 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing recurrences in time and frequency within U-net architecture for speech enhancement
Paper and Code
Nov 16, 2018

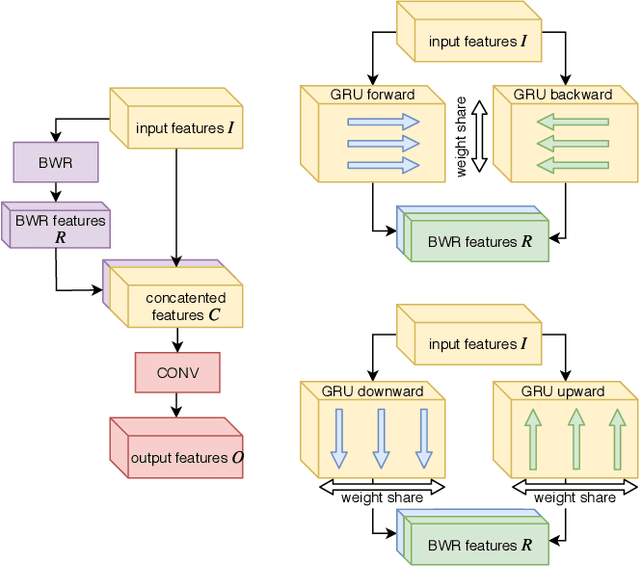
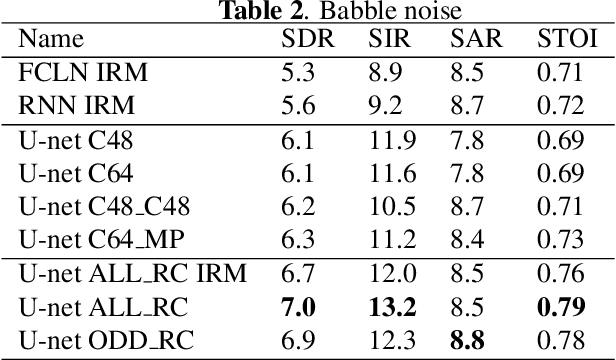
When designing fully-convolutional neural network, there is a trade-off between receptive field size, number of parameters and spatial resolution of features in deeper layers of the network. In this work we present a novel network design based on combination of many convolutional and recurrent layers that solves these dilemmas. We compare our solution with U-nets based models known from the literature and other baseline models on speech enhancement task. We test our solution on TIMIT speech utterances combined with noise segments extracted from NOISEX-92 database and show clear advantage of proposed solution in terms of SDR (signal-to-distortion ratio), SIR (signal-to-interference ratio) and STOI (spectro-temporal objective intelligibility) metrics compared to the current state-of-the-art.