 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Processing Neural Network Architecture For Hearing Loss Compensation
Oct 25, 2023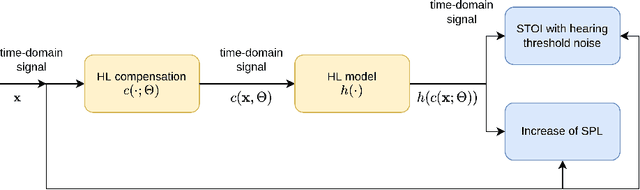
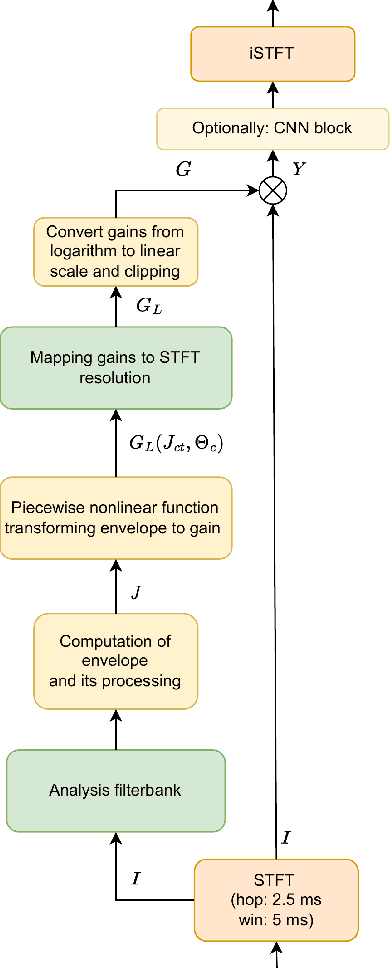
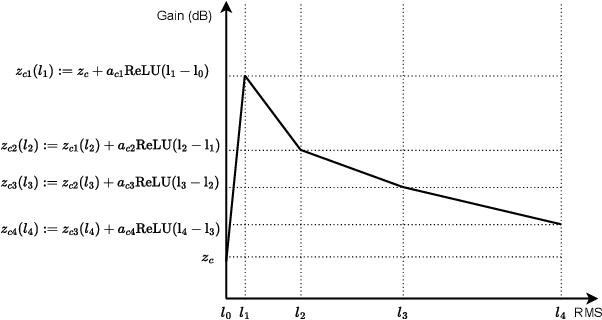
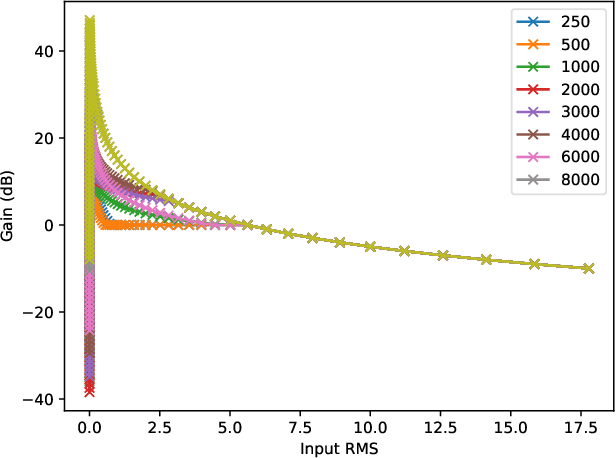
This paper proposes neural networks for compensating sensorineural hearing loss. The aim of the hearing loss compensation task is to transform a speech signal to increase speech intelligibility after further processing by a person with a hearing impairment, which is modeled by a hearing loss model. We propose an interpretable model called dynamic processing network, which has a structure similar to band-wise dynamic compressor. The network is differentiable, and therefore allows to learn its parameters to maximize speech intelligibility. More generic models based on convolutional layers were tested as well. The performance of the tested architectures was assessed using spectro-temporal objective index (STOI) with hearing-threshold noise and hearing aid speech intelligibility (HASPI) metrics. The dynamic processing network gave a significant improvement of STOI and HASPI in comparison to popular compressive gain prescription rule Camfit. A large enough convolutional network could outperform the interpretable model with the cost of larger computational load. Finally, a combination of the dynamic processing network with convolutional neural network gave the best results in terms of STOI and HASPI.
Subjective Evaluation of Deep Neural Network Based Speech Enhancement Systems in Real-World Conditions
Aug 14, 2022
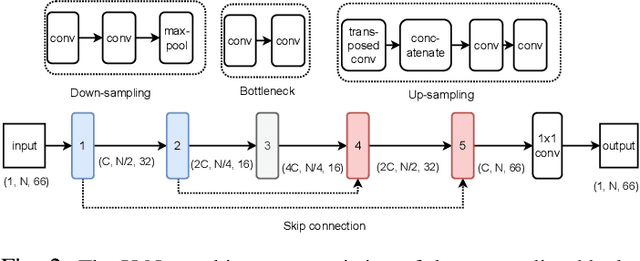
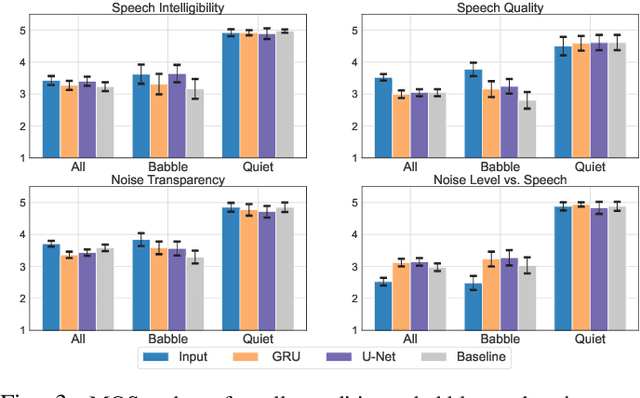
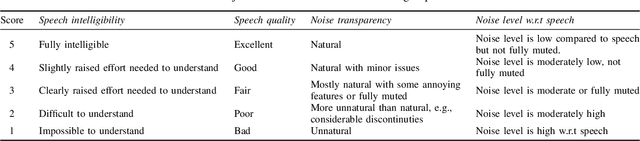
Subjective evaluation results for two low-latency deep neural networks (DNN) are compared to a matured version of a traditional Wiener-filter based noise suppressor. The target use-case is real-world single-channel speech enhancement applications, e.g., communications. Real-world recordings consisting of additive stationary and non-stationary noise types are included. The evaluation is divided into four outcomes: speech quality, noise transparency, speech intelligibility or listening effort, and noise level w.r.t. speech. It is shown that DNNs improve noise suppression in all conditions in comparison to the traditional Wiener-filter baseline without major degradation in speech quality and noise transparency while maintaining speech intelligibility better than the baseline.
Deep neural network Based Low-latency Speech Separation with Asymmetric analysis-Synthesis Window Pair
Jun 22, 2021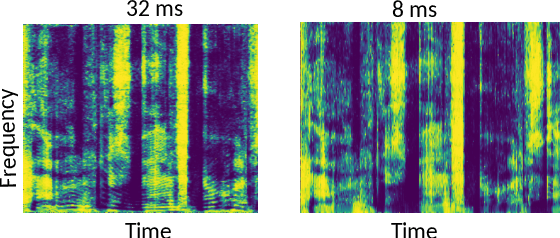
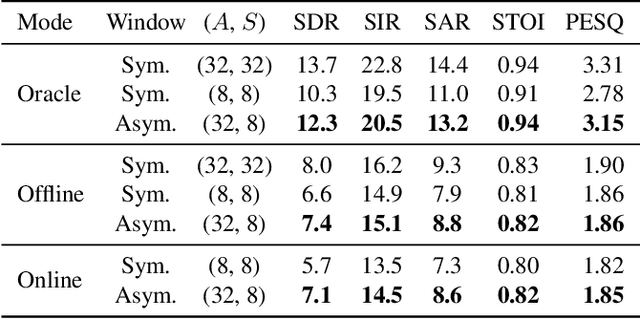
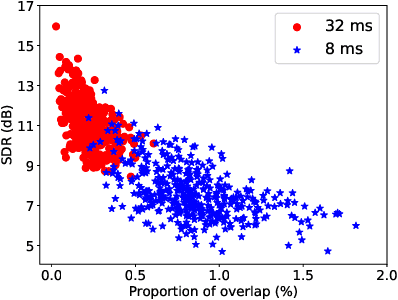
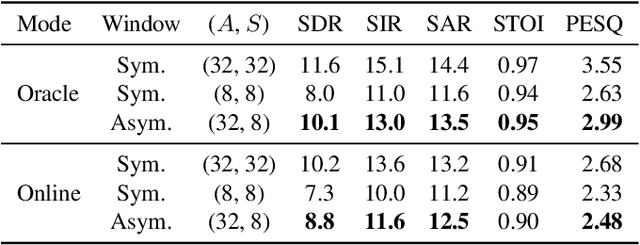
Time-frequency masking or spectrum prediction computed via short symmetric windows are commonly used in low-latency deep neural network (DNN) based source separation. In this paper, we propose the usage of an asymmetric analysis-synthesis window pair which allows for training with targets with better frequency resolution, while retaining the low-latency during inference suitable for real-time speech enhancement or assisted hearing applications. In order to assess our approach across various model types and datasets, we evaluate it with both speaker-independent deep clustering (DC) model and a speaker-dependent mask inference (MI) model. We report an improvement in separation performance of up to 1.5 dB in terms of source-to-distortion ratio (SDR) while maintaining an algorithmic latency of 8 ms.
Memory Requirement Reduction of Deep Neural Networks Using Low-bit Quantization of Parameters
Nov 01, 2019

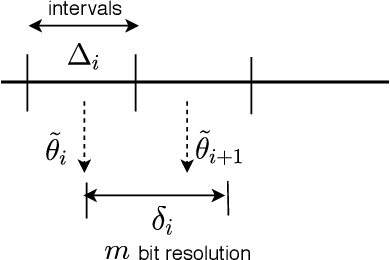
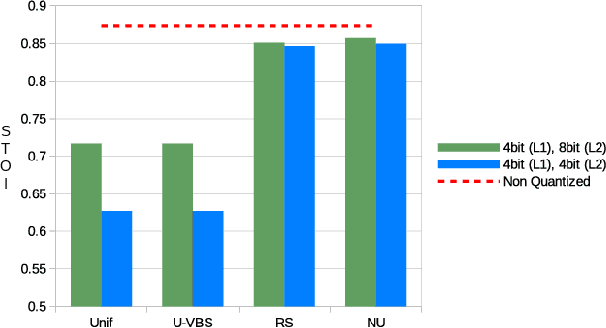
Effective employment of deep neural networks (DNNs) in mobile devices and embedded systems is hampered by requirements for memory and computational power. This paper presents a non-uniform quantization approach which allows for dynamic quantization of DNN parameters for different layers and within the same layer. A virtual bit shift (VBS) scheme is also proposed to improve the accuracy of the proposed scheme. Our method reduces the memory requirements, preserving the performance of the network. The performance of our method is validated in a speech enhancement application, where a fully connected DNN is used to predict the clean speech spectrum from the input noisy speech spectrum. A DNN is optimized and its memory footprint and performance are evaluated using the short-time objective intelligibility, STOI, metric. The application of the low-bit quantization allows a 50% reduction of the DNN memory footprint while the STOI performance drops only by 2.7%.