 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinaural Localization Model for Speech in Noise
Jul 26, 2025
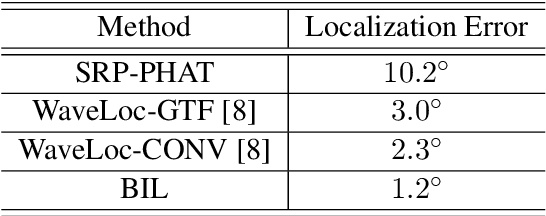
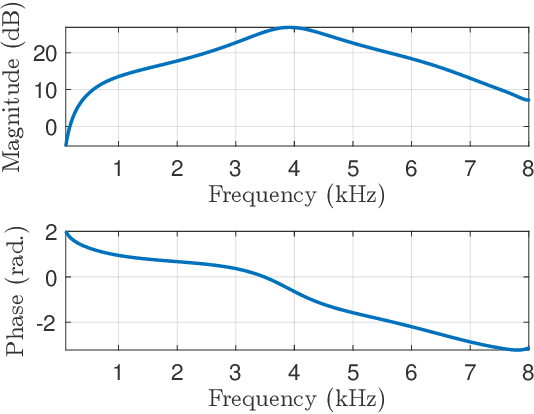
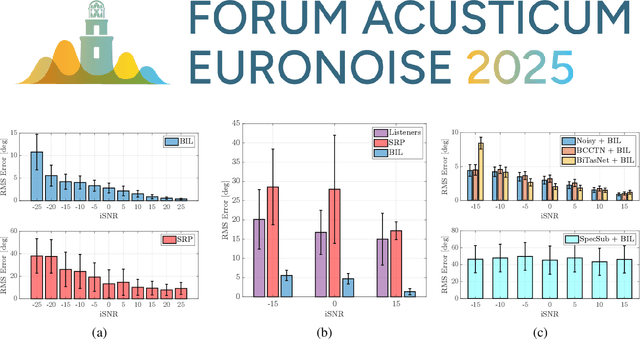
Binaural acoustic source localization is important to human listeners for spatial awareness, communication and safety. In this paper, an end-to-end binaural localization model for speech in noise is presented. A lightweight convolutional recurrent network that localizes sound in the frontal azimuthal plane for noisy reverberant binaural signals is introduced. The model incorporates additive internal ear noise to represent the frequency-dependent hearing threshold of a typical listener. The localization performance of the model is compared with the steered response power algorithm, and the use of the model as a measure of interaural cue preservation for binaural speech enhancement methods is studied. A listening test was performed to compare the performance of the model with human localization of speech in noisy conditions.
Binaural Speech Enhancement Using Deep Complex Convolutional Transformer Networks
Mar 08, 2024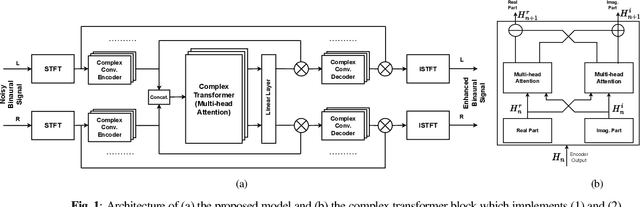
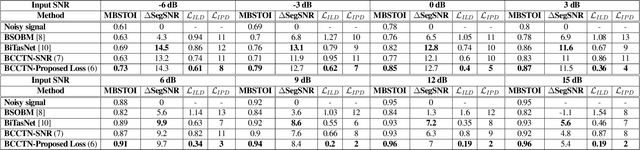
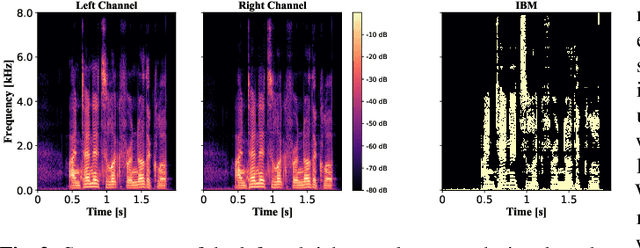
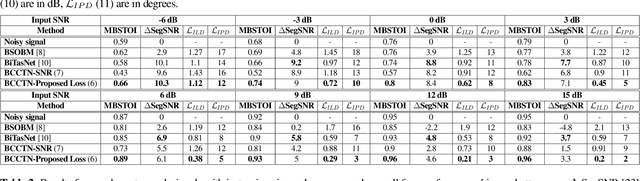
Studies have shown that in noisy acoustic environments, providing binaural signals to the user of an assistive listening device may improve speech intelligibility and spatial awareness. This paper presents a binaural speech enhancement method using a complex convolutional neural network with an encoder-decoder architecture and a complex multi-head attention transformer. The model is trained to estimate individual complex ratio masks in the time-frequency domain for the left and right-ear channels of binaural hearing devices. The model is trained using a novel loss function that incorporates the preservation of spatial information along with speech intelligibility improvement and noise reduction. Simulation results for acoustic scenarios with a single target speaker and isotropic noise of various types show that the proposed method improves the estimated binaural speech intelligibility and preserves the binaural cues better in comparison with several baseline algorithms.
Binaural Speech Enhancement Using STOI-Optimal Masks
Sep 30, 2022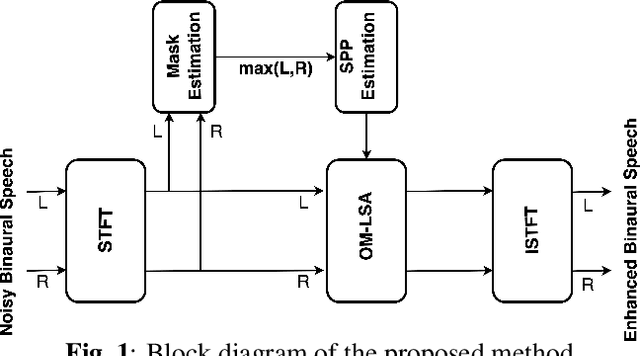

STOI-optimal masking has been previously proposed and developed for single-channel speech enhancement. In this paper, we consider the extension to the task of binaural speech enhancement in which spatial information is known to be important to speech understanding and therefore should be preserved by the enhancement processing. Masks are estimated for each of the binaural channels individually and a `better-ear listening' mask is computed by choosing the maximum of the two masks. The estimated mask is used to supply probability information about the speech presence in each time-frequency bin to an Optimally-modified Log Spectral Amplitude (OM-LSA) enhancer. We show that using the proposed method for binaural signals with a directional noise not only improves the SNR of the noisy signal but also preserves the binaural cues and intelligibility.