 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Networks Hear You Loud And Clear: Hearing Loss Compensation Using Deep Neural Networks
Mar 15, 2024



This article investigates the use of deep neural networks (DNNs) for hearing-loss compensation. Hearing loss is a prevalent issue affecting millions of people worldwide, and conventional hearing aids have limitations in providing satisfactory compensation. DNNs have shown remarkable performance in various auditory tasks, including speech recognition, speaker identification, and music classification. In this study, we propose a DNN-based approach for hearing-loss compensation, which is trained on the outputs of hearing-impaired and normal-hearing DNN-based auditory models in response to speech signals. First, we introduce a framework for emulating auditory models using DNNs, focusing on an auditory-nerve model in the auditory pathway. We propose a linearization of the DNN-based approach, which we use to analyze the DNN-based hearing-loss compensation. Additionally we develop a simple approach to choose the acoustic center frequencies of the auditory model used for the compensation strategy. Finally, we evaluate the DNN-based hearing-loss compensation strategies using listening tests with hearing impaired listeners. The results demonstrate that the proposed approach results in feasible hearing-loss compensation strategies. Our proposed approach was shown to provide an increase in speech intelligibility and was found to outperform a conventional approach in terms of perceived speech quality.
How to train your ears: Auditory-model emulation for large-dynamic-range inputs and mild-to-severe hearing losses
Mar 15, 2024



Advanced auditory models are useful in designing signal-processing algorithms for hearing-loss compensation or speech enhancement. Such auditory models provide rich and detailed descriptions of the auditory pathway, and might allow for individualization of signal-processing strategies, based on physiological measurements. However, these auditory models are often computationally demanding, requiring significant time to compute. To address this issue, previous studies have explored the use of deep neural networks to emulate auditory models and reduce inference time. While these deep neural networks offer impressive efficiency gains in terms of computational time, they may suffer from uneven emulation performance as a function of auditory-model frequency-channels and input sound pressure level, making them unsuitable for many tasks. In this study, we demonstrate that the conventional machine-learning optimization objective used in existing state-of-the-art methods is the primary source of this limitation. Specifically, the optimization objective fails to account for the frequency- and level-dependencies of the auditory model, caused by a large input dynamic range and different types of hearing losses emulated by the auditory model. To overcome this limitation, we propose a new optimization objective that explicitly embeds the frequency- and level-dependencies of the auditory model. Our results show that this new optimization objective significantly improves the emulation performance of deep neural networks across relevant input sound levels and auditory-model frequency channels, without increasing the computational load during inference. Addressing these limitations is essential for advancing the application of auditory models in signal-processing tasks, ensuring their efficacy in diverse scenarios.
Dynamic Processing Neural Network Architecture For Hearing Loss Compensation
Oct 25, 2023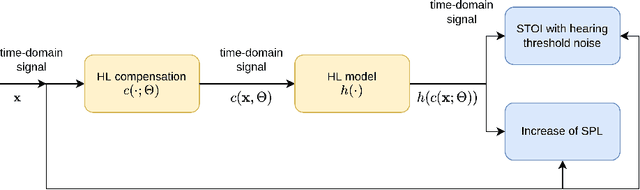
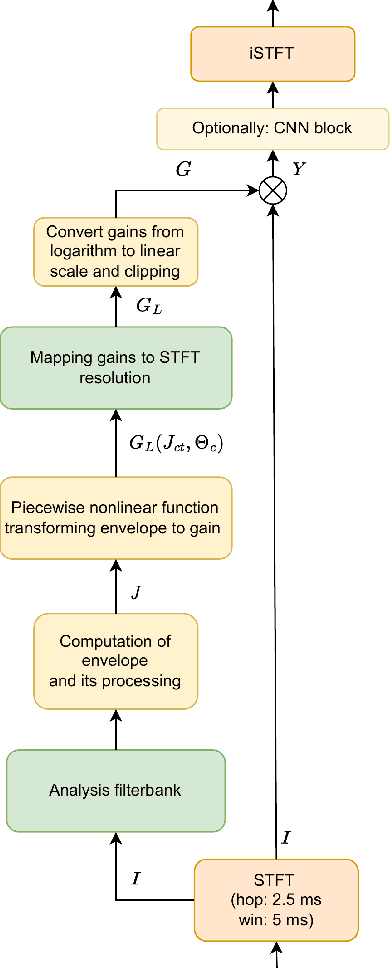
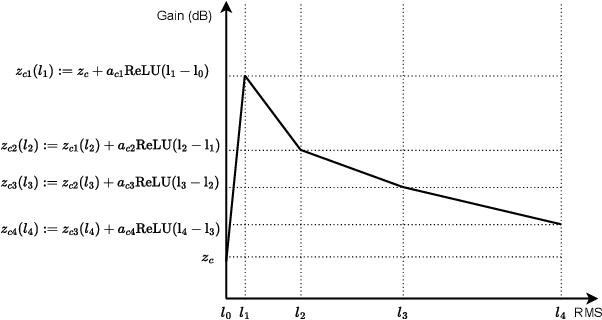
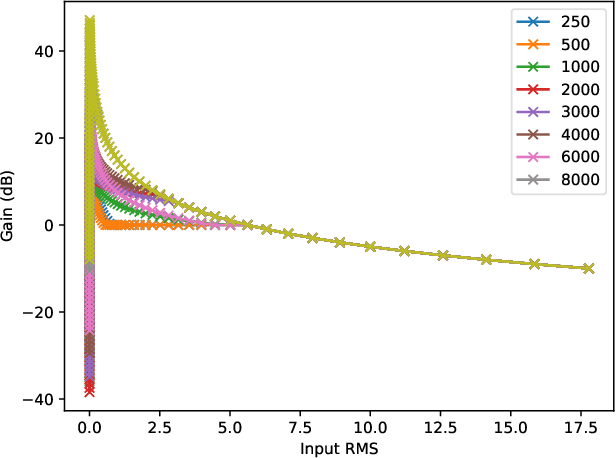
This paper proposes neural networks for compensating sensorineural hearing loss. The aim of the hearing loss compensation task is to transform a speech signal to increase speech intelligibility after further processing by a person with a hearing impairment, which is modeled by a hearing loss model. We propose an interpretable model called dynamic processing network, which has a structure similar to band-wise dynamic compressor. The network is differentiable, and therefore allows to learn its parameters to maximize speech intelligibility. More generic models based on convolutional layers were tested as well. The performance of the tested architectures was assessed using spectro-temporal objective index (STOI) with hearing-threshold noise and hearing aid speech intelligibility (HASPI) metrics. The dynamic processing network gave a significant improvement of STOI and HASPI in comparison to popular compressive gain prescription rule Camfit. A large enough convolutional network could outperform the interpretable model with the cost of larger computational load. Finally, a combination of the dynamic processing network with convolutional neural network gave the best results in terms of STOI and HASPI.