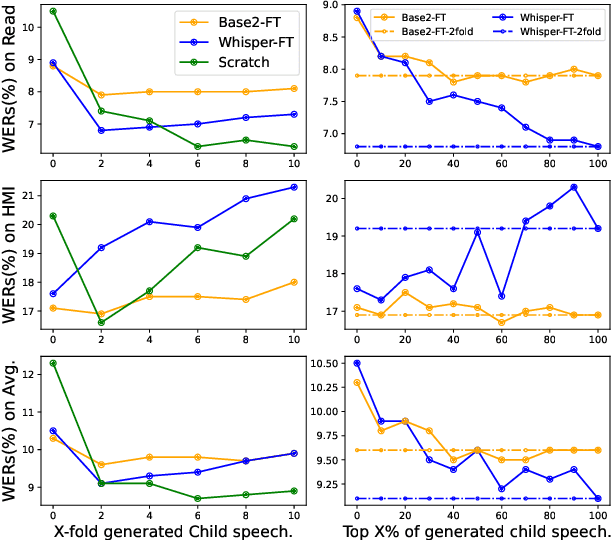
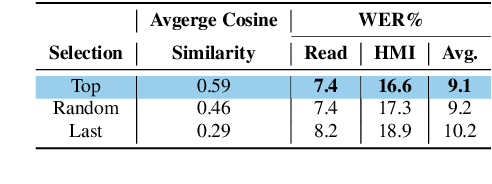
State-of-the-art ASRs show suboptimal performance for child speech. The scarcity of child speech limits the development of child speech recognition (CSR). Therefore, we studied child-to-child voice conversion (VC) from existing child speakers in the dataset and additional (new) child speakers via monolingual and cross-lingual (Dutch-to-German) VC, respectively. The results showed that cross-lingual child-to-child VC significantly improved child ASR performance. Experiments on the impact of the quantity of child-to-child cross-lingual VC-generated data on fine-tuning (FT) ASR models gave the best results with two-fold augmentation for our FT-Conformer model and FT-Whisper model which reduced WERs with ~3% absolute compared to the baseline, and with six-fold augmentation for the model trained from scratch, which improved by an absolute 3.6% WER. Moreover, using a small amount of "high-quality" VC-generated data achieved similar results to those of our best-FT models.