 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum Processing Near-end Listening Enhancement
Oct 31, 2022The intelligibility and quality of speech from a mobile phone or public announcement system are often affected by background noise in the listening environment. By pre-processing the speech signal it is possible to improve the speech intelligibility and quality -- this is known as near-end listening enhancement (NLE). Although, existing NLE techniques are able to greatly increase intelligibility in harsh noise environments, in favorable noise conditions the intelligibility of speech reaches a ceiling where it cannot be further enhanced. Actually, the focus of existing methods solely on improving the intelligibility causes unnecessary processing of the speech signal and leads to speech distortions and quality degradations. In this paper, we provide a new rationale for NLE, where the target speech is minimally processed in terms of a processing penalty, provided that a certain performance constraint, e.g., intelligibility, is satisfied. We present a closed-form solution for the case where the performance criterion is an intelligibility estimator based on the approximated speech intelligibility index and the processing penalty is the mean-square error between the processed and the clean speech. This produces an NLE method that adapts to changing noise conditions via a simple gain rule by limiting the processing to the minimum necessary to achieve a desired intelligibility, while at the same time focusing on quality in favorable noise situations by minimizing the amount of speech distortions. Through simulation studies, we show the proposed method attains speech quality on par or better than existing methods in both objective measurements and subjective listening tests, whilst still sustaining objective speech intelligibility performance on par with existing methods.
Joint Far- and Near-End Speech Intelligibility Enhancement based on the Approximated Speech Intelligibility Index
Nov 15, 2021
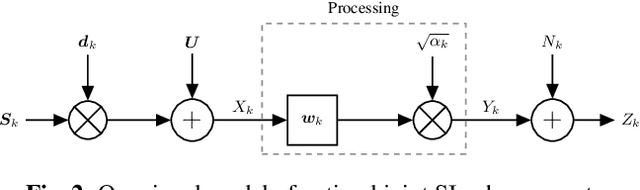
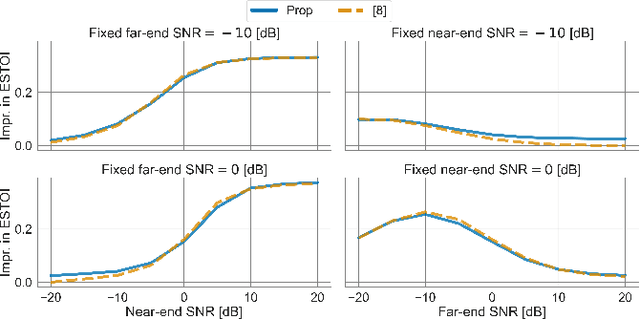
This paper considers speech enhancement of signals picked up in one noisy environment which must be presented to a listener in another noisy environment. Recently, it has been shown that an optimal solution to this problem requires the consideration of the noise sources in both environments jointly. However, the existing optimal mutual information based method requires a complicated system model that includes natural speech variations, and relies on approximations and assumptions of the underlying signal distributions. In this paper, we propose to use a simpler signal model and optimize speech intelligibility based on the Approximated Speech Intelligibility Index (ASII). We derive a closed-form solution to the joint far- and near-end speech enhancement problem that is independent of the marginal distribution of signal coefficients, and that achieves similar performance to existing work. In addition, we do not need to model or optimize for natural speech variations.