 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Processing Neural Network Architecture For Hearing Loss Compensation
Oct 25, 2023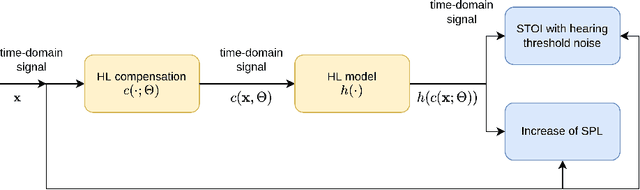
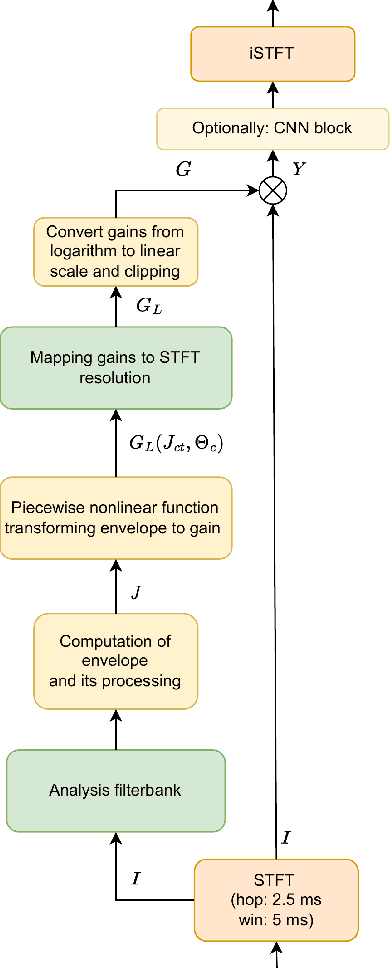
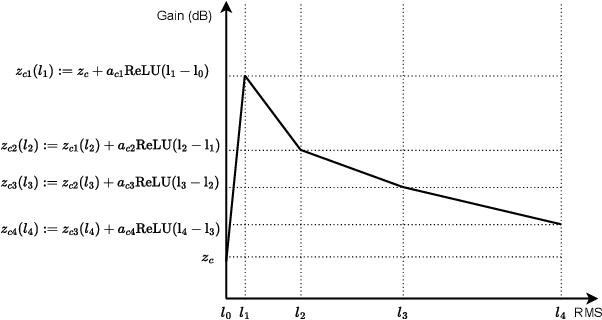
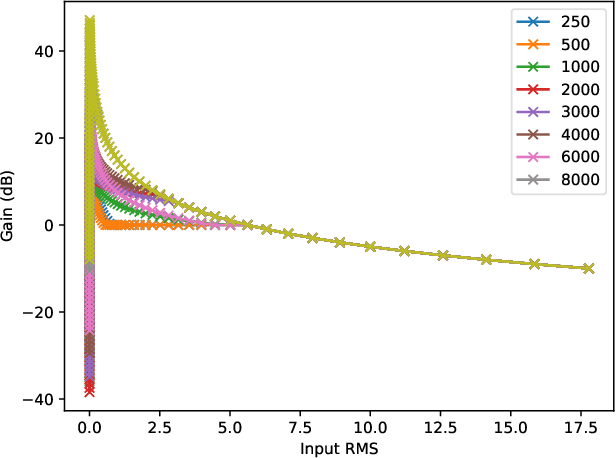
This paper proposes neural networks for compensating sensorineural hearing loss. The aim of the hearing loss compensation task is to transform a speech signal to increase speech intelligibility after further processing by a person with a hearing impairment, which is modeled by a hearing loss model. We propose an interpretable model called dynamic processing network, which has a structure similar to band-wise dynamic compressor. The network is differentiable, and therefore allows to learn its parameters to maximize speech intelligibility. More generic models based on convolutional layers were tested as well. The performance of the tested architectures was assessed using spectro-temporal objective index (STOI) with hearing-threshold noise and hearing aid speech intelligibility (HASPI) metrics. The dynamic processing network gave a significant improvement of STOI and HASPI in comparison to popular compressive gain prescription rule Camfit. A large enough convolutional network could outperform the interpretable model with the cost of larger computational load. Finally, a combination of the dynamic processing network with convolutional neural network gave the best results in terms of STOI and HASPI.
Interactive Lungs Auscultation with Reinforcement Learning Agent
Jul 25, 2019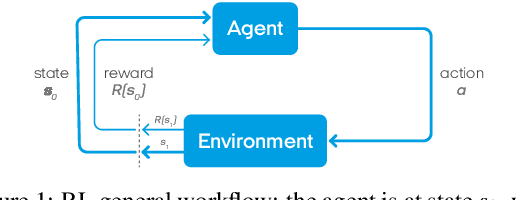



To perform a precise auscultation for the purposes of examination of respiratory system normally requires the presence of an experienced doctor. With most recent advances in machine learning and artificial intelligence, automatic detection of pathological breath phenomena in sounds recorded with stethoscope becomes a reality. But to perform a full auscultation in home environment by layman is another matter, especially if the patient is a child. In this paper we propose a unique application of Reinforcement Learning for training an agent that interactively guides the end user throughout the auscultation procedure. We show that \textit{intelligent} selection of auscultation points by the agent reduces time of the examination fourfold without significant decrease in diagnosis accuracy compared to exhaustive auscultation.
Using recurrences in time and frequency within U-net architecture for speech enhancement
Nov 16, 2018

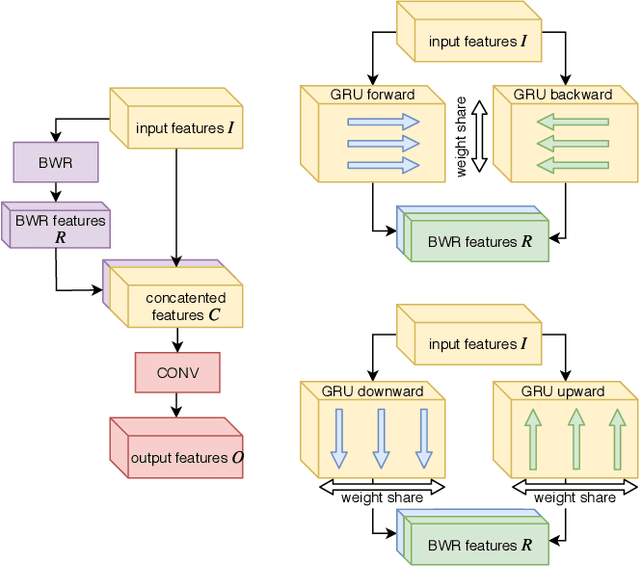
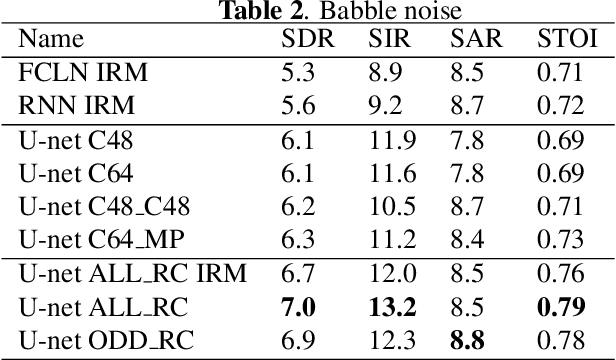
When designing fully-convolutional neural network, there is a trade-off between receptive field size, number of parameters and spatial resolution of features in deeper layers of the network. In this work we present a novel network design based on combination of many convolutional and recurrent layers that solves these dilemmas. We compare our solution with U-nets based models known from the literature and other baseline models on speech enhancement task. We test our solution on TIMIT speech utterances combined with noise segments extracted from NOISEX-92 database and show clear advantage of proposed solution in terms of SDR (signal-to-distortion ratio), SIR (signal-to-interference ratio) and STOI (spectro-temporal objective intelligibility) metrics compared to the current state-of-the-art.